拒绝“大而无当”:蚂蚁 Elephant 模型如何用 100B 参数重新定义 AI 的“智效比”?
- AIGC
- 2026-04-23
- 501热度
- 0评论

近期 OpenRouter 平台上一款匿名模型Elephant Alpha引发全网热议:仅100B 参数就在同规模中拿下SOTA,且Token 效率极高,被网友称为 “国产干活神器”。
4 月 22 日,量子位独家确认:这头神秘 “大象”,正是蚂蚁 Inclusion AI 团队打造的百灵 Ling‑2.6‑flash,主打快、准、省,堪称国产版 Grok 4 Fast,一上线就登顶平台热榜。
它的核心配置相当能打:
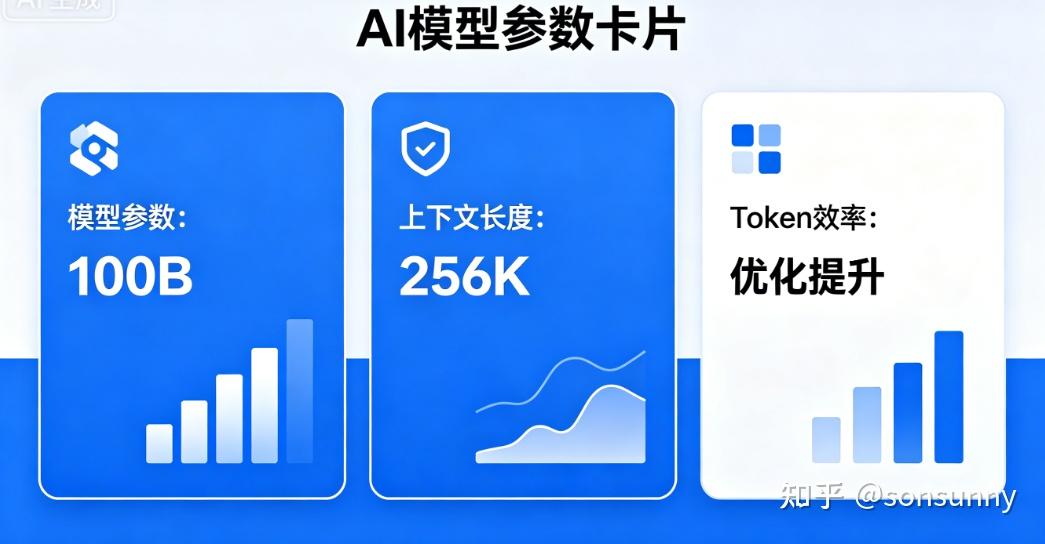
参数量:100B(实际激活仅 7.4B)
- 上下文:256K 输入 + 32K 输出
- 定位:轻量高效、低成本、高吞吐,适配代码、文档、轻量 Agent 场景
三大实测:不废话、省 Token、响应超快
我们在 OpenRouter 网页端,用高频办公场景实测,验证它是不是真 “干活圣体”。
1)代码修 Bug:一针见血,不浪费 Token
测试任务:用 HTML + 原生 JS 做带校验的活动报名页,再故意删掉关键变量制造报错。
结果:
一次生成可直接运行的完整代码
- 报错后精准定位缺失行,只给关键修复,无多余输出
- 大幅减少无效 Token 消耗,开发者体验拉满
2)长文档整理:抓重点、输出规范
测试任务:3000 字杂乱会议纪要,要求按JSON 格式输出:结论摘要、待办 + 责任人、全员邮件草稿。
结果:
自动过滤闲聊、废话、重复内容
- 严格按格式输出,结构清晰
- 对比同场景模型,输出更短、信息更密,Token 消耗更低
3)轻量 Agent:又快又稳,10 秒搞定闭环
测试任务:读取 CSV 销售报表→计算季度同比→生成分析→自检数据。
结果:
思考约 10 秒,输出仅 2 秒
- 逻辑完整、数字准确,无明显幻觉
- 响应速度碾压多数同级别模型
权威榜单:一致性 9.6 分,时延压到 1 秒内
在 AI BENCHY 实测中,「大象」交出硬核成绩单:
- 一致性评分:9.6/10(极高稳定度)
- 平均响应:≈1 秒,远快于同类 10–30 秒水平
- 输出 Token 稳定在 2500 左右,算力 “花在刀刃上”
- 同尺寸Agent 基准 SOTA,性价比突出
也有短板:这些场景不适合
「大象」走高效实用路线,复杂场景仍有局限:
- 不擅长超长链战略规划(如出海 + 甘特图)
- 无法获取实时热搜、最新数据
- 太新的 API/SDK 可能出现知识幻觉
- Prompt 太模糊,输出质量会下降
建议搭配:大模型做规划 + 大象做执行,效率最高

行业信号:AI 不再堆参数,开始拼 “智效比”
《财经》数据显示:企业 AI 应用中约 50% Token 被浪费,Agent 多轮交互会让冗余成本指数级上升。
OpenAI、谷歌纷纷推出小模型:
- GPT‑5.4 Mini/Nano:主打高吞吐、低延迟
- Gemma 4:参数量大幅缩减,成本降 10 倍
- 蚂蚁「大象」:100B 轻量架构,算力成本仅为传统方案约 1/10
对中小企业、开发者来说:
不用顶配大模型,轻量高效模型就能搞定代码、文档、数据、轻 Agent,每一分算力都产生价值。蚂蚁「大象」(Ling‑2.6‑flash)证明:大模型不一定越大越好,好用、省 Token、响应快,才是落地刚需。它以 100B 轻量身材拿下 SOTA,把 AI 从 “炫技” 拉回 “生产力”,开启高效、经济、普惠的 AI 落地新阶段。