揭秘 Milvus 集群高可用部署与压力测试:打造生产级向量数据库基石!
- AIGC
- 2025-07-30
- 381热度
- 0评论
在生产环境中,向量数据库的高可用性是确保 AI 应用稳定运行的关键因素。单点故障可能导致整个智能推荐、搜索或问答系统的服务中断,造成业务损失和用户体验下降。
向量数据库作为 AI 应用的核心基础设施,承载着海量向量数据的存储和检索任务。在搜索推荐、知识问答、图像识别等场景中,系统对向量检索的可用性和性能都有严格要求。因此,构建高可用的向量数据库架构成为生产部署的必要条件。
本文将详细介绍如何基于 Milvus 集群构建高可用架构,通过 HAProxy 实现负载均衡,使用 Keepalived 提供故障切换能力,并通过压力测试验证系统的可靠性。
本文将从架构设计到组件部署,从负载均衡到故障转移,再到压力测试,详细介绍每一个技术细节和实施要点。内容涵盖运维基础知识和架构设计经验,适合不同技术水平的读者参考。
实战服务器配置(架构1:1复刻小规模生产环境,只是配置略有不同)
|
节点角色 |
主机名 |
CPU(核) |
内存(GB) |
系统盘(GB) |
数据盘(GB) |
IP |
备注 |
|---|---|---|---|---|---|---|---|
|
Control 节点 |
ksp-control-1 |
4 |
8 |
50 |
100 |
192.168.9.91 |
控制节点 |
|
Control 节点 |
ksp-control-2 |
4 |
8 |
50 |
100 |
192.168.9.92 |
控制节点 |
|
Control 节点 |
ksp-control-3 |
4 |
8 |
50 |
100 |
192.168.9.93 |
控制节点 |
|
Worker 节点 |
ksp-worker-1 |
8 |
32 |
50 |
100 |
192.168.9.94 |
部署通用工作负载 |
|
Worker 节点 |
ksp-worker-2 |
8 |
32 |
50 |
100 |
192.168.9.95 |
部署通用工作负载 |
|
Worker 节点 |
ksp-worker-3 |
8 |
32 |
50 |
100 |
192.168.9.96 |
部署通用工作负载 |
|
负载均衡节点 |
ksp-slb-1 |
2 |
4 |
50 |
|
|
部署负载均衡(云上环境可忽略) |
|
负载均衡节点 |
ksp-slb-2 |
2 |
4 |
50 |
|
|
部署负载均衡(云上环境可忽略) |
|
合计 |
8 |
40 |
128 |
400 |
600 |
|
|
实战环境涉及软件版本信息:
- 操作系统:openEuler 24.03 LTS SP1 x86_64
- KubeSphere: v4.1.3
- Kubernetes:v1.32.5
- Milvus: v.2.5.13
- Milvus Operator:v1.3.0-rc1
1. 技术架构全景图:高可用架构设计
在开始部署之前,我们需要明确整个高可用架构的设计思路和组件关系。本架构采用分层设计,确保每个层次都具备高可用能力。
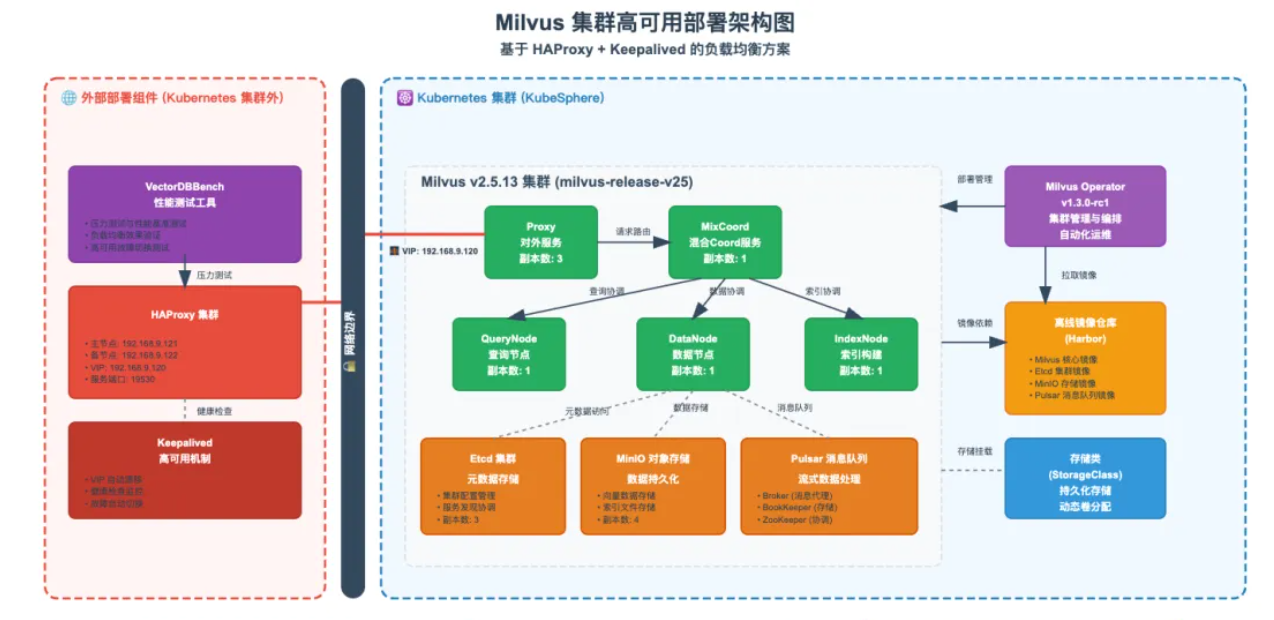
1.1 核心组件:Milvus 集群架构
Milvus v2.5.13 - 生产级向量数据库
Milvus 集群版采用微服务架构,各组件职责明确:QueryNode 负责查询处理,IndexNode 负责索引构建,DataNode 负责数据存储,MixtCoord 负责全局协调,Proxy 负责对外服务接入。这种架构设计实现了组件级的高可用——单个组件故障不会影响整个系统的正常运行。
选择 v2.5.13 版本是基于其在生产环境中的稳定性验证,该版本在性能和可靠性方面都有良好表现。
1.2 负载均衡层:HAProxy 流量分发
HAProxy - 高性能负载均衡器
负载均衡器负责将客户端请求智能分发到后端的多个 Milvus Proxy 实例。主要功能包括:
- 请求分发:支持多种负载均衡算法
- 健康检查:自动检测后端服务状态
- 故障切换:自动将流量从故障节点切换到健康节点
- 会话保持:根据需要维持客户端会话
选择 HAProxy 是因为其高性能、稳定性和丰富的配置选项,特别适合生产环境使用。
1.3 高可用保障:Keepalived VIP 漂移
Keepalived - VIP 高可用解决方案
Keepalived 通过 VRRP 协议实现虚拟 IP 的高可用,确保负载均衡层本身不存在单点故障。主要特性:
- VIP 漂移:主节点故障时自动切换到备节点
- 健康检查:监控 HAProxy 服务状态
- 故障恢复:主节点恢复后可自动切回
1.4 性能验证:VectorDBBench 压力测试
VectorDBBench - 专业向量数据库基准测试工具
VectorDBBench 用于验证整个高可用架构的性能表现,主要测试内容包括:
- 并发性能:不同并发级别下的系统表现
- 故障恢复:节点故障时的服务连续性
- 负载分发:流量在各节点间的分布情况
- 性能指标:响应时间、吞吐量、资源利用率等
2. 环境准备:基础设施规划
在正式开始 Milvus 集群的高可用部署之前,需要完成充分的环境准备工作。合理的环境配置是确保整个项目成功的关键因素。
2.1 Milvus 集群扩容:多副本部署
Milvus 的 Proxy 组件负责接收客户端请求、处理查询和协调后端服务。默认情况下,Milvus 只部署一个 Proxy 副本,这在高并发场景下可能成为性能瓶颈。
为了实现真正的高可用,需要将 Proxy 扩容为多副本模式。本实践将演示如何将 Proxy 扩容到 3 个副本,并通过负载均衡器实现流量分发。
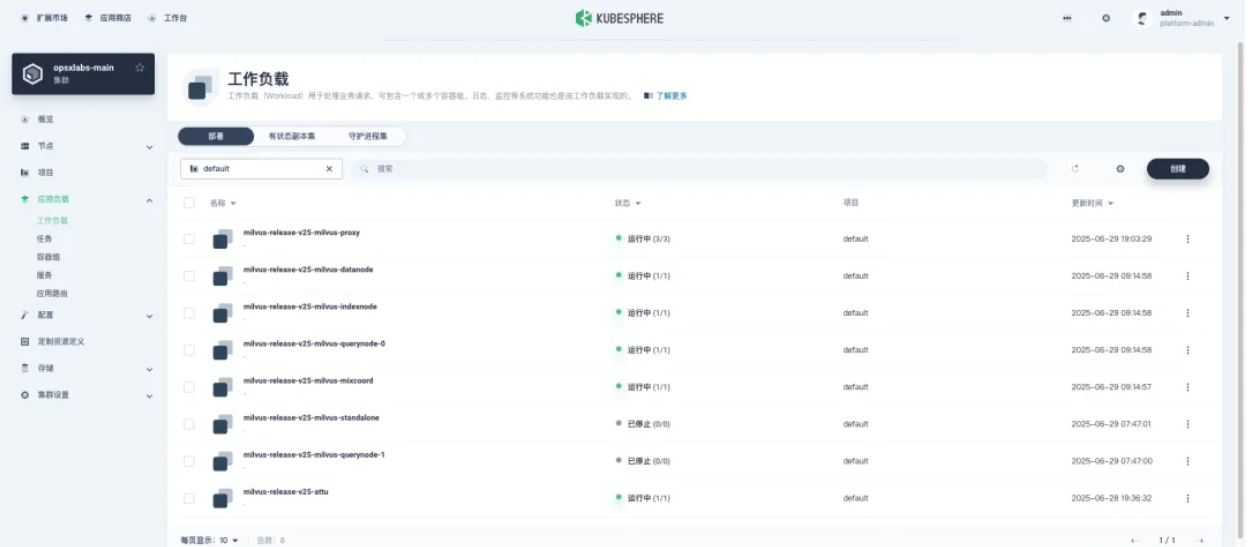
$ kubectl get deployment milvus-release-v25-milvus-proxy
NAME READY UP-TO-DATE AVAILABLE AGE
milvus-release-v25-milvus-proxy 1/1 1 1 11h
我的 Milvus 集群是使用 Milvus Operator 部署的,所以需要先在 K8S 集群,执行以下命令扩容 Proxy Pod副本数。
- 查看自定义的 milvuses.milvus.io 资源
$ kubectl get milvuses.milvus.io
NAME MODE STATUS UPDATED AGE
milvus-release-v25 cluster Healthy True 11h
- 修改 proxy 组件的副本数
# 自己根据实际情况修改 milvus-release-v25 的名字
kubectl patch milvuses.milvus.io milvus-release-v25 --type='json' -p '[{
"op": "replace",
"path": "/spec/components/proxy/replicas",
