如何调试 Ollama API实操指南
- AIGC
- 2025-06-11
- 612热度
- 0评论
本文介绍如何下载 Ollama 并在本地部署 AI 大型语言模型(例如 DeepSeek-R1、Llama 3.2 等)。使用 Ollama(一款开源大型语言模型服务工具),您可以在自己的计算机上运行强大的开源 AI 模型。我们将提供全面的安装、设置以及最重要的 API 端点调试说明,以实现与您的 AI 模型的无缝交互。
步骤1:下载并安装Ollama
- 访问 Ollama 的官方 GitHub 仓库:https://github.com/ollama/ollama
- 下载与您的操作系统对应的版本(本教程以 macOS 为例;Windows 遵循类似的步骤)。

- 完成安装。

安装完成后,打开终端(在 macOS 上,按下F4并搜索“Terminal”)。输入ollama- 如果出现以下提示,则表示安装成功。

第 2 步:安装 AI 模型
安装 Ollama 后,使用以下命令下载所需的 AI 模型:
ollama run llama3.2
可用型号(替换llama3.2为您喜欢的型号):
| 模型 | 参数 | 尺寸 | 下载 |
|---|---|---|---|
| DeepSeek-R1 | 7B | 4.7GB | ollama run deepseek-r1 |
| DeepSeek-R1 | 671B | 404GB | ollama run deepseek-r1:671b |
| 骆驼 3.3 | 70B | 43GB | ollama run llama3.3 |
| 骆驼 3.2 | 3B | 2.0GB | ollama run llama3.2 |
| 骆驼 3.2 | 1B | 1.3GB | ollama run llama3.2:1b |
| Llama 3.2 Vision | 11B | 7.9GB | ollama run llama3.2-vision |
| Llama 3.2 Vision | 90B | 55GB | ollama run llama3.2-vision:90b |
| 骆驼 3.1 | 8B | 4.7GB | ollama run llama3.1 |
| 骆驼 3.1 | 405B | 231GB | ollama run llama3.1:405b |
| 菲 4 | 14B | 9.1GB | ollama run phi4 |
| Phi 4 迷你 | 38亿 | 2.5GB | ollama run phi4-mini |
| 杰玛 2 | 2B | 1.6GB | ollama run gemma2:2b |
| 杰玛 2 | 9B | 5.5GB | ollama run gemma2 |
| 杰玛 2 | 27B | 16 GB | ollama run gemma2:27b |
| 米斯特拉尔 | 7B | 4.1GB | ollama run mistral |
| 月梦2 | 14亿 | 829MB | ollama run moondream |
| 神经聊天 | 7B | 4.1GB | ollama run neural-chat |
| 椋鸟 | 7B | 4.1GB | ollama run starling-lm |
| 代码骆驼 | 7B | 3.8GB | ollama run codellama |
| 骆驼2未经审查 | 7B | 3.8GB | ollama run llama2-uncensored |
| 左心室射血分数 | 7B | 4.5GB | ollama run llava |
| Granite-3.2 | 8B | 4.9GB | ollama run granite3.2 |
下载过程中会出现进度指示器(持续时间取决于互联网速度):

当提示“发送消息”时,您就可以与模型进行交互了:

步骤3:与Llama3.2交互
互动示例(询问“你是谁?”):

- 用于
Control + D结束当前会话。 - 稍后若要重新启动,只需重新运行即可
ollama run llama3.2。
步骤 4:可选的 GUI/Web 界面支持
使用终端进行日常交互可能会很不方便。为了提供更友好的用户体验,Ollama 的 GitHub 仓库列出了多个由社区驱动的 GUI 和 Web 工具。您可以独立探索这些选项,因为每个项目都提供了各自的设置说明。以下是简要概述:
-
GUI 工具
- Ollama Desktop:macOS/Windows 的原生应用程序(支持模型管理和聊天)。
- LM Studio:具有模型库集成的跨平台界面。
-
Web界面
- Ollama WebUI:基于浏览器的聊天界面(本地运行)。
- OpenWebUI:用于模型交互的可定制 Web 仪表板。
有关详细信息,请访问Ollama GitHub README。
步骤 5:调试 Ollama API
Ollama 默认对外开放本地 API。详情请参阅Ollama API 文档。

下面,我们将使用Apidog来调试 Ollama 生成的本地 API。如果您尚未安装Apidog,请下载并安装——它是一款出色的 API 调试、API 文档编写、API 模拟和自动化 API 测试工具。
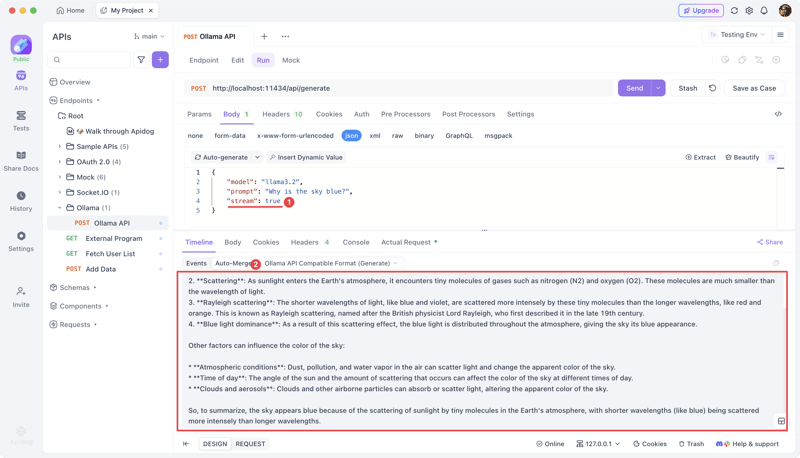
创建新请求
复制此 cURL 命令:
curl --location --request POST 'http://localhost:11434/api/generate' \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "llama3.2",
"prompt": "Why is the sky blue?",
"stream": false
}'
在Apidog中:
- 创建一个新的 HTTP 项目。
- 将 cURL 粘贴到请求构建器中。
- 保存配置。

发送请求
导航到“运行”选项卡,然后点击“发送”。AI 响应将会显示。

对于流输出,请设置"stream": true。

高级 API 调试技巧
以下是有效调试 Ollama API 的一些其他技巧:
- 检查 API 状态:验证 Ollama 服务是否正在运行:
curl http://localhost:11434/api/version
-
解决常见问题:
- 确保在进行 API 调用之前 Ollama 正在运行
- 检查您的模型是否已正确下载(
ollama list) - 验证端口未被防火墙阻止
-
自定义 API 参数:在您的请求中尝试以下参数:
{
"model": "llama3.2",
"prompt": "Write a short poem about coding",
"system": "You are a helpful assistant that writes poetry",
"temperature": 0.7,
"top_p": 0.9,
"top_k": 40,
"max_tokens": 500
}
- 实现错误处理:始终检查 API 的错误响应并在应用程序中妥善处理它们。
结论
本指南涵盖:
- Ollama 安装
- 模型部署
- 命令行交互
- 使用Apidog进行 API 测试和调试
现在,您已拥有完整的本地 AI 模型实验、应用程序开发和 API 调试工作流程。掌握 Ollama API 后,您可以构建复杂的应用程序,充分利用完全在本地机器上运行的强大 AI 模型。


