评估显卡可以运行多大的模型
- AIGC
- 2024-10-12
- 1128热度
- 0评论
如何了解您的显卡可以运行多大的模型
目录索引
如何知道一个大模型在推理和训练时需要多少显存?
1 内容概要
如何知道一个大模型是否可以在自己的显卡上运行呢?
为您介绍一个模型运行时所需显存的评估工具 accelerate estimate-memory,这个工具可以帮您解决以下问题:
- 一个大模型,比如Qwen1.5-7B,需要多少GPU显存才可以推理和训练呢?
- 不同的数据类型,不同的量化,可以节省多少内存呢?
本文内容包括:
- 如何使用 accelerate estimate-memory,以及注意事项
- 计算值与实际所需值的对比实验
2 开发环境
- Transformers 4.38.1
- Accelerate 0.27.2
3 使用方法
这个工具 accelerate estimate-memory 是 huggingface 的 accelerate 开发库中提供的一个工具。使用这个工具,并不会真正的下载或者加载模型到内存中,它只是根据meta数据来对大模型所需要的内存进行模拟计算。所以,运行此工具并不需要您有GPU机器。
3.1 网页在线访问
https://huggingface.co/spaces/hf-accelerate/model-memory-usage
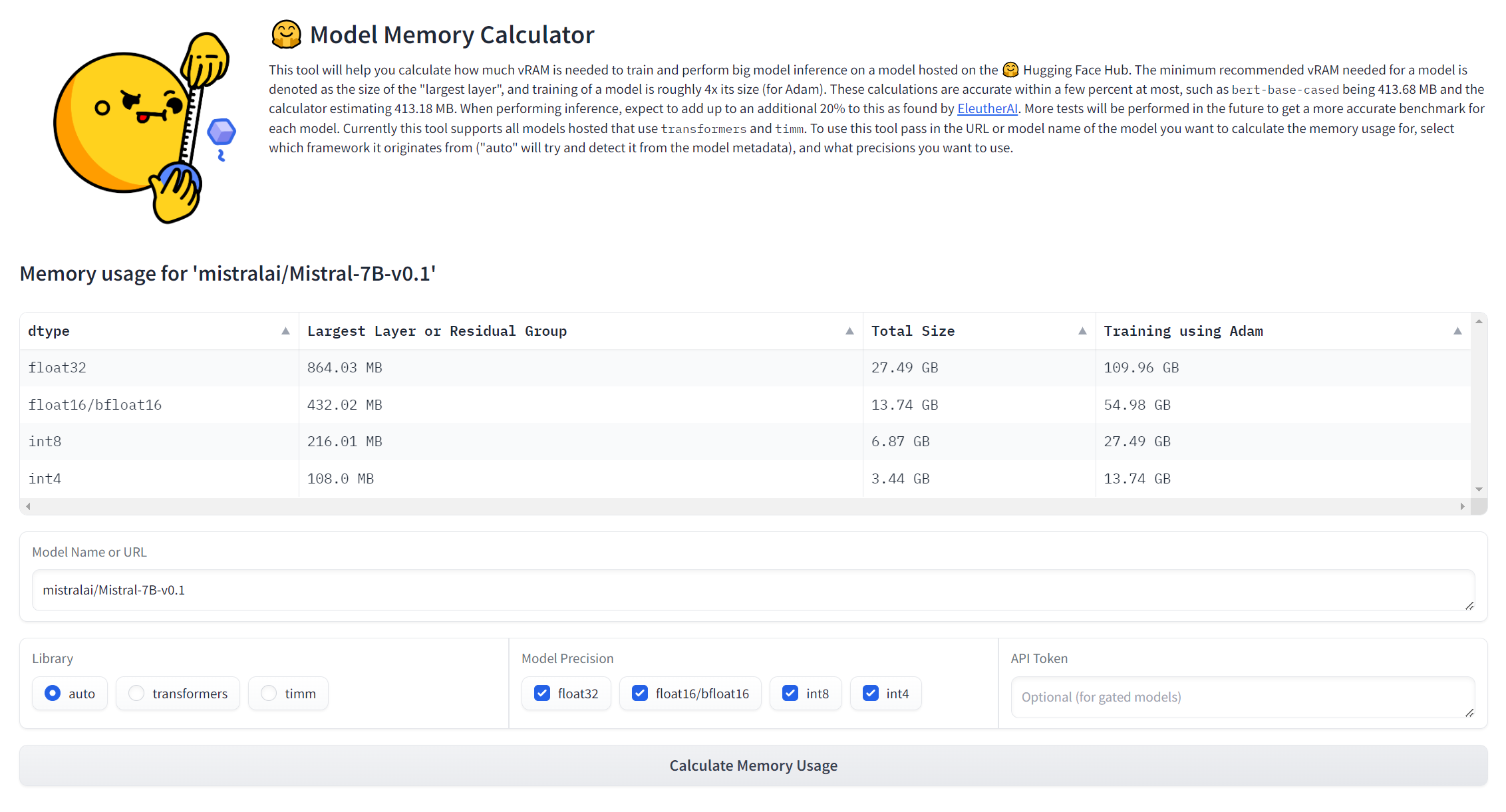
3.2 本地运行
- 安装 accelerate, transformers
pip install accelerate
pip install transformers
- 使用方法举例
# 基本使用方法
accelerate estimate-memory mistralai/Mistral-7B-v0.1
# 只显示指定的数据类型
accelerate estimate-memory mistralai/Mistral-7B-v0.1 --dtypes float16
# 指定开发库(针对本地模型,Hub上存储的模型不需要指定)
accelerate estimate-memory mistralai/Mistral-7B-v0.1 --dtypes float32 float16 --library_name transformers