"value": 3
}]'
- 查看 Proxy 是否扩容
$ kubectl get deployment milvus-release-v25-milvus-proxy
NAME READY UP-TO-DATE AVAILABLE AGE
milvus-release-v25-milvus-proxy 3/3 3 3 11h
- KubeSphere 控制台查看(如果有)
2.2 负载均衡器规划:高可用架构设计
负载均衡器负责统筹全局流量分配,确保每个 Proxy 实例的工作负载均衡。当某个实例出现故障时,负载均衡器需要及时调整流量分配,保证整个系统的正常运行。
在技术选型上,有多种选择:硬件负载均衡器(F5、A10 等)、软件负载均衡器(HAProxy、Nginx)或云服务商提供的负载均衡服务(阿里云 SLB、AWS ELB)。每种方案都有其适用场景,但考虑到成本、灵活性和学习价值,本实践选择 HAProxy 作为软件负载均衡器。
HAProxy 的优势在于:
- 轻量高效:资源占用少,性能表现优异
- 配置灵活:支持多种负载均衡算法和健康检查机制
- 社区活跃:文档丰富,问题解决方案多
- 生产验证:在众多大型互联网公司中得到广泛应用
为了实现 HAProxy 自身的高可用,将部署两台 HAProxy 实例,通过 Keepalived 实现 VIP 漂移。这样即使其中一台 HAProxy 出现故障,另一台也能立即接管服务。
|
组件 |
建议节点数 |
备注 |
|---|---|---|
|
HAProxy |
2 |
负责 Milvus 流量转发,双机热备保证高可用 |
2.3 网络规划:连通性配置
网络规划是整个系统的基础设施,直接影响数据传输的效率和稳定性。在开始部署之前,需要确保所有组件之间的网络连通性,并合理规划端口使用。
核心端口清单:
- 19530: Milvus Proxy 默认端口(客户端连接的主要入口)
- 9091: Milvus Web UI 端口(管理界面)
- 2379/2380: Etcd 端口(集群协调服务)
- 9000/9001: MinIO 端口(对象存储服务)
网络连通性检查清单:
- 客户端 → HAProxy(19530 端口)
- HAProxy → Milvus Proxy 实例(各节点的 NodePort 31530)
- Milvus 各组件之间的内部通信
- 管理员 → HAProxy 统计页面(18080 端口)
网络连通性验证:
在正式部署之前,建议先验证各节点间的网络连通性:
# 验证 HAProxy 节点到 Milvus 节点的连通性,本文选择 3个 k8s worker节点
telnet <milvus_node_ip> 31530
# 验证客户端到 HAProxy VIP 的连通性
telnet <haproxy_vip> 19530
确保网络层面没有连通性问题,避免后续部署过程中的网络故障。
3. 部署 Keepalived:构建 VIP 高可用机制
在高可用架构中,单点故障是最大的风险。即使 HAProxy 性能再强,如果它自己出现故障,整个系统依然会陷入瘫痪。
Keepalived 通过 VRRP(Virtual Router Redundancy Protocol)协议,让两台 HAProxy 服务器形成主备关系。正常情况下主服务器承担所有流量,备服务器处于待命状态;一旦主服务器出现问题,备服务器会在几秒钟内接管服务,实现无缝切换。
这种设计的核心在于,对外部客户端来说,它们始终连接的是一个固定的虚拟 IP(VIP),完全感知不到后端服务器的切换。
3.1 安装 Keepalived:部署 VIP 高可用组件
# 在两台 HAProxy 服务器上执行
yum install keepalived
3.2 配置 Keepalived:主备角色配置
Keepalived 的配置需要为两台服务器分别配置主备角色,让它们能够在关键时刻完成角色切换。
两台机器上必须都安装 Keepalived,配置文件/etc/keepalived/keepalived.conf,但在配置上略有不同。
- 主服务器配置
主节点平时承担主要工作,需要定期向备节点发送心跳信号。一旦主节点失联,备节点就会自动接管工作。
global_defs {
notification_email {
}
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script chk_haproxy {
script "killall -0 haproxy"
interval 2
weight 2
}
vrrp_instance haproxy-vip {
state BACKUP
priority 100
interface eth0
virtual_router_id 51
advert_int 1
authentication {
auth_type PASS
auth_pass Milvus101
}
unicast_src_ip 192.168.9.121 # 本机IP
unicast_peer {
192.168.9.122 #备用节点 IP
}
virtual_ipaddress {
192.168.9.120/24 # The VIP address
}
track_script {
chk_haproxy
}
}
- 备节点配置
备节点平时保持待命状态,时刻准备在主节点出现问题时接管工作。备节点的优先级要低于主节点,这样在正常情况下不会抢夺主节点的控制权。
global_defs {
notification_email {
}
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script chk_haproxy {
script "killall -0 haproxy"
interval 2
weight 2
}
vrrp_instance haproxy-vip {
state BACKUP
priority 99
interface eth0
virtual_router_id 51
advert_int 1
authentication {
auth_type PASS
auth_pass Milvus101
}
unicast_src_ip 192.168.9.122 # 本机IP
unicast_peer {
192.168.9.121 #备用节点 IP
}
virtual_ipaddress {
192.168.9.120/24 # The VIP address
}
track_script {
chk_haproxy
}
}
3.3 启动服务
配置完成后,在两台服务器上同时启动 Keepalived 服务,并设置开机自启动。
# 在两台服务器上执行
systemctl enable keepalived --now
3.4 验证 VIP
启动服务后,验证 VIP 是否正确分配给了主节点。正常情况下,VIP 应该出现在优先级较高的主节点上。
