离线环境下的AI模型部署实战:基于Xinference搭建嵌入、重排与语音处理平台
- AIGC
- 2025-07-18
- 373热度
- 0评论
1. 引言:为什么选择离线部署
在当今AI技术快速发展的时代,许多企业面临着数据安全与合规性的严格要求,特别是在金融、医疗和政府等领域,离线部署AI模型成为刚需。本文将详细介绍如何利用Xinference框架在完全离线的环境中部署四种核心AI能力:文本嵌入(Embedding)、重排序(Reranker)、语音识别(STT)和语音合成(TTS)。
2. 方案概述
离线部署方案具有以下特点:
- 全流程离线:服务部署完全脱离互联网;
- 一键式部署:通过脚本自动化完成复杂配置;
- 资源可控:精确分配GPU资源,避免冲突;
- 模型灵活管理:支持按需插拔不同模型。
3. 准备工作
3.1 资源下载(联网机器)
首先需要在可联网的机器上准备所需资源:
拉取Xinference官方镜像 docker pull xprobe/xinference:latest # 保存为离线包 docker save xprobe/xinference:latest -o xinference-image.tar # 下载所需模型(登录魔塔,根据需求搜索模型,搜索后点击目标模型,右侧下载模型) modelscope download --model maidalun/bce-embedding-base_v1 modelscope download --model maidalun/bce-reranker-base_v1 modelscope download --model iic/CosyVoice-300M modelscope download --model iic/SenseVoiceSmall
模型会默认下载到/root/.cache/modelscope/hub/models/路径下:
├── iic/CosyVoice-300M ├── iic/SenseVoiceSmall ├── maidalun/bce-embedding-base_v1 └── maidalun/bce-reranker-base_v1
3.2 离线包目录结构规划
model_services/ ├── docker/ │ ├── images/xinference-image.tar │ └── docker-compose.yaml ├── models/ │ ├── bce-embedding-base_v1 │ ├── bce-reranker-base_v1 │ ├── CosyVoice-300M │ └── SenseVoiceSmall ├── config.ini └── install.sh
3.2.1. 配置文件(config.ini)
[XINFERENCE] # 指定Xinference服务可用的GPU设备ID(逗号分隔多个ID,如"0,1") # 注意:实际GPU编号需与服务器物理设备一致,可通过`nvidia-smi -L`查看 XINFERENCE_GPUS="0,1" # 模型挂载路径 MODELS_VOLUMES_DIRECTORY=/data/docker_models [EMBEDDING] # 是否启用嵌入模型自动安装(true/true) EMBEDDING_INSTALL_ENABLE=true # 嵌入模型运行时绑定的GPU设备编号 # 必须存在于XINFERENCE_GPUS定义的可用设备列表中 # 示例:若XINFERENCE_GPUS="1",则此处只能填1 EMBEDDING_GPU=0 [RERANKER] # 是否启用重排序模型自动安装(true/true) RERANKER_INSTALL_ENABLE=true # 重排序模型绑定的GPU设备编号 # 需与XINFERENCE_GPUS定义的设备一致 RERANKER_GPU=0 [TTS] # 是否启用语音合成(TTS)模型安装(true/true) TTS_INSTALL_ENABLE=true # TTS模型绑定的GPU设备编号 # 若与嵌入模型共用GPU,需确保总显存不超限 TTS_GPU=0 [STT] # 是否启用语音识别(STT)模型安装(true/true) STT_INSTALL_ENABLE=true # STT模型绑定的GPU设备编号 # 语音识别通常需要更多显存,建议独占GPU STT_GPU=1
关键配置说明:
- GPU分配策略:语音识别模型通常需要更多显存,建议独占GPU
- 模型路径:确保容器内外的路径映射正确
- 启用标志:可灵活控制哪些模型需要加载
3.2.2. Docker编排文件(docker-compose.yaml)
version: "3.3"
services:
xinference:
image: xprobe/xinference:latest
container_name: xinference
restart: unless-stopped
command: ["xinference-local", "-H", "0.0.0.0"] # 启动命令
ports:
- "9997:9997" # 默认API端口
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9997"]
interval: 10s
timeout: 5s
retries: 10
start_period: 30s
environment:
- XINFERENCE_GPUS=${XINFERENCE_GPUS:-"0"} # 从环境变量读取GPU ID,默认使用GPU 0
volumes:
- ${MODELS_VOLUMES_DIRECTORY}:/root/.xinference/models # 模型数据持久化
deploy:
resources:
reservations:
devices:
- driver: nvidia
capabilities: [gpu]
device_ids: ["0,1"]
3.2.3. 自动化部署脚本
#! /bin/bash
#-----------------------------------------------------------
# 模型安装配置脚本
# 1.加载config.ini配置文件
# 2.拷贝模型文件到模型挂载路径
# 3.解压xinference镜像并运行xinference容器
# 4.加载模型
# 5.查看模型状态
#-----------------------------------------------------------
# 加载config.ini配置文件
while IFS='=' read -r key value || [[ -n "$key" ]]; do
# 修剪 key 和 value 的首尾空格和换行符
key=$(echo "$key" | tr -d '\r\n' | xargs)
value=$(echo "$value" | tr -d '\r\n' | xargs)
# 跳过空行、注释行(以#开头)或段标记(如[section])
if [[ "$key" = "" || "$key" =~ ^# || "$key" =~ ^\[.*\] ]]; then
continue
fi
export "$key=$value"
done < config.ini
# 创建并验证目标目录
if [ ! -d "${MODELS_VOLUMES_DIRECTORY}" ]; then
echo "创建模型目录: ${MODELS_VOLUMES_DIRECTORY}"
