GPT推理token生成机制中的kvcache详解
- AIGC
- 2024-10-30
- 1312热度
- 0评论
一句话介绍
kvcache是一种以空间换时间的策略,能够加快语言模型的生成速度。
要明白kvcache,需要弄明清楚两个细节——GPT 的生成机制以及注意力掩码 (attention mask)。
GPT的生成机制
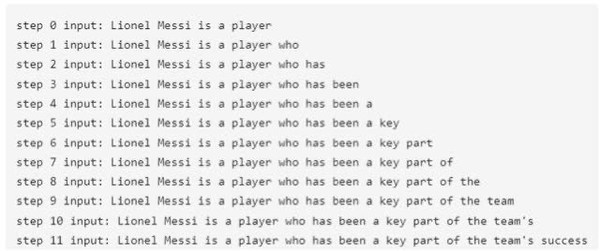
在介绍 kvcache之前,我们需要先了解生成式预训练模型(GPT)的生成机制。GPT 是泛指所有生成式语言模型,而非特指 OpenAI 的 GPT 产品。在生成句子时,GPT 采用逐个 token 的方式进行生成,而非一次性生成整个句子。如下图所示,例如模型的初始输入是 “Lionel Messi is a player”,将这句话送入模型后,模型预测下一个词为 “who”。接着,在第二阶段,将 “Lionel Messi is a player who” 输入模型,并再次进行推理,模型此时预测下一个词为 “has”。如此循环,逐步生成新词。整个过程将在预测结果中出现 “<eos>” 这个 token 时结束。
以下是自回归语言模型生成机制的简化版本代码:
while out_token != token_eos:
logits, _ = model(in_tokens)
out_token = torch.argmax(logits[-1, :], dim=0, keepdim=True)
in_tokens = torch.cat((in_tokens, out_token), 0)
text = tokenizer.decode(in_tokens)具体的原始代码可以在 Transformers 库源码中找到,路径为:transformers/src/transformers/generation/utils.py。这里提供的代码是简化版本,并且采用的是贪婪搜索方式来生成结果。在这个策略下,模型生成的结果没有随机性,它总会选择概率最高的 token,从而方便重现模型。
在上述代码中,“in_tokens” 是模型的输入,原始文本经过分词后,根据词汇表的映射关系,将转化为一串整数序列,即模型的输入。
“_logits, _ = model(in_tokens)” 这行代码代表模型对输入进行推理。模型输入经过处理后,通常会生成两部分内容,分别为 logits 和 kvcache。
我们假设模型的词汇表大小是46145,模型输入的token数量是10,batchsize为1,那么logits的shape是1*10*46145。(注意,上面的代码只是简化版本的代码,仅用于示例。在有些模型的代码中,模型输入经过一次推理后,得到的结果是hidden_state,假如模型的hidden_size是4096,那么模型的输出hidden_state的shape是1*10*4096,而非1*10*46145。hidden_state再经过一个线性层之后,变成了1*10*46145的矩阵,这便是logits)。
这个1*10*46145的logits应该怎么理解?除非你正在计算困惑度,否则前9行都是无意义的。第10行包含了 46145 个值,代表模型对下一个词的概率分布预测。在贪婪搜索策略下,我们选择概率最高的作为下一个词的预测。例如,在这 46145 个分量中,第 168 个分量的值最大,然后在词汇表中查找,如词汇表中第168个分量的 token 是 “big”,那么模型预测下一个词即为 “big”。
注意力掩码 (attention mask)
首先,我们来了解一下注意力矩阵。假设 hidden_size = 4096,batch_size = 1,输入长度为 10,注意力头数为 32,则q/k/v 矩阵的形状均为 1x32x10x128。在计算过程中,q 和 k 的转置(1x32x128x10)在后两个维度进行矩阵乘法,得到一个 1x32x10x10 的矩阵,这就是注意力矩阵。其中 32 代表注意力头数,10x10 描述了这句话中 10 个 token 之间,每两两个token的注意力情况。比如第三行第四列描述的是第三个token对于第四个token的注意力的情况。
注意力掩码在 Transformer 结构中会出现两次。首先是对输入的mask(这部分与本文主题关系不大,但不妨顺便介绍)。由于每个序列的长度不同,我们通常需要对较短的序列进行填充,使其长度与一个批次中最长的序列相同,以便进行并行计算。例如,设定某批次的语料长度为 10,但“团结就是力量”仅有 6 个 token,因此需要在后面进行填充操作,变为“团结就是力量<<pad>><<pad>><<pad>><<pad>>”。但是 <<pad>> 仅仅用于占位,没有实际意义,其他词不应对其产生注意力。因此,在计算注意力时,需要将其进行掩码处理。在被掩码处理之前,注意力矩阵 10x10 中的 100 个数值为正常值。经过掩码处理后,只有左侧 6 列的数值保持不变,剩余 4 列的数值变为 0。下面两张图分别显示了未经过mask以及经过了mask的注意力矩阵。

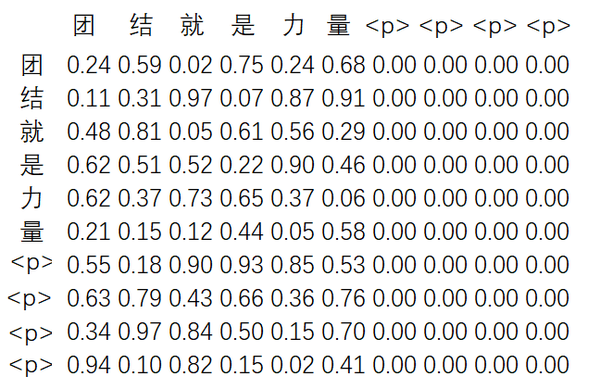
(严格来说,在大多数语言模型的实际应用场景中,一段语料的开头通常是由一个特殊的token:<s>符号来表示。这个符号与<pad>符号具有相同的性质,都属于特殊的token。其中,<s>符号代表语料的起始部分。)
第二次用到掩码的是在计算自注意力阶段。由于在生成一个新单词时,仅允许访问之前的上下文,不能查看该单词之后的信息。正如之前所提到的,GPT 的生成机制采用逐词生成方式。在生成阶段,模型不能看到后面的词语,因此需要通过设置注意力掩码来确保模型只关注当前位置之前的单词。
在 1x32x10x10 的注意力矩阵中,第一个 token 只能关注到自己,第二个 token 只能关注到第一个和第二个 token,以此类推。我们可以用一个上三角矩阵来表示这种关系。
下面展示了 attention_mask 的一个左上角小段示例,即方阵中前 3 行与前 3 列:
print(attention_mask[0,0,:3,:3])
tensor([[ 0.0000e+00, -3.4028e+38, -3.4028e+38],
[ 0.0000e+00, 0.0000e+00, -3.4028e+38],
[ 0.0000e+00, 0.0000e+00, 0.0000e+00]])在上述输出中,-3.4028e+38代表了float32数据类型中可能的最小数值,通常被视作负无穷大。在注意力计算中,这个值用于有效地屏蔽(或阻断)不相关的token,故而注意力模型只会专注于合理的、先行出现的token序列。
下图展示了经过了mask的注意力矩阵:

没有kvcache的情况下,推理过程的细节
上面已经详细讨论了GPT的生成机制以及注意力掩码(attention mask)。接下来,我们将探讨kvcache的作用和含义。
首先,我们来看看在缺少kvcache的情况下,推理过程的具体细节是怎样的。本节使用到的例子和图像来自于知乎用户
(文章链接:看图学:大模型推理加速:看图学KV Cache)。我推荐读者阅读这篇文章,我个人也是从这篇文章中,理解了kvcache的执行过程和作用。
在第一步,把<s>传递给模。在语言模型中,<s>一般代表一段语料的起始。
让我们再次回顾一下transformer的一次自注意力的运行过程。假设一个模型的hidden_size是4096,为了简化讨论,我们假设该模型没有使用多头注意力,即只有一个注意力头,并且我们在此过程中不考虑batchsize的维度。<s>经过嵌入(embedding)层后将转换为一个1x4096的tensor。接着,我们将这个tensor分别经过三个线性层,得到q/k/v,它们的形状都是1x4096。
在计算注意力的阶段,q和k的转置做矩阵乘积,这样就得到了注意力矩阵,shape是1x1。这个注意力矩阵表示了<s>这个token对于自己的注意力。接着,注意力矩阵再和v相乘,就得到了新的注意力表示,在本文中记为att矩阵,att矩阵的shape仍然是1x4096。(严格来说,需要对注意力矩阵施加一个基于scale的归一化的操作,为了简化讨论,我暂时忽略)
下面这张图细致地展示了该流程:

经过这一次自注意力的操作,得到了新的注意力表示:
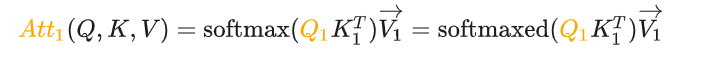
需要注意的是,以上所述仅为自注意力计算的一次过程。实际上,在基于transformer结构的模型中,通常会经历多次自注意力计算。
假设在单次推理过程中(这指的是模型通过所有层的过程,而非仅通过一个自注意力层),我们模型预测<s>的下一词为“遥”。根据GPT的生成机制,在第二个步骤,我们将"<s>遥"送入模型。此时,模型输入经过embedding层后,就会变成一个形状为2x4096的tensor。生成的q/k/v的形状也都是2x4096。q和k的转置进行矩阵乘法,就得到了一个形状为2x2的注意力矩阵。此时,由于mask机制,注意力矩阵右上角的元素将被设置为0。以下图像清晰地展示了这个过程:

从公式的角度来看,以上步骤的计算公式为:

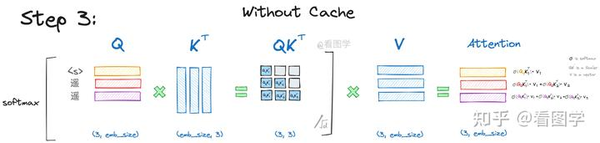
假设在此次推理过程中,模型最终预测出“遥”这个token。接下来,在第三个阶段,我们将"<s>遥遥"输入模型。具体细节在此不再赘述,以下图像展示了该过程:
其计算公式为:
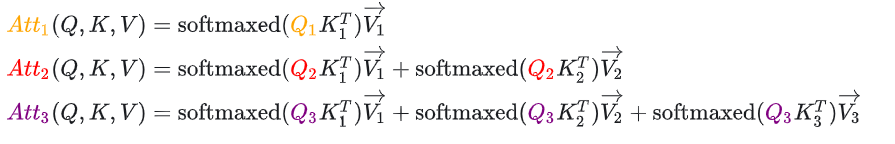 模型的输入为"<s>遥遥",包含3个token,shape是3x4096。att矩阵同样是3x4096,其每个位置都对应了预测输入位置下一词的信息。例如,att矩阵的第一行代表 "<s>"后面的token的预测信息。att矩阵的第二行,则代表 "<s>遥"后面的token的预测信息。
模型的输入为"<s>遥遥",包含3个token,shape是3x4096。att矩阵同样是3x4096,其每个位置都对应了预测输入位置下一词的信息。例如,att矩阵的第一行代表 "<s>"后面的token的预测信息。att矩阵的第二行,则代表 "<s>遥"后面的token的预测信息。
我们可以从公式中看出,第k个att(也就是att矩阵的第k行)只与第k个q有关,与前k-1个q无关。这就引出了一个问题:在推理的过程中是否能只将第k个token送进模型内?答案是否定的。因为尽管第k个att只与对应位置的q有关,但它却依赖于前k-1个token生成的k和v。
换种说法,每个token都会生成一个q向量,一个k向量和一个v向量。当我们计算第k个token对应的att时,尽管只会使用到第k个token的q向量,但需要用到前k-1个token的k向量和v向量。
因此,有研究人员想到,每次只需要将第k个token,以及之前的k和v送给模型,而不是将全部的k个token送进模型,不就更加高效吗?这就是kvcache的诞生原因。
换言之,在transformer中,k个token将产生k个q向量,k个k向量,和k个v向量。而由于我们只关心第k个token的下一个词,我们可以选择只将第k个token,以及前k-1个token的k向量和v向量送入模型,而无需将全部k个token输入模型。这样做将极大提高计算效率。
也就是说,在模型的第三阶段,我们原本需要将"<s>遥遥"送进模型,但现在我们可以仅仅只将"遥"以及之前"<s>遥"生成的k和v的值送入模型。
一些关于kvcache的疑问
为了更深入地理解kvcache,我们来看一个例子:在第三个阶段,如果我们将"<s>先遥"以及之前生成的k和v的值送入模型,会发生什么情况?答案是,没有任何影响。在第三个阶段,我们的目标是计算att的第三行,而前两行对这个阶段来说并无实际意义(除非你正在计算困惑度(perplexity))。有人可能会质疑,这只是一次自注意力的过程,大多数基于transformer结构的模型都会有多层自注意力。实际上,无论我们处在哪一个自注意力层,整个过程都只关注最后一个token。也就是说,无论前面的token(也就是除最后一个token外的其他token)是何种内容,都不会影响推理结果。因为k和v是直接传入模型的,而不是由前面的token生成的。
有人可能还会有一个疑问:对于transformer模型来说,我们仍然有线性层。这些线性层是否会将各行信息融合在一起?我的回答是,不会。尽管我在前文中强调了只需要计算att的第三行,而前两行并无实际意义,但经过mlp层后,信息并不会互相融合。我曾经有过类似的疑惑,但后来我发现我误解了transformer中的线性层。transformer中的线性层是针对hidden_size这个维度的变换,这并不会影响length维度,因此不同的token之间的信息并不会交互。在transformer模型中,token之间信息的交互只在自注意力层发生。
相同地,在Layernorm层也不会产生token之间的信息交互。在Layernorm中,每个token都是独立计算平方和。例如,第一个token对应的向量是4096,针对第一个token,我们计算这4096个数值的平方和,并除以4096,得到该token的平方平均数。最后,每个token再除以其各自的平方平均数。
有kvcache的情况下,推理过程的细节
在前文中,我们介绍了kvcache的原理:在每个推理阶段(假设当前为第k阶段)中,将第k个token以及前k-1个token生成的k和v送入模型。接下来,我们来讨论推理过程的细节。
让我们再从头开始梳理。在第一个阶段,把"<s>"送进模型,这一点和没有kvcache的情况是一致的。由于hidden_size是4096,因此q/k/v矩阵的shape都是1x4096。然后,我们提取出每一层的k向量和v向量,并作为模型的输出。对于kvcache,模型的输出格式是batchsize * 2 * layers * length * hidden_size。比如,在此例中,假设模型共有32层,那么模型输出的kvcache的形状就是1x2x32x1x4096。
进入第二阶段,在没有使用kvcache的情况下,我们会将"<s>遥"送入模型。但现在,我们使用kvcache的方法,将"遥"和形状为1x2x32x1x4096的kvcache一起送入模型。
在此阶段,"遥"这个token生成的k和v的形状依然是1x2x32x1x1x4096。和第一阶段生成的kvcache结合,我们得到形状为1x2x32x2x4096的kvcache,这就是此阶段的kvcache输出。
kvcache比较占用内存。如果模型已经输出了100个token,此时kvcache将会占用1x2x32x100x4096=26214400个数值。如果每个数值采用float32储存,一个float32类型占用了4个byte(字节),那么26214400 * 4 / 1024 / 1024 / 1024约等于100MB的储存空间。
转自:https://zhuanlan.zhihu.com/p/687020859