在机器上运行以下命令,应该在其中一台服务器上看到 VIP (192.168.9.120)
$ ip addr show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether bc:24:11:51:c3:d4 brd ff:ff:ff:ff:ff:ff
inet 192.168.9.121/24 brd 192.168.9.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet 192.168.9.120/24 scope global secondary eth0
valid_lft forever preferred_lft forever
inet6 fdd3:3ab8:2be0:0:be24:11ff:fe51:c3d4/64 scope global dynamic mngtmpaddr proto kernel_ra
valid_lft forever preferred_lft forever
inet6 fe80::be24:11ff:fe51:c3d4/64 scope link proto kernel_ll
valid_lft forever preferred_lft forever
4. 部署 HAProxy:配置负载均衡服务
HAProxy 是一个高性能的负载均衡器,负责将客户端请求合理分配到后端的多个 Milvus Proxy 实例。它支持多种负载均衡算法,具备强大的健康检查机制,能够在毫秒级别内检测到后端服务的异常并做出响应。HAProxy 还提供了丰富的统计信息和监控界面,便于实时掌握整个集群的运行状态。
4.1 安装 HAProxy
# 在两台 HAProxy 服务器上执行
yum install haproxy
4.2 HAProxy 配置
HAProxy 的配置文件定义了流量分发规则、健康检查机制、异常处理策略等关键参数。配置文件分为几个关键部分:
- Global 段:全局设置,定义 HAProxy 的基本运行参数
- Defaults 段:默认配置,为所有前端和后端提供基础设置
- Frontend 段:前端配置,定义如何接收客户端请求
- Backend 段:后端配置,定义如何将请求转发给后端服务器
- Listen 段:监听配置,通常用于统计页面等特殊服务
配置 /etc/haproxy/haproxy.cfg 文件:
# /etc/haproxy/haproxy.cfg
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
#pidfile /var/run/haproxy.pid
user haproxy
group haproxy
daemon
maxconn 10000
defaults
mode http
log global
option httplog
option dontlognull
retries 3
timeout http-request 5s
timeout queue 1m
timeout connect 5s
timeout client 1m
timeout server 1m
timeout http-keep-alive 5s
timeout check 5s
maxconn 10000
# Milvus Frontend
frontend milvus_frontend
bind *:19530 # HAProxy 监听的端口,与 Milvus Proxy 端口一致
mode tcp
option tcplog
default_backend milvus_backend
# Milvus Backend
backend milvus_backend
mode tcp
option tcp-check
balance roundrobin # 负载均衡算法,这里使用轮询
server milvus-proxy-1 192.168.9.94:31530 check # k8s集群 Worker-1节点IP:Milvus Proxy 对应的NodePort
server milvus-proxy-2 192.168.9.95:31530 check # k8s集群 Worker-2节点IP:Milvus Proxy 对应的NodePort
server milvus-proxy-3 192.168.9.96:31530 check # k8s集群 Worker-3节点IP:Milvus Proxy 对应的NodePort
# HAProxy 统计页面 (可选)
listen stats
bind *:18080
mode http
stats enable
stats uri /hstats
stats realm Haproxy\ Statistics
stats auth admin:Milvus101 # 替换为你的统计页面用户名和密码
stats hide-version
stats admin if LOCALHOST
4.3 启动服务
配置完成后,启动 HAProxy 服务。同时设置开机自启,确保服务器重启后 HAProxy 能够自动恢复服务。
# 在两台服务器上执行
systemctl enable haproxy --now
4.4 验证部署效果
部署完成后,需要从多个维度验证 HAProxy 是否正常工作。
检查服务运行状态:
systemctl status haproxy
访问监控面板:
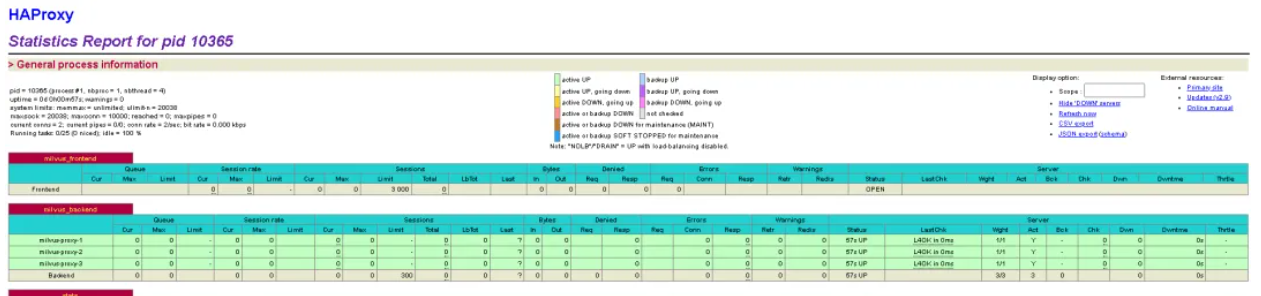
HAProxy 提供了一个功能强大的 Web 统计界面,能够实时显示各种关键指标。在浏览器中访问 http://<HAProxy_VIP>:18080/hstats,输入配置的用户名和密码,即可看到:
- 后端服务器的健康状态(绿色表示正常,红色表示异常)
- 实时流量分布情况
- 响应时间统计
- 连接数和错误率等关键指标
5. 高可用验证
理论再完美,也需要实践来检验。高可用系统的真正价值在于关键时刻能否正常工作。需要模拟各种故障场景,确保系统在面临挑战时能够从容应对。
在开始验证 Milvus 集群的高可用性之前,首先要确保 HAProxy + Keepalived 机制工作正常。这是整个高可用架构的基石。
5.1 基础状态检查
首先,确认 VIP 当前归属于哪个节点。只有明确了当前的主节点,才能进行后续的故障切换测试。
在机器上运行以下命令,可以看到 VIP (192.168.9.120) 在负载均衡节点1上:
[root@ksp-slb-1 ~]# ip add show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether bc:24:11:51:c3:d4 brd ff:ff:ff:ff:ff:ff
inet 192.168.9.121/24 brd 192.168.9.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet 192.168.9.120/24 scope global secondary eth0