mkdir -p "${MODELS_VOLUMES_DIRECTORY}" || {
echo "错误:无法创建目录 ${MODELS_VOLUMES_DIRECTORY}"
exit 1
}
fi
# 拷贝模型文件到模型挂载路径
#cp -r models/* ${MODELS_VOLUMES_DIRECTORY}
# 解压xinference容器镜像
#docker load < docker/images/xinference-image.tar
# 运行xinference容器
docker-compose -f ./docker/docker-compose.yaml up -d
while true; do
status=$(docker inspect --format='{{.State.Health.Status}}' xinference)
if [ "$status" = "healthy" ]; then
break
fi
echo "等待Xinference健康状态... 当前状态: $status"
sleep 10
done
echo "加载模型"
# 函数:检查模型是否已注册
function is_model_registered() {
local model_name="$1"
docker exec xinference xinference list | grep -q "$model_name"
}
if [[ "${EMBEDDING_INSTALL_ENABLE}" = "true" ]] ; then
MODEL_NAME="bce-embedding-base_v1"
MODEL_TYPE="embedding"
if ! is_model_registered "$MODEL_NAME"; then
echo "启动嵌入模型: ${MODEL_NAME}"
docker exec xinference xinference launch \
--model-name "$MODEL_NAME" \
--model-type "$MODEL_TYPE" \
--model-path "/root/.xinference/models/${MODEL_NAME}" \
--gpu-idx "$EMBEDDING_GPU"
fi
fi
if [[ "${RERANKER_INSTALL_ENABLE}" = "true" ]] ; then
MODEL_NAME="bce-reranker-base_v1"
MODEL_TYPE="rerank"
if ! is_model_registered "$MODEL_NAME"; then
echo "加载重排序模型: ${MODEL_NAME}"
docker exec xinference xinference launch \
--model-name "$MODEL_NAME" \
--model-type "$MODEL_TYPE" \
--model-path "/root/.xinference/models/${MODEL_NAME}" \
--gpu-idx "$RERANKER_GPU"
fi
fi
if [[ "${TTS_INSTALL_ENABLE}" = "true" ]] ; then
MODEL_NAME="CosyVoice-300M"
MODEL_TYPE="audio"
if ! is_model_registered "$MODEL_NAME"; then
echo "加载TTS模型: ${MODEL_NAME}"
docker exec xinference xinference launch \
--model-name "$MODEL_NAME" \
--model-type "$MODEL_TYPE" \
--model-path "/root/.xinference/models/${MODEL_NAME}" \
--gpu-idx "$TTS_GPU"
fi
fi
if [[ "${STT_INSTALL_ENABLE}" = "true" ]]; then
MODEL_NAME="SenseVoiceSmall"
MODEL_TYPE="audio"
if ! is_model_registered "$MODEL_NAME"; then
echo "加载STT模型: ${MODEL_NAME}"
docker exec xinference xinference launch \
--model-name "$MODEL_NAME" \
--model-type "$MODEL_TYPE" \
--model-path "/root/.xinference/models/${MODEL_NAME}" \
--gpu-idx "$STT_GPU"
fi
fi
echo "查看模型状态"
docker exec xinference xinference list
echo "完成模型注册"
3.2.4 压缩离线包
tar -czvf model_services.tar.gz model_services
4. 离线服务器部署步骤
4.1 前提条件
确保服务器已安装配置好docker、docker-compose并配置好nvidia-container-runtime。
4.2 传输资源包
scp model_services.tar.gz user@offline-server:/data/
4.3 解压资源
tar -xzvf model_services.tar.gz -C /data/
4.4 修改配置
根据实际服务器GPU情况调整config.ini中的设备分配。
注意: xinference上加载的模型并不支持配置显存。
执行部署:
cd /data/model_services chmod +x install.sh ./install.sh
脚本执行日志:
[+] Running 1/1
✔ Container xinference Running 0.0s
加载模型
UID Type Name
------------------------ ------ ---------------
SenseVoiceSmall-Z61fh3ys audio SenseVoiceSmall
启动嵌入模型: bce-embedding-base_v1
Launch model name: bce-embedding-base_v1 with kwargs: {}
Launching model: 100%|██████████ | 100.0%
Model uid: bce-embedding-base_v1
UID Type Name Dimensions
--------------------- --------- --------------------- ------------
bce-embedding-base_v1 embedding bce-embedding-base_v1 768
UID Type Name
------------------------ ------ ---------------
SenseVoiceSmall-Z61fh3ys audio SenseVoiceSmall
加载重排序模型: bce-reranker-base_v1
Launch model name: bce-reranker-base_v1 with kwargs: {}
Launching model: 100%|██████████ | 100.0%
........
