大模型训练显存分析
- AIGC
- 2024-10-30
- 902热度
- 0评论
数据类型
float32(FP32):32 位浮点数,也称为单精度。
float16(FP16):16 位浮点数,表示范围较小,也被称为半精度。
bfloat16(BF16):扩大了指数位数,缩小了小数位数,因此表示的范围更大,精度更弱。
一般采用 16 位的表示,那么一个参数占用 2byte,即 2B。
FP16 的精度高,但是表示范围小,容易上溢;
BF16 的表示范围大,但精度低,因此更容易下溢,为了避免溢出问题,提出了混合精度方案。
训练过程
训练大模型时通常会采用 AdamW 优化器,并用 混合精度 训练来加速训练,基于这个前提分析显存占用。
在一次训练迭代中,每个可训练模型参数都会对应 1 个梯度,并对应 2 个优化器状态(Adam 优化器梯度的一阶动量和二阶动量)。
推理过程
在神经网络的推理阶段,没有优化器状态和梯度,也不需要保存中间激活。模型推理阶段占用的显存要远小于训练阶段。
如果使用 float16 来进行推理,推理阶段模型参数占用的显存大概是 2 Φ
模型参数
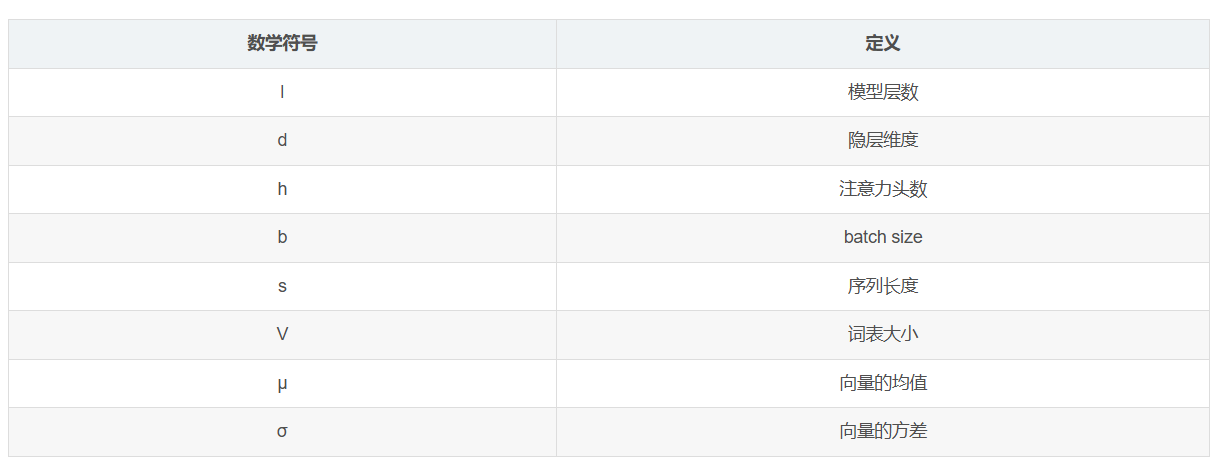
符号说明:
从输入到输出的顺序依次计算:
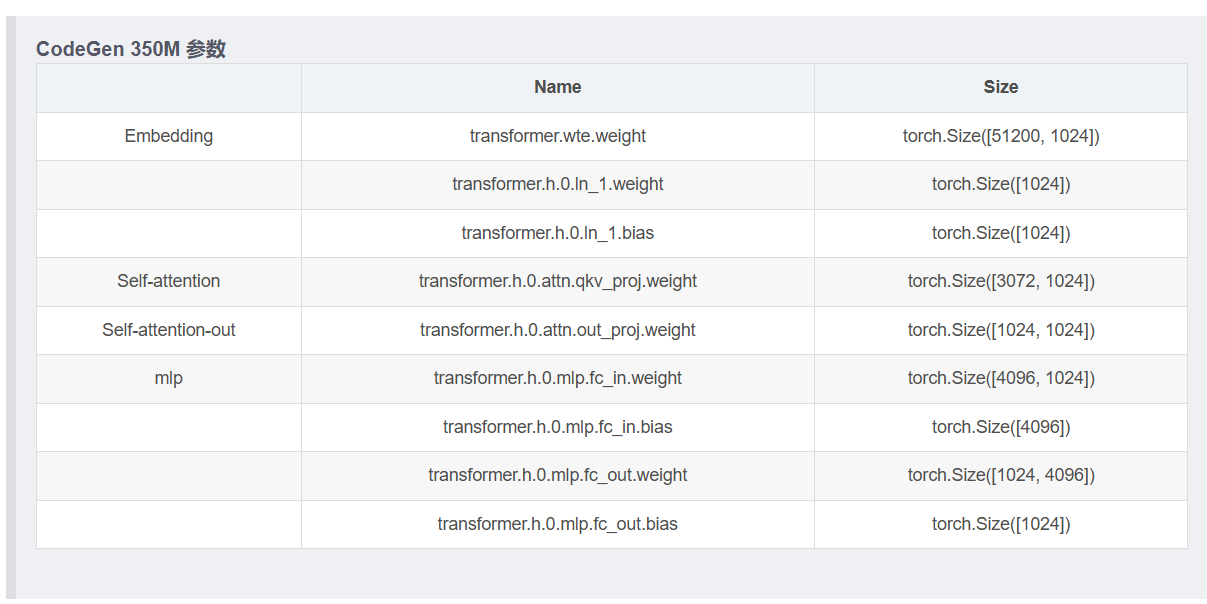
Embedding 层:词嵌入矩阵即一个 V → d V 无偏置线性层,将 V 大小的 one-hot 编码映射成 d dd 大小的 token。参数个数 $ Vd $。
Positional Embedding:如果采用可训练式的位置编码,会有一些可训练模型参数,数量比较少。如果采用相对位置编码,例如 RoPE 和 ALiBi,则不包含可训练的模型参数。我们忽略这部分参数。。
L 个 block:

优化器状态
在训练过程中,模型的每个参数会记录梯度用于更新,此外优化器也会额外记录一些数据,称为 优化器状态。
设模型参数为 Φ ,那么梯度的元素数量为Φ,模型参数(fp16)、模型梯度(fp16)和优化器状态(fp32), 总占用:
2 Φ + 2 Φ + K Φ = ( 4 + K ) Φ
总占用和参数量有关,和输入大小无关。
在整个训练过程中都要存在显存中。 模型参数一般只能通过并行切分(Tensor Parallelism/Pipeline Parallism)能减少。优化器状态一般通过 ZeRO 来减少。
不同优化器的 K 值不同,算法的中间变量、框架的实现都有可能有一定区别。

中间激活值
激活(activations) 指的是前向传递过程中计算得到的,并在后向传递过程中需要用到的所有张量
中间激活值占用显存 分两个部分分析:Self-Attention 和 MLP,Embedding 没有中间值。
Self-Attention 块的中间激活占用显存大小为 11bsd+5bs2h
对于 MLP 块,需要保存的中间激活值为 19bsd 。
layer norm 需要保存其输入,大小为 2bsd,2 个 layer norm 需要保存的中间激活为4bsd
对于 L层 transformer 模型, 最终合计L∗ ( 34bsd+ 5bs2h)
激活值 与输入数据的大小(批次大小 b 和 序列长度 )成正相关。在训练过程中是变化值,特别是 batch size 大的时候成倍增长很容
易导致 OOM。可以通过 重计算、并行切分 策略减少。
在一次训练迭代中模型参数(或梯度)占用的显存大小 只与模型参数量和参数数据类型有关,与输入数据的大小是没有关系的。
优化器状态占用的显存大小与优化器类型有关,与模型参数量有关,与输入数据的大小无关。
中间激活值 与输入数据的大小(批次大小 b 和 序列长度 s)是成正相关的,随着 批次大小 b bb 和 序列长度 s ss 的增大,
中间激活占用的显存会同步增大。当我们训练神经网络遇到显存不足 OOM(Out Of Memory)问题时,通常会尝试减小批次大小来避免显存
不足的问题,这种方式减少的其实是中间激活占用的显存,而不是模型参数、梯度和优化器的显存。
实例说明
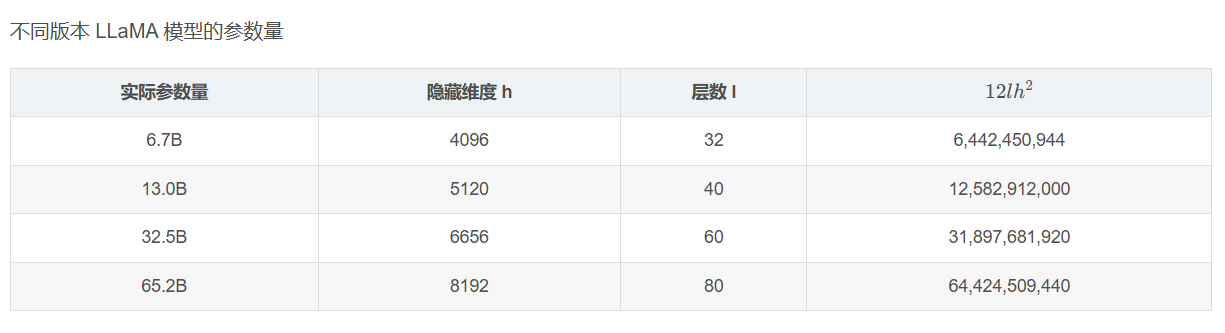
以 GPT3-175B 为例,直观对比模型参数与中间激活的显存大小。GPT3 的模型配置如下。假设采用混合精度训练,模型参数和中间激活都采用 float16 数据类型,每个元素占 2 个 bytes。

————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/EveyD/article/details/139698305