valid_lft forever preferred_lft forever
inet6 fdd3:3ab8:2be0:0:be24:11ff:fe51:c3d4/64 scope global dynamic mngtmpaddr proto kernel_ra
valid_lft forever preferred_lft forever
inet6 fe80::be24:11ff:fe51:c3d4/64 scope link proto kernel_ll
valid_lft forever preferred_lft forever
5.2 故障切换测试
现在到了最关键的时刻——测试故障切换机制。确保系统在主节点出现问题时能够无缝切换。
步骤一:模拟主节点故障
通过停止主节点的 HAProxy 服务来模拟故障场景。
在负载均衡节点1上执行命令,停止 HAProxy 服务:
systemctl stop haproxy
步骤二:观察 VIP 漂移
停止服务后,立即检查 VIP 的状态。如果配置正确,VIP 应该会在几秒钟内从主节点上消失。
再次检查浮动 VIP,您可以看到该地址在负载均衡节点1上消失了:
[root@ksp-slb-1 ~]# ip add show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether bc:24:11:51:c3:d4 brd ff:ff:ff:ff:ff:ff
inet 192.168.9.121/24 brd 192.168.9.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fdd3:3ab8:2be0:0:be24:11ff:fe51:c3d4/64 scope global dynamic mngtmpaddr proto kernel_ra
valid_lft forever preferred_lft forever
inet6 fe80::be24:11ff:fe51:c3d4/64 scope link proto kernel_ll
valid_lft forever preferred_lft forever
步骤三:确认备节点接管
如果高可用配置是成功的,VIP 应该会自动漂移到备节点上。
在负载均衡节点2上运行以下命令,验证 VIP 是否已经成功漂移:
[root@ksp-slb-2 ~]# ip add show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether bc:24:11:a9:8f:46 brd ff:ff:ff:ff:ff:ff
inet 192.168.9.122/24 brd 192.168.9.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet 192.168.9.120/24 scope global secondary eth0
valid_lft forever preferred_lft forever
inet6 fdd3:3ab8:2be0:0:be24:11ff:fea9:8f46/64 scope global dynamic mngtmpaddr proto kernel_ra
valid_lft forever preferred_lft forever
inet6 fe80::be24:11ff:fea9:8f46/64 scope link proto kernel_ll
valid_lft forever preferred_lft forever
验证结果:
从上面的输出可以看到,VIP (192.168.9.120) 已经成功漂移到了备节点上,这表明高可用配置完全正确。整个切换过程通常在 1-3 秒内完成,对于大多数应用场景来说,这个切换时间是完全可以接受的。
这个测试证明了高可用机制工作正常:
- Keepalived 成功检测到了主节点的 HAProxy 服务故障
- VIP 自动漂移到了备节点
- 备节点的 HAProxy 立即接管了所有流量
- 整个过程对客户端来说是透明的
6. 负载均衡流量转发
经过前面的部署和验证,已经搭建了一个坚实的高可用基础架构。现在需要让负载均衡系统真正发挥作用,确保每个客户端请求都能被合理地分发到合适的 Milvus Proxy 实例上。
本节将详细介绍如何配置客户端连接,以及如何验证流量是否按照预期进行分发。这是整个高可用架构能否发挥实际效果的关键环节。
6.1 网络连通性验证
在开始流量转发之前,需要先确保网络连通性正常。网络连通性验证确保数据能够顺利地从客户端流向 HAProxy,再从 HAProxy 流向各个 Milvus Proxy 实例。
基础连通性测试:
使用 telnet 命令测试客户端到 HAProxy 的连接:
$ telnet 192.168.9.120 19530
Trying 192.168.9.120...
Connected to 192.168.9.120.
Escape character is '^]'.
# 连接成功表示客户端可以正常访问 HAProxy
如果连接成功,说明网络连通性正常。如果连接失败,需要检查防火墙设置、网络配置或 HAProxy 服务状态。
6.2 流量分发观察
当客户端开始通过 HAProxy 向 Milvus 发送请求时,可以通过多种方式观察负载均衡系统是如何工作的。
实时监控面板:
HAProxy 的统计页面提供实时监控功能,访问 http://<HAProxy_VIP>:18080/hstats 可以实时查看:
- 连接分布:每个后端 Milvus Proxy 的当前连接数
- 请求轮询:请求如何在不同服务器之间进行分配
- 健康状态:各个后端服务的实时健康状况
- 响应时间:每个后端的平均响应时间
- 错误统计:连接失败和超时等异常情况
日志分析:
通过查看各个 Milvus Proxy 实例的日志,会发现请求会根据 HAProxy 的负载均衡策略(配置的是 roundrobin 轮询算法),均匀地分散到不同的 Proxy 上进行处理。
6.3 客户端连接配置
要让整个高可用系统发挥作用,客户端的连接配置至关重要。
核心原则:客户端必须连接到 HAProxy 的 VIP 地址,而不是直接连接任何一个 Milvus Proxy 实例。这样才能享受到负载均衡和高可用的好处。
示例:Python 客户端连接配置
from pymilvus import connections
connections.connect(
alias="default",
host="192.168.9.120", # 替换为 HAProxy 服务器的浮动 VIP 地址
port="19530", # HAProxy 监听 Milvus 流量的端口
user="root", # Milvus 用户名
password="Milvus" # Milvus 密码
)