加载TTS模型: CosyVoice-300M
Launch model name: CosyVoice-300M with kwargs: {}
Launching model: 100%|██████████ | 100.0%
Launching model: 100%|██████████ | 100.0%
Model uid: CosyVoice-300M
.......
查看模型状态
UID Type Name Dimensions
--------------------- --------- --------------------- ------------
bce-embedding-base_v1 embedding bce-embedding-base_v1 768
UID Type Name
-------------------- ------ --------------------
bce-reranker-base_v1 rerank bce-reranker-base_v1
UID Type Name
------------------------ ------ ---------------
SenseVoiceSmall audio SenseVoiceSmall
CosyVoice-300M audio CosyVoice-300M
完成模型注册
5. 服务验证与测试
5.1 基础检查
# 检查容器状态 docker ps | grep xinference # 查看模型列表 docker exec xinference xinference list
5.2 API接口测试
文本嵌入测试:
curl -X POST "http://localhost:9997/v1/embeddings" \
-H "Content-Type: application/json" \
-d '{"model": "bce-embedding-base_v1", "input": "测试文本"}'
5.3 xinference图形化界面测试
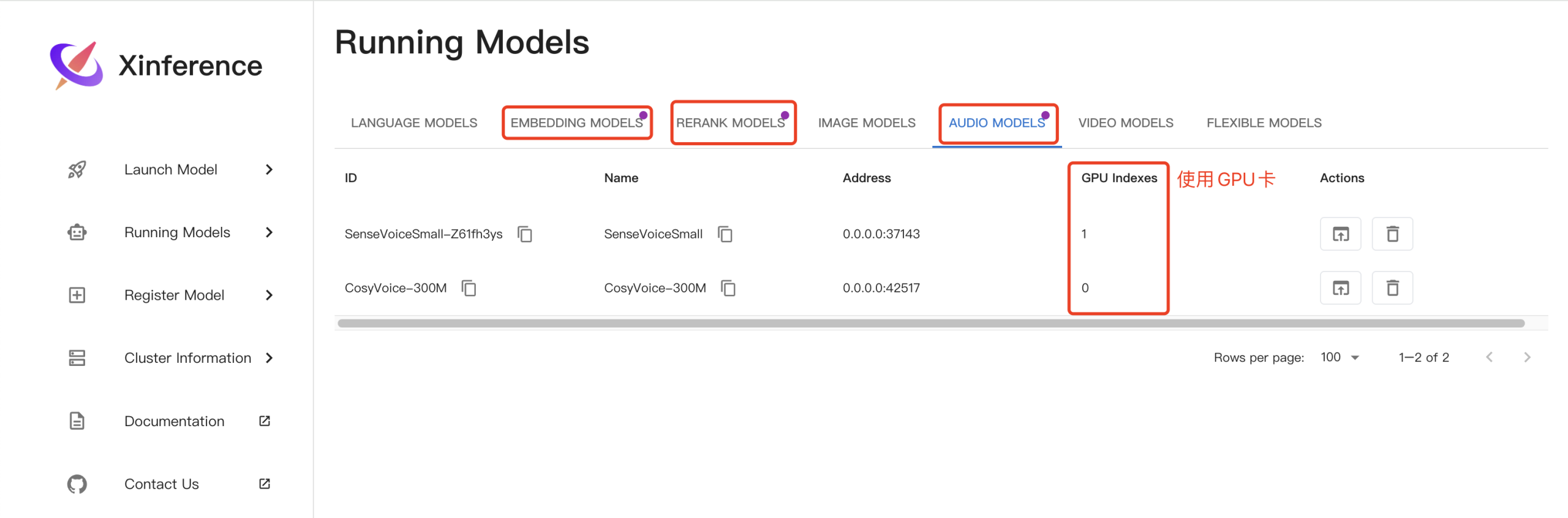
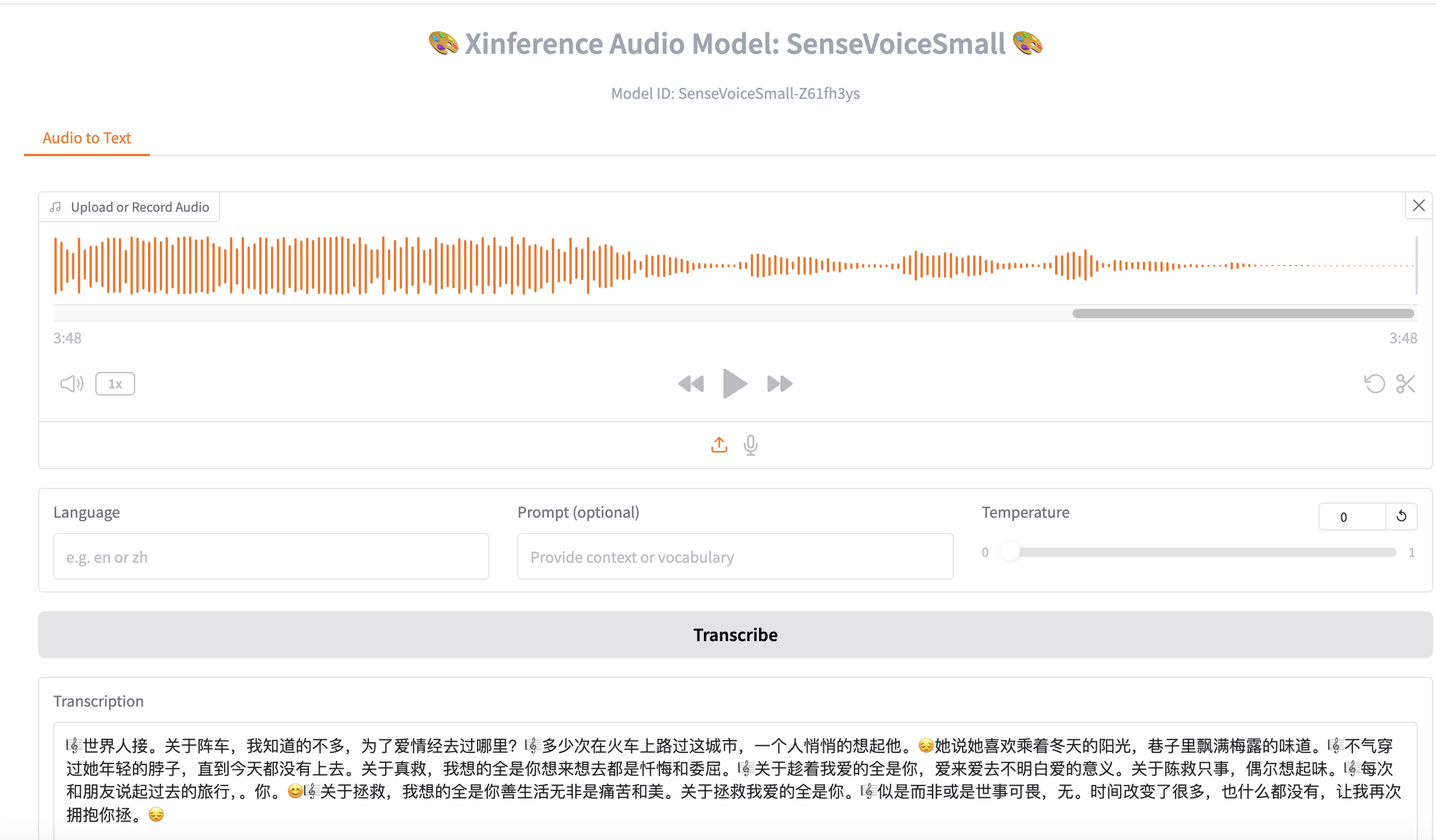
点击语音识别模型行Actions按钮,测试语音识别:
6、总结
通过本文介绍的方案,企业可以在完全离线的环境中快速部署一套功能完整的AI能力平台。该方案不仅保证了数据的安全性,还通过灵活的配置满足了不同场景的需求。Xinference框架的轻量级特性使其成为离线部署的理想选择,而我们的自动化脚本则大大降低了部署复杂度。
未来,随着模型技术的进步,我们可以通过同样的方式无缝升级模型版本,持续提升业务系统的AI能力,而无需改变整体架构。


