七天入门大模型第2天 :提示词工程 Prompt Engineering最全总结!
- AIGC
- 2024-05-16
- 1417热度
- 0评论
引 言
前一天我们讲到:prompt(提示词)是我们和LLM互动最常用的方式,我们提供给LLM的Prompt作为模型的输入,并希望LLM反馈我们期待的结果。
虽然LLM的功能非常强大,但LLM对提示词(prompt)也非常敏感。这使得提示词工程成为一项需要培养的重要技能。
本节课将会给大家介绍提示词设计的一些技术,涉及到一些案例实操,
推荐使用环境:https://modelscope.cn/studios/qwen/Qwen-72B-Chat-Demo
让我们从一个问题开始:
这是来自知乎的一个问题:
最近尝试部署了qwen模型,我想固定它的输出,比如说“请走向公园。这句话我的目的地是?”,然后让它回答“公园”,但是模型会回答其他无关的字,写了提示词也没有解决,这是有办法固定的吗?我在尝试用RLHF微调,不知道有没有用。
我们可以带着这个问题进入到本节课。
LLM 的超参配置
LLM提供了一些参数可以影响输出结果的创造力和确定性。
在每个步骤中,LLM 会生成一个最有可能出现的token列表以及其对应的概率列表。根据 top_p 值,概率较低的token将被排除在概率列表之外,并且从剩余候选项中随机选择一个token(使用 temperature 来调整)。
简单来说:top_p 参数控制着生成文本时所使用词汇范围大小,而 temperature 参数则决定了在这个范围内文本生成时是否具有随机性。当温度接近 0 时,则会得到几乎是确定性结果。
Prompt Engineering
提示工程(Prompt Engineering)是一项通过优化提示词(Prompt)和生成策略,从而获得更好的模型返回结果的工程技术。
总体而言,其实现逻辑如下:
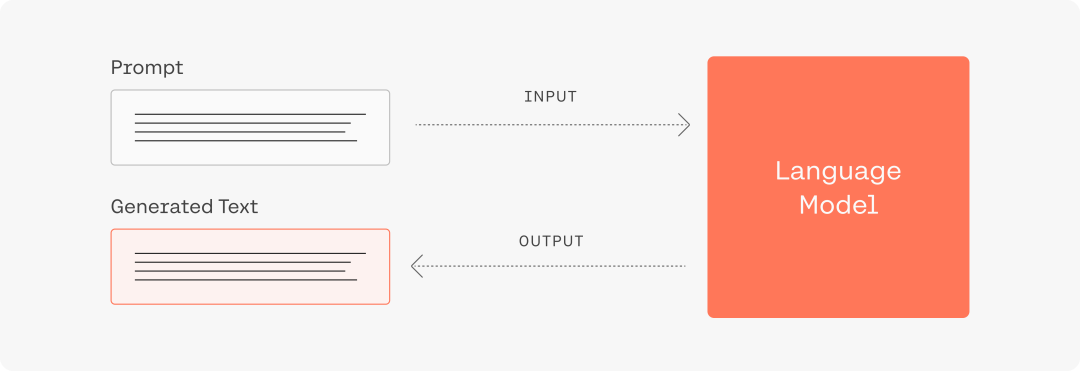
(注:示例图来自Cohere官网)
简单而言,大模型的运行机制是“下一个字词预测”。用户输入的prompt即为大模型所获得上下文,大模型将根据用户的输入进行续写,返回结果。因此,输入的prompt的质量将极大地影响模型的返回结果的质量和对用户需求的满足程度,总的原则是“用户表达的需求越清晰,模型更有可能返回更高质量的结果”。
通常情况下,每条信息都会有一个角色(role)和内容(content):
系统角色(system)用来向语言模型传达开发者定义好的核心指令。
用户角色(user)则代表着用户自己输入或者产生出来的信息。
助手角色(assistant)则是由语言模型自动生成并回复出来。
1. System message系统指令
system message系统指令为用户提供了一个易组织、上下文稳定的控制AI助手行为的方式,可以从多种角度定制属于你自己的AI助手。系统指令允许用户在一定范围内规定LLM的风格和任务,使其更具可定性和适应各种用例。大部分LLM模型的系统指令System message的权重强化高于人工输入的prompt,并在多轮对话中保持稳定,您可以使用系统消息来描述助手的个性,定义模型应该回答和不应该回答的内容,以及定义模型响应的格式。
默认的System message:You are a helpful assistant.
下面是一些system message的使用示例:

System message可以被广泛应用在:
角色扮演: 在系统指令中告诉千问你需要它扮演的角色,即可沉浸式和该角色对话交流
语言风格: 简单调整LLM的语言风格
任务设定: 比如旅行规划,小红书文案助手这样的专项任务处理
System message也可以被用于规定LLM的答复范围,并设定具体的行为。



注意:即便我们在system message里面规范了模型回答,也不能保障请求一定会满足,但是好的system message设计可以增加特定结果的可能性,以及得到LLM更加符合要求的答复。
2. 用户提示词(user prompt)
指令
指令是最常用的提示组件,主要功能是向模型说明要执行的操作。虽然概念简单,但是实践中仍然比较复杂,下面是简单和详细的一些指令例子,详细、明确的指导比模糊不清的提示能够产生更好的效果:
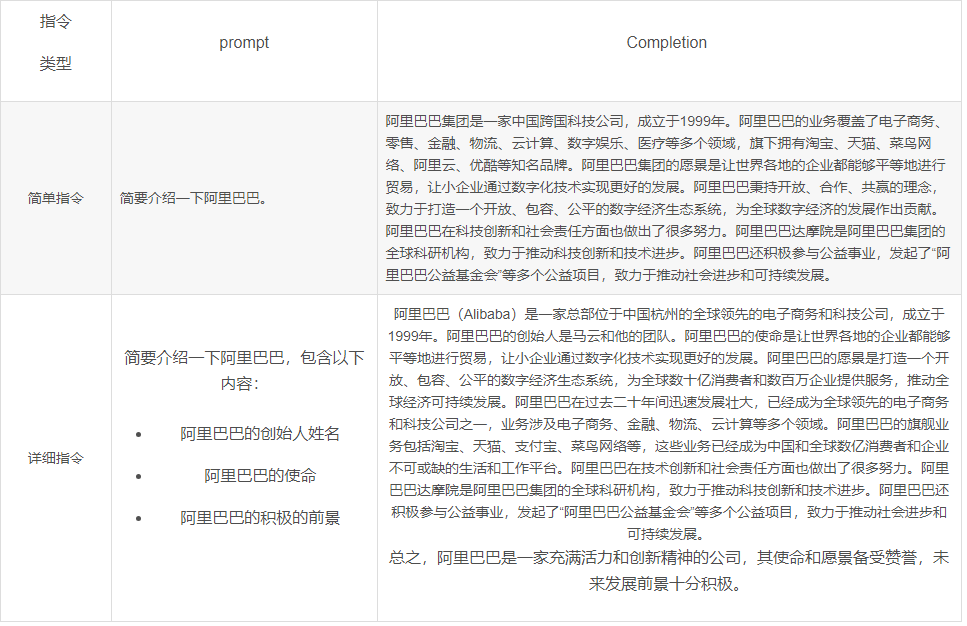
主要内容
主要内容是指模型正在处理的文本内容。 主要内容通常与指令一起使用。 下面会从翻译,摘要等场景来示例:

少样本学习
好的prompt也经常包含一些示例样本(单样本或者少样本)学习,指的是需要加入一些示例的输入和输出对。

通过少样本学习,模型从猜测应该如何生成,而变得清楚的学习了按照示例生成,充分的演示了模型的能力,不需要通过专门的训练,通过少样本学习,也可以生成正确的答案。
更加明确的提示
充当模型输出的快速启动,帮助模型固定所需要的输出。可以作为模型生成的前缀,也可以引导模型一步一步地按照要求思考并给出答案。