# 之后的操作都将通过这个连接进行,流量会由 HAProxy 自动转发
# from pymilvus import Collection, FieldSchema, CollectionSchema, DataType
# ...
配置要点解析:
- host=192.168.9.120:HAProxy VIP 地址,客户端连接的统一入口
- port=19530:HAProxy 前端监听的端口,与 Milvus 原生端口保持一致
- 认证信息:如果 Milvus 启用了身份认证,这些凭据会通过 HAProxy 透传给后端的 Milvus 实例
配置优势:
- 客户端无需感知后端 Milvus Proxy 实例数量
- Proxy 实例故障时,HAProxy 自动将流量转发给健康实例
- HAProxy 主节点故障时,Keepalived 自动切换到备节点
- 整个过程对客户端应用透明
7. 部署压力测试工具:VectorDBBench 基准测试
完成高可用架构搭建和负载均衡配置后,需要通过压力测试验证系统的可靠性和性能表现。VectorDBBench 是专业的向量数据库基准测试工具,能够在高并发、大数据量场景下全面评估系统性能,验证高可用架构的实际效果。
7.1 VectorDBBench:专业向量数据库测试工具
VectorDBBench 是由 Zilliz 赞助开发的专业测试工具,具备以下核心能力:
核心测试能力:
- 写入性能测试:模拟大量向量数据的并发写入,测试系统的吞吐能力
- 检索性能测试:模拟高并发的向量相似性搜索,验证查询响应时间和准确率
- 混合负载测试:同时进行读写操作,模拟真实的生产环境负载
- 成本效益分析:特别针对云环境提供详细的性能成本分析报告
选择 VectorDBBench 的原因:
- 专门针对向量数据库设计,测试场景贴近实际应用
- 支持多种并发级别,能够全面评估系统扩展性
- 提供详细的性能指标,帮助发现潜在性能瓶颈
- 开源免费,社区活跃,持续更新
7.2 环境准备
VectorDBBench 基于 Python 开发,需要准备相应的运行环境。
环境要求:
- Python >= 3.11(建议使用 3.12 以获得更好的性能)
- CPU和内存:8C 32G (非建议,尽量选择高配置)
- 足够的内存和存储空间(用于下载测试数据集)
- 稳定的网络连接(首次运行需要下载数据集)
环境搭建步骤:
为了避免与系统环境产生冲突,使用 conda 创建一个独立的虚拟环境:
# 创建专用的测试环境
conda create --name VDBBench python=3.12
# 激活测试环境
conda activate VDBBench
# 验证 Python 版本
python --version
7.3 安装 VectorDBBench
环境准备完成后,安装 VectorDBBench。建议使用国内镜像源以提高下载速度。
核心组件安装:
# 安装 VectorDBBench 核心组件(包含 PyMilvus 客户端)
pip install vectordb-bench -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
安装完成后,VectorDBBench 可以通过命令行方式运行测试。为了更直观地管理测试任务和查看结果,VectorDBBench 还提供了基于 Web 的可视化界面——Leaderboard。
7.4 部署 Leaderboard:Web 可视化界面
Leaderboard 提供了友好的 Web 界面,可以通过图形化方式配置测试参数、监控测试进度、查看测试结果。相比于命令行方式,这种可视化操作更加直观和便捷。
- 安装额外依赖
# 安装测试相关依赖
pip install -e '.[test]' -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
pip install -e '.[pinecone]' -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
- 启动 Web 服务
# 启动 Leaderboard Web 服务
python -m vectordb_bench
启动成功后的命令行输出如下:
(VDBBench) [root@devops-main VectorDBBench]# init_bench
2025-06-29 22:07:10,049 | INFO: all configs: [('ALIYUN_OSS_URL', 'assets.zilliz.com.cn/benchmark/'), ('AWS_S3_URL', 'assets.zilliz.com/benchmark/'), ('CONCURRENCY_DURATION', 30), ('CONFIG_LOCAL_DIR', PosixPath('/data/code/github/VectorDBBench/vectordb_bench/config-files')), ('CUSTOM_CONFIG_DIR', PosixPath('/data/code/github/VectorDBBench/vectordb_bench/custom/custom_case.json')), ('DATASET_LOCAL_DIR', '/tmp/vectordb_bench/dataset'), ('DEFAULT_DATASET_URL', 'assets.zilliz.com/benchmark/'), ('DROP_OLD', True), ('K_DEFAULT', 100), ('LOAD_MAX_TRY_COUNT', 10), ('LOG_LEVEL', 'INFO'), ('MAX_INSERT_RETRY', 5), ('MAX_SEARCH_RETRY', 5), ('NUM_CONCURRENCY', [1, 5, 10, 20, 30, 40, 60, 80]), ('NUM_PER_BATCH', 100), ('RESULTS_LOCAL_DIR', PosixPath('/data/code/github/VectorDBBench/vectordb_bench/results')), ('TIME_PER_BATCH', 1), ('USE_SHUFFLED_DATA', True)] (__main__.py:12) (47310)
Collecting usage statistics. To deactivate, set browser.gatherUsageStats to false.
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://192.168.3.20:8501
External URL: http://113.128.xxx.xxx:8501
打开浏览器,访问
8. 压力测试与负载转发观察:系统性能验证
完成高可用架构部署后,需要通过压力测试验证整个系统的性能表现和可靠性。本阶段将使用 VectorDBBench 对 Milvus 集群进行全面的性能测试,重点观察 HAProxy 的负载均衡效果和故障切换能力。
8.1 测试策略制定
为了重点验证 HAProxy 的负载均衡能力,选择具有小数据集的测试场景:Search Performance Test(50K Dataset, 1536 Dim)。
这个测试场景的特点:50K 数据集规模适中,1536 维向量维度符合实际应用场景,搜索性能测试能够很好地反映 HAProxy 的流量分发效果。
8.2 启动压力测试
在 VectorDBBench 的 Web 界面中配置测试参数。关键是确保连接地址指向 HAProxy 的 VIP 地址,而不是直接连接某个 Milvus Proxy 实例。这样,所有的测试流量都会经过负载均衡器进行分发。

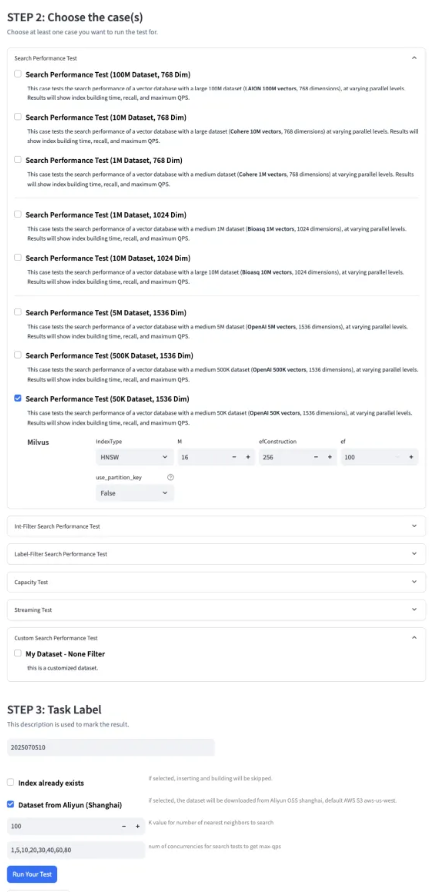
配置完成后,点击「Run Your Test」开始测试。需要注意的是,首次运行时系统需要下载测试数据集,这个过程可能需要几分钟时间。
2025-07-05 10:53:49,067 | INFO: generated uuid for the tasks: 98d3b44bc21f4992be8889a0e494bd7b (interface.py:72) (6412)
2025-07-05 10:53:49,188 | INFO | DB | CaseType Dataset Filter | task_label (task_runner.py:379)
2025-07-05 10:53:49,189 | INFO | ----------- | ------------ -------------------- ------- | ------- (task_runner.py:379)
2025-07-05 10:53:49,189 | INFO | Milvus | Performance OpenAI-SMALL-50K 0.0 | 2025070510 (task_runner.py:379)
2025-07-05 10:53:49,189 | INFO: task submitted: id=98d3b44bc21f4992be8889a0e494bd7b, 2025070510, case number: 1 (interface.py:247) (6412)
2025-07-05 10:53:49.968 WARNING streamlit.runtime.scriptrunner_utils.script_run_context: Thread 'MainThread': missing ScriptRunContext! This warning can be ignored when running in bare mode.