# 设置 trust_remote_code=True
accelerate estimate-memory Qwen/Qwen1.5-7B #正常
accelerate estimate-memory Qwen/Qwen-7B #报错
accelerate estimate-memory Qwen/Qwen-7B --trust_remote_code #可以运行
# 其他模型
accelerate estimate-memory google/gemma-7b
accelerate estimate-memory baichuan-inc/Baichuan2-7B-Base --trust_remote_code
4 实验对比:计算值靠谱吗?
使用mistralai/Mistral-7B-v0.1模型,来做一下对比。
4.1 评价对比:mistralai/Mistral-7B-v0.1
accelerate estimate-memory mistralai/Mistral-7B-v0.1
计算的值: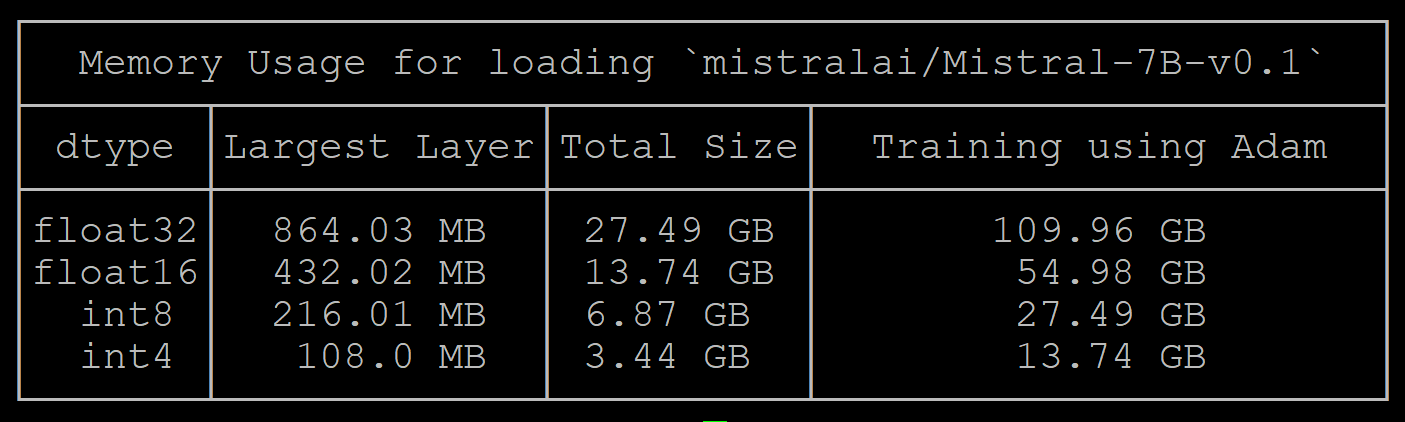
实际占用值 float32:
实际占用值 float16:
实际占用值 load_in_8bit:
实际占用值 load_in_4bit:
计算值与测量值结果:
| dtype | 计算值 | 测量值 |
|---|---|---|
| float32 | 27.49 | 30.54 |
| float16 | 13.74 | 16.25 |
| int8 | 6.87 | 10.53 |
| int4 | 3.44 | 6.94 |
测量值比计算值多约3G的显存。
4.2 测量不准确的情况
被Transformers开发库支持的模型,计算值比较稳定, 比如Misteral, Gemma,Qwen1.5等
但是,源代码没有集成进Transformers的一些模型,可能会不可靠。
比如Qwen1.5-7B模型计算值与Mistral-7B-v0.1的值相近。accelerate estimate-memory Qwen/Qwen1.5-7B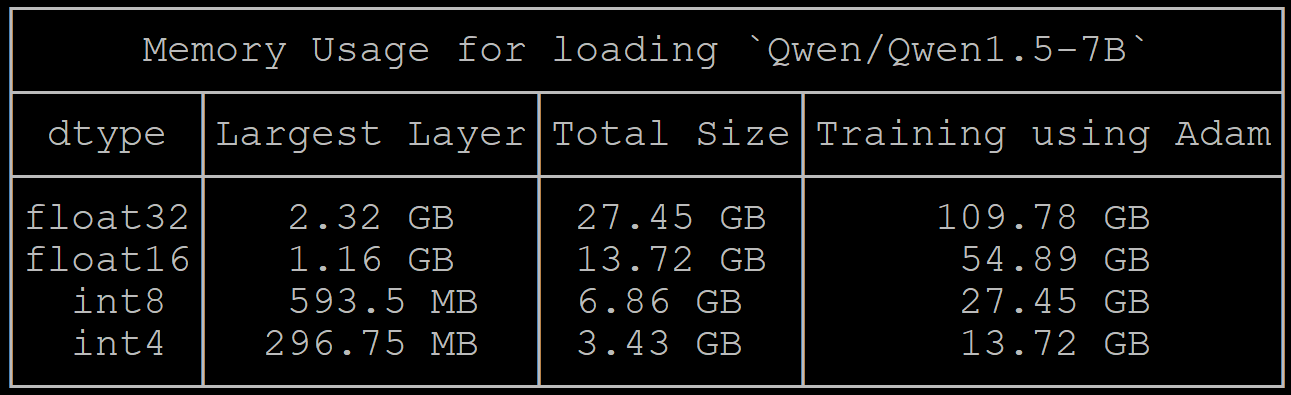
但是Qwen-7B的计算结果只有 Qwen1.5 一半:accelerate estimate-memory Qwen/Qwen-7B --trust_remote_code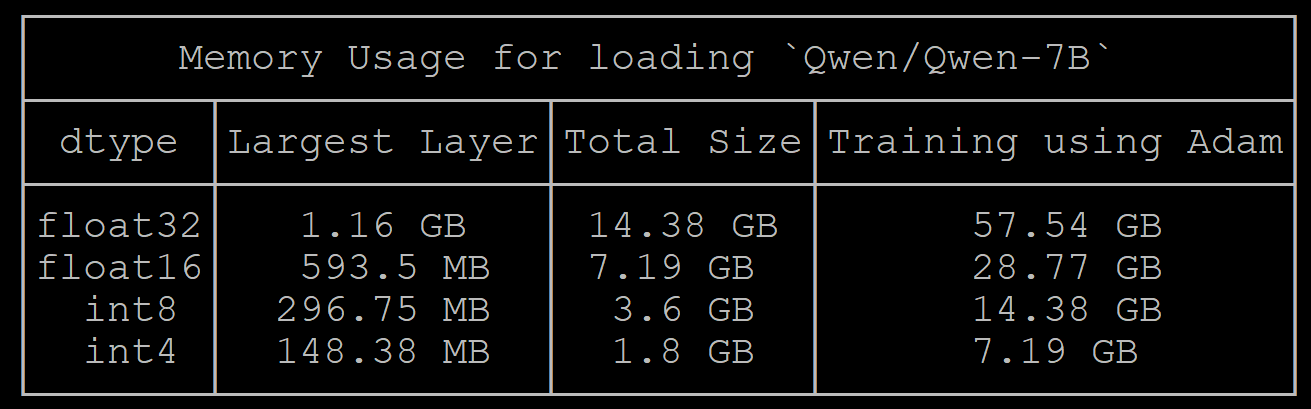
上面的结果原因是,Qwen第一版的模型在模型导入时,默认将数据格式转换为了float16。
Qwen-7B 计算值与测量值结果:
| dtype | 计算值 | 测量值 |
|---|---|---|
| float32 | 14.38 | 16.11 |
| float16 | 7.19 | 17.94 |
| int8 | 3.6 | 11.89 |
| int4 | 1.8 | 9.09 |
上面的结果,可以看出Qwen-7B的测量结果与实际的测量值差距很大。
ChatGLM模型也有类似的情况出现:accelerate estimate-memory THUDM/chatglm3-6b --trust_remote_code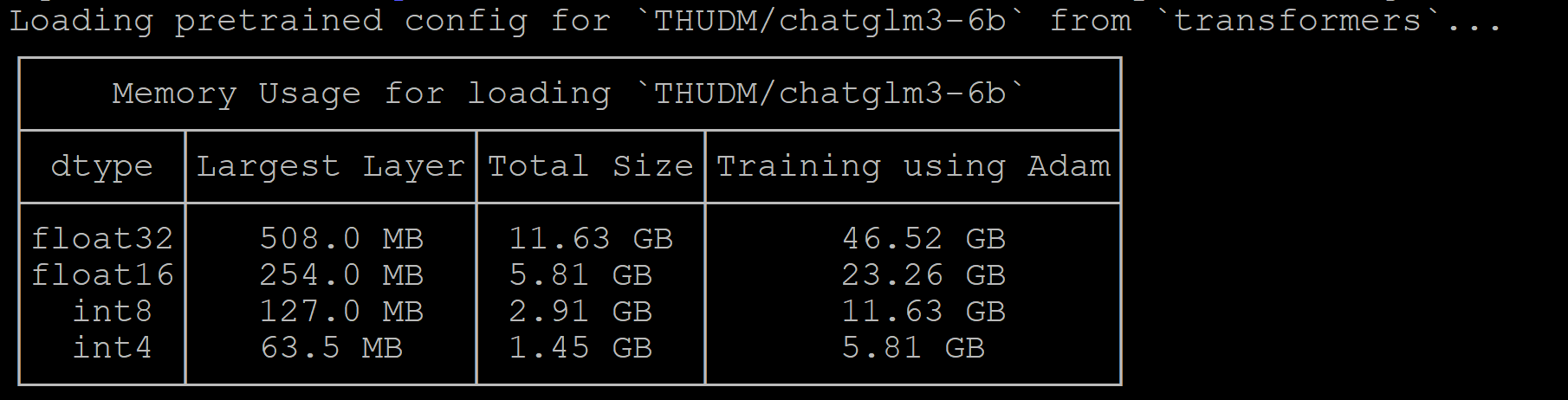
测试使用的代码:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch, pdb
model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2", torch_dtype=torch.float32, device_map="auto")
#model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2", torch_dtype=torch.float16, device_map="auto")
#model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2", load_in_8bit=True, device_map="auto")
#model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2", load_in_4bit=True, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")
#pdb.set_trace()
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids, max_new_tokens=1000)
print(tokenizer.decode(outputs[0]))
5 总结
这个工具的计算的结果,针对代码加入到Transformers中的模型,计算结果有参考价值。
针对本地模型,计算可能会不准确。
作为总结,可以试着回答下面的问题:
- 这个工具可以做什么? 如何使用?
- 此工具如何设置
trust_remote_code=True? 什么情况下需要设置? - Timm是什么?: https://huggingface.co/timm
- 此工具的计算值与实际运行时的差异有多大? 造成差异的原因有那些?
6 代码运行时的常见问题
-
FileNotFoundError: [Errno 2] No such file or directory: 'ldconfig'
解决方法:export PATH=$PATH:/sbin -
KeyError: 'mistral'
解决方法,更新为最新的transformers:pip install -U transformers -
设置 load_in_8bit=True 后出错
pip install -U bitsandbytes
pip install -U git+https://github.com/huggingface/transformers.git
pip install -U git+https://github.com/huggingface/peft.git
pip install -U git+https://github.com/huggingface/accelerate.git参考讨论:https://github.com/huggingface/transformers/issues/24540


