如何计算GPU集群中最大服务器数量
- AIGC
- 2024-10-18
- 1135热度
- 0评论
实践中最常用的GPU集群网络拓扑是胖树(Fat-Tree)无阻塞网络架构(无收敛设计),这是因为Fat-Tree架构易于拓展、路由简单、方便管理和运维,且成本相对较低。实践中,一般规模较小的GPU集群计算网络采用二层架构(Leaf-Spine),而规模较大的GPU集群计算网络采用三层架构(Leaf-Spine-Core)。这里 Leaf对应接入层(Access),Spine对应汇聚层(Aggregation),Core对应核心层。
二层架构(Leaf-Spine):
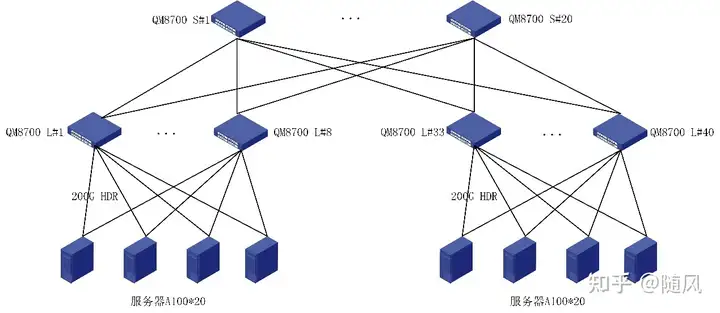
假设一个GPU集群的每台服务器配置8块GPU卡和8张网卡,且计算网络里采用相同型号的交换机,每台交换机端口数为P,使用二层Fat-Tree无阻塞计算网络(Leaf-Spine),一个GPU集群里GPU卡的数量最多为 P*P/2。
在二层Fat-Tree无阻塞计算网络里(Leaf-Spine),Leaf层中每一台Leaf交换机用P/2个端口来连接GPU服务器的网卡,另外P/2个端口向上连接Spine交换机(无阻塞网络要求向下和向上连接数量相同)。Spine层中每台Spine交换机也有P个端口,可以向下最多连接P台Leaf交换机,所以在二层Fat-Tree无阻塞计算网络里最多有P台Leaf交换机和P/2台Spine交换机,GPU卡的数量最多为P*P/2。
例如,对于Nvidia A100集群,假设使用40端口的交换机(如Nvidia Mellanox QM8700),在使用二层Fat-Tree计算网络情况下,一个A100集群最大可以有800张A100卡(40*40/2 = 800)。
值得注意的是,同一台服务器中的GPU卡不应该连接到相同的Leaf交换机上;不同服务器中的编号相同的GPU卡(例如,A服务器中的1号卡 与 B服务器中的1号卡)应该尽量连接到同一个Leaf交换机上,以便提高分布式计算效率。
我们从上面的分析可以看到,假设使用128端口的交换机,二层Fat-Tree无阻塞计算网络能够接入的最大GPU数量仅为8192(128*128/2 = 8192)。如果要构建更大规模的GPU集群,我们需要从二层计算网络扩展到三层计算网络。
三层架构(Leaf-Spine-Core):
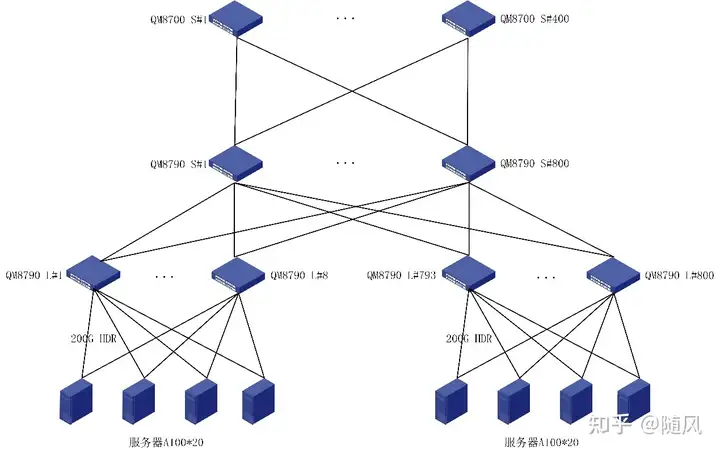
对于规模较大的GPU集群,一般需要采用三层计算网络架构。假设一个GPU集群的每台服务器配置8块GPU卡和8张网卡,且计算网络里采用相同型号的交换机,交换机端口数为P,对于三层Fat-Tree无阻塞计算网络(Leaf-Spine-Core),一个GPU集群里GPU卡的数量最多为 P*P*P/4 。
从二层Fat-Tree网络向三层Fat-Tree网络扩展,我们可以把二层Fat-Tree网络看成一个单元(即一个二层Fat-Tree子网络)。因为每台Spine交换机有一半端口向下连接Leaf交换机(每台Spine交换机最多只能连接P/2个Leaf交换机),另一半端口向上连接Core交换机,所以每个二层Fat-Tree子网络里只能有P/2个Leaf交换机。在无阻塞网络里,各层的连接数量都要保持相同,所以Spine交换机和Leaf交换机的数量相同。
因为Core交换机也有P个端口,可以连接P个这样的二层Fat-Tree子网络,所以三层Fat-Tree无阻塞计算网络(Leaf-Spine-Core)中一共有P*P/2台Leaf交换机、P*P/2台Spine交换机和P*P/4个Core交换机。
| 二层胖树结构Leaf-Spine | 三层胖树结构Leaf-Spine-Core |
|---|---|
| Nmax=P2/2 | Nmax=P3/4 |
| 800(P=40) 100台8卡服务器 |
16,000(P=40) 2,000台8卡服务器 |
| 2048(P=64) 256台8卡服务器 |
65,536(P=64) 8,192台8卡服务器 |
| 8192(P=128) 1024台8卡服务器 |
524,288(P=128) 65,536台8卡服务器 |