2025-07-05 10:53:51,272 | INFO: [1/1] start case: {'label': <CaseLabel.Performance: 2>, 'name': 'Search Performance Test (50K Dataset, 1536 Dim)', 'dataset': {'data': {'name': 'OpenAI', 'size': 50000, 'dim': 1536, 'metric_type': <MetricType.COSINE: 'COSINE'>}}, 'db': 'Milvus'}, drop_old=True (interface.py:177) (8152)
2025-07-05 10:53:51,272 | INFO: Starting run (task_runner.py:118) (8152)
2025-07-05 10:53:51,401 | INFO: Milvus client drop_old collection: VDBBench (milvus.py:63) (8152)
2025-07-05 10:53:51,453 | INFO: Milvus create collection: VDBBench (milvus.py:84) (8152)
2025-07-05 10:53:54,010 | INFO: local dataset root path not exist, creating it: /tmp/vectordb_bench/dataset/openai/openai_small_50k (data_source.py:74) (8152)
2025-07-05 10:53:54,010 | INFO: Start to downloading files, total count: 4 (data_source.py:96) (8152)
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:06<00:00, 1.70s/it]
2025-07-05 10:54:00,815 | INFO: Succeed to download all files, downloaded file count = 4 (data_source.py:101) (8152)
2025-07-05 10:54:00,816 | INFO: Read the entire file into memory: test.parquet (dataset.py:322) (8152)
2025-07-05 10:54:01,080 | INFO: Read the entire file into memory: neighbors.parquet (dataset.py:322) (8152)
2025-07-05 10:54:01,206 | INFO: Start performance case (task_runner.py:163) (8152)
测试过程日志--加载数据
2025-07-05 10:55:00,081 | INFO: (SpawnProcess-2:1) Start inserting embeddings in batch 100 (serial_runner.py:56) (17178)
2025-07-05 10:55:00,082 | INFO: Get iterator for shuffle_train.parquet (dataset.py:343) (17178)
2025-07-05 10:56:10,431 | INFO: (SpawnProcess-2:1) Finish loading all dataset into VectorDB, dur=70.34951976899993 (serial_runner.py:95) (17178)
测试过程日志--Milvus optimizing 和 index buliding
2025-07-05 10:56:14,079 | INFO: Milvus optimizing before search (milvus.py:145) (17726)
2025-07-05 10:56:53,731 | INFO: compactation completed. waiting for the rest of index buliding. (milvus.py:177) (17726)
2025-07-05 10:58:39,183 | INFO: Finish loading the entire dataset into VectorDB, insert_duration=73.32084754300013, optimize_duration=144.83557592299985 load_duration(insert + optimize) = 218.1564 (task_runner.py:173) (17118)
测试过程日志--最终结果
2025-07-05 11:06:10,720 | INFO: SpawnProcess-2:257 start search the entire test_data to get recall and latency (serial_runner.py:245) (25838)
2025-07-05 11:06:19,172 | INFO: SpawnProcess-2:257 search entire test_data: cost=7.6319s, queries=1000, avg_recall=0.9454, avg_ndcg=0.9553, avg_latency=0.0076, p99=0.0092 (serial_runner.py:284) (25838)
2025-07-05 11:06:19,512 | INFO: Performance case got result: Metric(max_load_count=0, insert_duration=73.3208, optimize_duration=144.8356, load_duration=218.1564, qps=1113.6589, serial_latency_p99=np.float64(0.0092), recall=np.float64(0.9454), ndcg=np.float64(0.9553), conc_num_list=[1, 5, 10, 20, 30, 40, 60, 80], conc_qps_list=[134.9749, 582.6331, 835.105, 980.2477, 978.0413, 424.9932, 1113.6589, 1112.6591], conc_latency_p99_list=[np.float64(0.009348437200169429), np.float64(0.011713690490205408), np.float64(0.01818077740040281), np.float64(0.03207416211947931), np.float64(0.04828481018948879), np.float64(0.05170702649949816), np.float64(0.08001076160142474), np.float64(0.10370727769894073)], conc_latency_avg_list=[np.float64(0.00739066472295792), np.float64(0.00855601782906844), np.float64(0.011907854858809292), np.float64(0.020187673306928878), np.float64(0.030115787286635103), np.float64(0.0558421274263327), np.float64(0.05218318199342633), np.float64(0.06881550074310919)], st_ideal_insert_duration=0, st_search_stage_list=[], st_search_time_list=[], st_max_qps_list_list=[], st_recall_list=[], st_ndcg_list=[], st_serial_latency_p99_list=[], st_conc_failed_rate_list=[]) (task_runner.py:200) (17118)
2025-07-05 11:06:19,513 | INFO: [1/1] finish case: {'label': <CaseLabel.Performance: 2>, 'name': 'Search Performance Test (50K Dataset, 1536 Dim)', 'dataset': {'data': {'name': 'OpenAI', 'size': 50000, 'dim': 1536, 'metric_type': <MetricType.COSINE: 'COSINE'>}}, 'db': 'Milvus'}, result=Metric(max_load_count=0, insert_duration=73.3208, optimize_duration=144.8356, load_duration=218.1564, qps=1113.6589, serial_latency_p99=np.float64(0.0092), recall=np.float64(0.9454), ndcg=np.float64(0.9553), conc_num_list=[1, 5, 10, 20, 30, 40, 60, 80], conc_qps_list=[134.9749, 582.6331, 835.105, 980.2477, 978.0413, 424.9932, 1113.6589, 1112.6591], conc_latency_p99_list=[np.float64(0.009348437200169429), np.float64(0.011713690490205408), np.float64(0.01818077740040281), np.float64(0.03207416211947931), np.float64(0.04828481018948879), np.float64(0.05170702649949816), np.float64(0.08001076160142474), np.float64(0.10370727769894073)], conc_latency_avg_list=[np.float64(0.00739066472295792), np.float64(0.00855601782906844), np.float64(0.011907854858809292), np.float64(0.020187673306928878), np.float64(0.030115787286635103), np.float64(0.0558421274263327), np.float64(0.05218318199342633), np.float64(0.06881550074310919)], st_ideal_insert_duration=0, st_search_stage_list=[], st_search_time_list=[], st_max_qps_list_list=[], st_recall_list=[], st_ndcg_list=[], st_serial_latency_p99_list=[], st_conc_failed_rate_list=[]), label=ResultLabel.NORMAL (interface.py:179) (17118)
2025-07-05 11:06:19,514 | INFO |Task summary: run_id=8eca0, task_label=2025070510 (models.py:402)
2025-07-05 11:06:19,514 | INFO |DB | db_label case label | load_dur qps latency(p99) recall max_load_count | label (models.py:402)
2025-07-05 11:06:19,514 | INFO |------ | -------- ----------------------------------------------- ---------- | ----------- ------------ --------------- ------------- -------------- | ----- (models.py:402)
2025-07-05 11:06:19,514 | INFO |Milvus | Search Performance Test (50K Dataset, 1536 Dim) 2025070510 | 218.1564 1113.6589 0.0092 0.9454 0 | :) (models.py:402)
2025-07-05 11:06:19,515 | INFO: write results to disk /data/code/github/VectorDBBench/vectordb_bench/results/Milvus/result_20250705_2025070510_milvus.json (models.py:268) (17118)
2025-07-05 11:06:19,516 | INFO: Success to finish task: label=2025070510, run_id=8eca04cf8b4544609918bc38fcb9bf79 (interface.py:218) (17118)
图形化页面查看最终的测试结果
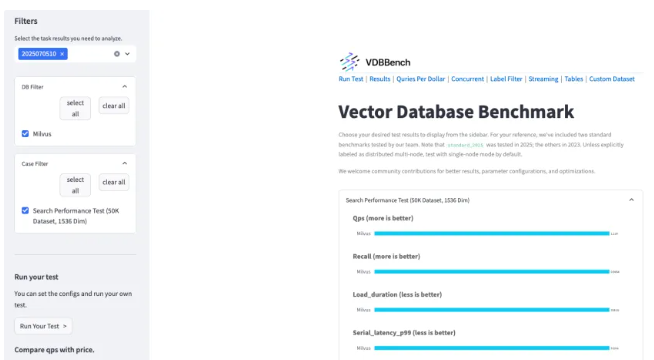
8.3 观察负载均衡效果
测试启动后,可以通过多个监控界面观察整个系统的运行状况。建议同时打开以下观察窗口:
- VectorDBBench 控制台:观察测试进度和性能指标
- HAProxy 统计页面:监控流量分发情况
- 系统资源监控:观察各节点的资源使用情况(可选)
本文重点关注 HAProxy 的负载均衡能力验证,主要通过 VectorDBBench 的运行日志和 HAProxy 统计页面来观察负载均衡效果。
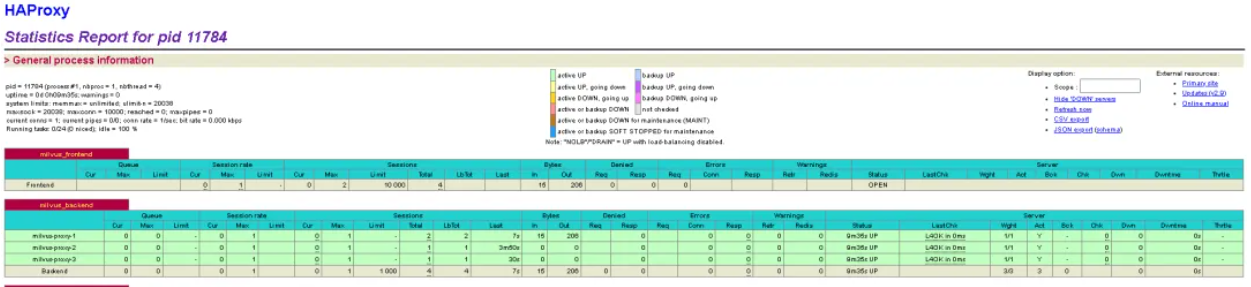
HAProxy 统计页面:实时监控界面
访问 HAProxy 的统计页面(http://<HAProxy_IP>:18080/stats),通过定期刷新页面,可以观察以下关键指标:
- Sessions(会话数):观察流量分配的核心指标。在
milvus_backend部分,可以看到每个 Milvus Proxy 实例的Sess(当前会话数)和Total(总会话数)。正常情况下,这些数字应该相对均衡。 - Bytes in/out(流量统计):反映每个后端服务器的实际流量。通过观察各个后端服务器的流量进出情况,可以确认 HAProxy 是否实现了流量的均衡分发。
- Status(健康状态):最重要的指标之一。所有后端 Milvus Proxy 实例的状态都应该显示为
UP(绿色)。如果某个实例显示为DOWN,说明该实例出现了问题,HAProxy 会自动将流量转移到其他健康的实例上。 - Response Time(响应时间):虽然 HAProxy 不直接显示 Milvus 的 QPS,但可以通过会话数变化和响应时间来间接评估系统性能。
实战观察:"智能调度"的精彩表现
在测试过程中,我们通过 HAProxy 统计页面可以清晰地看到"智能调度"的实际效果:
场景一:系统正常运行(并发40)
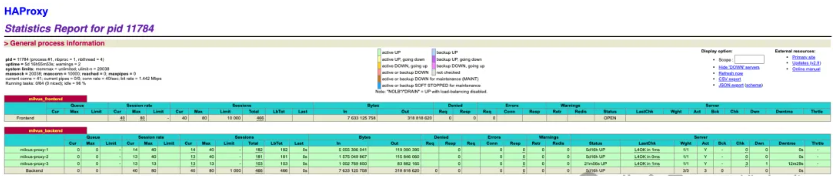
在这个阶段,所有 Milvus Proxy 实例都处于健康状态,HAProxy 将流量均匀分配到各个后端服务器,就像"交通调度员"将车流合理分配到各个车道。
场景二:故障检测阶段(节点异常,并发40)
在 proxy-3 节点上执行以下命令,使用 iptables 丢弃来自负载均衡节点的流量,模拟节点网络故障场景:
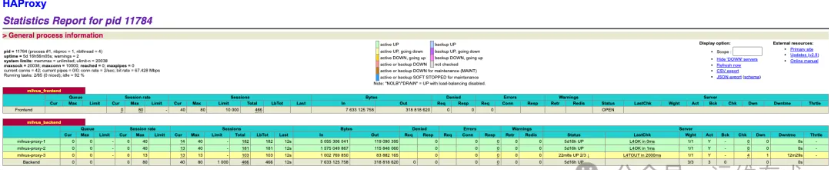
当某个 Milvus Proxy 实例出现问题时,HAProxy 立即检测到异常。此时转发到故障节点的 13 个 Session 面临风险,但 HAProxy 的健康检查机制正在发挥作用。
场景三:故障确认与流量转移(节点故障,并发40)
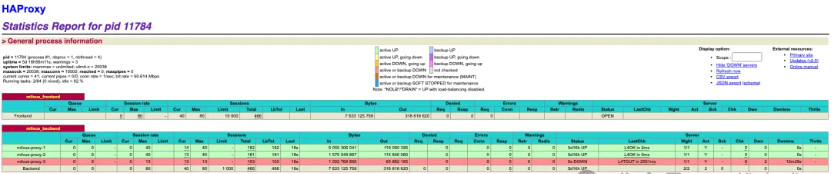
故障确认后,HAProxy 自动将该节点标记为不可用,并将新的请求全部转发到健康的节点上。这就像"交通调度员"发现某条车道堵塞后,立即引导车流绕行其他畅通的车道。
VectorDBBench 测试日志:"考官"的实时反馈
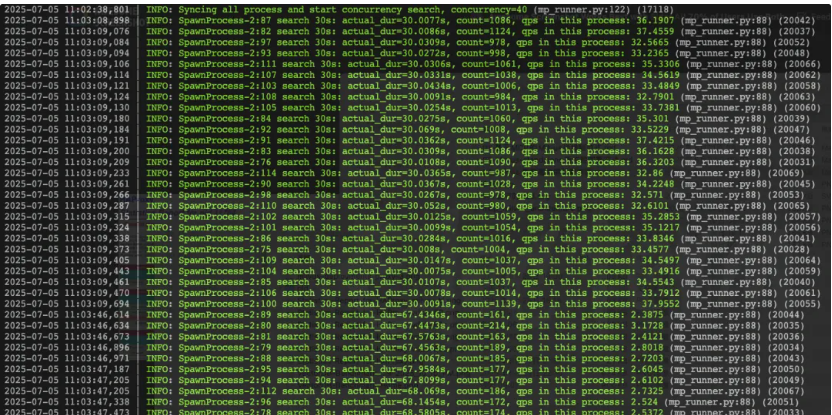
从 VectorDBBench 的日志中,我们可以看到测试过程中的性能表现,这为我们评估系统在不同负载下的表现提供了重要参考。
高并发场景验证(并发60和80)

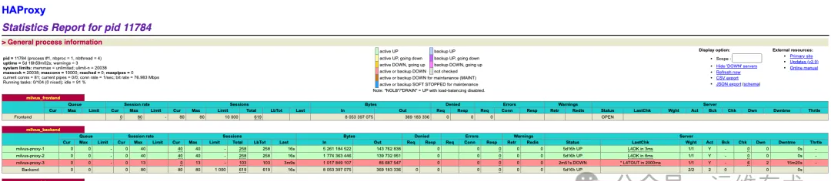
随着并发数的增加,我们可以观察到 HAProxy 在高负载情况下的表现。即使在单节点故障的情况下,剩余的健康节点依然能够承担起全部的流量负载。
测试总结
通过这次"实战演练",我们验证了 HAProxy 作为 Milvus 服务负载均衡器的核心能力:
- 智能分发:正常情况下流量均匀分配
- 故障检测:快速识别异常节点
- 自动切换:无缝将流量转移到健康节点
- 高可用保障:单点故障不影响整体服务
9. 故障转移测试:其他高可用性验证
故障转移测试是验证高可用架构有效性的关键环节。通过模拟各种故障场景,验证系统的自动恢复能力和服务连续性。
受限于篇幅,前文仅演示了 proxy3 节点的网络故障场景测试。建议读者可以继续尝试以下故障场景的测试。
9.1 模拟 Milvus Proxy 故障
首先测试 Milvus Proxy 层的故障转移能力,验证 HAProxy 的健康检查和自动切换机制。
测试步骤
- 确保测试正在运行:在 VectorDBBench 中启动一个长时间的测试任务
- 停止其中一个 Proxy 实例:
# 在 K8s 集群中删除一个 Proxy Pod
kubectl delete pod <milvus-proxy-pod-name> - 观察 HAProxy 统计页面:访问
http://<HAProxy_IP>:18080/hstats,观察故障实例的状态变化 - 检查测试是否继续:确认 VectorDBBench 的测试没有中断
预期结果
- HAProxy 统计页面中,故障的 Proxy 实例状态是否发生变化?
- 流量会自动转移到其他健康的 Proxy 实例
- VectorDBBench 的测试应该继续正常运行,不会出现连接错误
9.2 模拟 HAProxy 故障
接下来测试 HAProxy 层的故障转移,验证 Keepalived VIP 漂移机制。
测试步骤
- 确认当前 VIP 位置:
# 检查哪个节点持有 VIP
ip addr show | grep 192.168.9.120 - 停止主 HAProxy 服务:
# 在持有 VIP 的节点上停止 HAProxy
sudo systemctl stop haproxy - 观察 VIP 漂移:在另一个 HAProxy 节点上检查 VIP 是否已经漂移过来
- 验证服务连续性:确认 VectorDBBench 测试仍然正常运行
预期结果
- VIP 应该在几秒钟内漂移到备用 HAProxy 节点
- 测试应该继续正常运行,可能会有短暂的连接中断(通常少于 5 秒)
- 新的主 HAProxy 节点应该正常提供负载均衡服务
需要特别说明的是,本文的测试场景主要聚焦于验证 HAProxy 的负载均衡功能和基本的故障转移能力。在实际生产环境中,建议制定更加全面和严谨的测试方案,包括但不限于:
- 完整的性能基准测试
- 各类故障场景的恢复验证
- 长期稳定性测试
- 极限压力下的系统表现
- 网络分区等异常场景测试
建议根据具体业务需求和服务等级协议(SLA)来设计符合实际情况的测试计划。
总结
通过本次实践,我们成功构建了一个完整的 Milvus 高可用架构,并通过压力测试验证了系统的可靠性。整个部署过程涵盖了从 Milvus 集群扩容到负载均衡配置,再到故障切换验证的完整流程。
技术收获
核心技术掌握:
- Milvus 集群的高可用部署方案
- HAProxy + Keepalived 的高可用机制
- VectorDBBench 性能测试工具的使用
- 负载均衡和故障切换的配置与验证
架构设计理念:
- 高可用是系统性工程,需要多层保障
- 主动监控和健康检查的重要性
- 理论设计需要通过实际测试验证
生产环境考虑
在实际生产环境中,还需要考虑以下方面:
- 监控体系:建立全方位的监控和告警机制
- 容量规划:根据业务增长预测进行资源规划
- 灾备策略:制定完整的备份和恢复方案
- 安全加固:实施网络隔离和访问控制
- 运维自动化:减少人工干预,提高运维效率
技术演进方向
随着技术发展,架构也需要持续演进:
- 关注 Milvus 新版本的特性和优化
- 研究 AI 驱动的智能运维方案