善用分隔符
使用清晰的提示语法(包括标点符号、标题和节标记)有助于传达意图,并且通常使输出更易于解析。
在下面的示例中,—在不同的信息源或步骤之间添加了分隔符(在本例中)。这允许使用—作为生成的停止条件。此外,章节标题或特殊变量以大写形式呈现以区分它们。
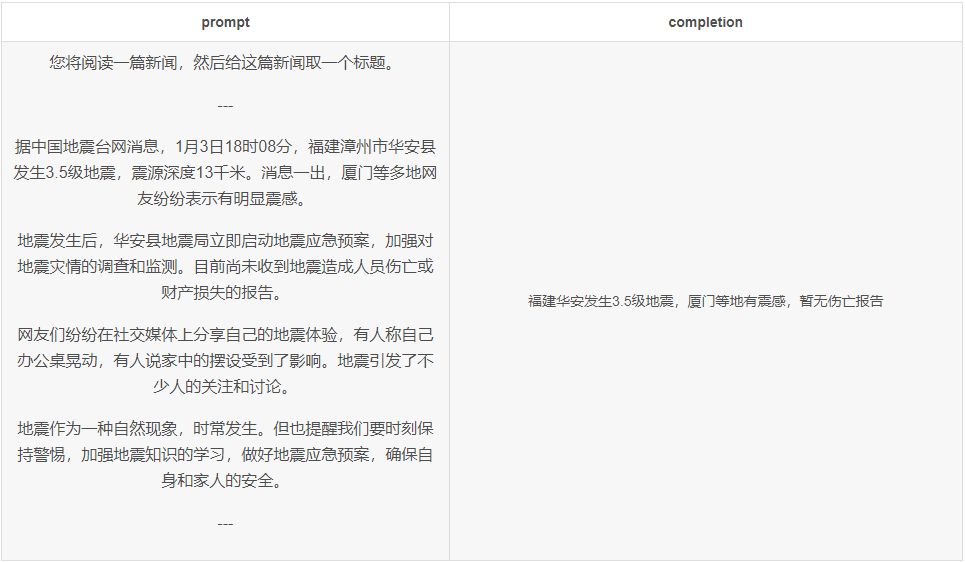
思维链提示
这是任务分解(step by step)技术的一种展现,在这种方法中,模型逐步进行思考,并呈现出涉及的步骤,这样做可以降低结果的不准确的可能性,并对模型响应的可解释性有很大的帮助。



请注意,以上只是一个示例,具体菜单内容还需根据目标客群的口味、消费水平及地域文化等因素进行调整。
对输出格式的明确要求

最佳实践案例
1. Agent场景:使用prompt实现agent create
https://github.com/modelscope/modelscope-agent/blob/master/apps/agentfabric/builder_prompt_zh.py


2. Agent场景:使用system message+prompt实现function call
大部分模型将agent的配置在系统提示中配置,比如函数的参数定义和描述,不同模型的函数调用略有不同


写好 Prompt 原则总结
最核心的写一条好prompt的原则就是尽可能清晰、明确地表达你的需求(类比产品经理向程序员提需求)。细分下来,具体原则包括:
清晰的指令:足够清晰明确地说明你希望模型为你返回什么,最后更加细致地说明需求,避免模糊表达。
提供上下文和例子:给出较为充分的上下文信息,让模型更好地理解相关背景。如果能够提供示例,模型能表现更好(类似传统LLM中的in-context learning)。
善用符号和语法:使用清晰的标点符号,标题,标记有助于转达意图,并使输出更加容易被解析
让模型一步一步地思考:在这种方法中,模型逐步进行思考,并呈现出涉及的步骤,这样做可以降低结果的不准确的可能性,并对模型响应的可解释性有很大的帮助。
激励模型反思和给出思路:可以在prompt中用一些措辞激励模型给出理由,这样有助于我们更好地分析模型生成结果,同时,思维过程的生成,也有助于其生成更高质量的结果。
给容错空间:如模型无法完成指定的任务,给模型提供一个备用路径,比如针对文本提问,可以加入如果答案不存在,则回复“无答案”
让模型给出信息来源:在模型结合搜索或者外部知识库时,要求模型提供他的答案的信息来源,可以帮助LLM的答案减少捏造,并获取到最新的信息。
优质的提示词典型框架
优质的prompt千变万化,但遵循上述原则,我们总结出一个比较实用的框架,可以帮助用户更高概率从通义千问中收获更高质量的模型生成结果。使用LLM时,建议包含如下内容:
system message: 你希望大模型扮演什么角色,来解决你当前的问题。大模型具有较强的角色扮演能力,相比直接回答往往表现更好。system message中也可以规定大模型的回答范围。
prompt
指令: 明确说明你希望大模型做什么事情,不要含糊其辞。
例子: 如果可能,提供尽可能丰富的例子信息。
原因: 详细解释你希望模型做这件事情的原因、动机、希望的结果等,这样大模型能更好地理解你的想法,执行需求。
step by step: 对于复杂任务,让大模型一步一步地思考,可以给出更加合理的答案。
对于输出格式的形容: 对于部分场景,明确大模型输出格式的要求,可以更好地获取到更加结构化,适合系统调用的答案。
课后实践
在游戏中学会prompt engineering,通关:


