DeepSeek-R1满血版推理部署和优化
- 大模型
- 2025-02-27
- 1264热度
- 0评论
前情回顾
比较现实的是两个极端, 一方面是各种平台的测评, 例如公众号“ CLUE中文语言理解测评基准”的
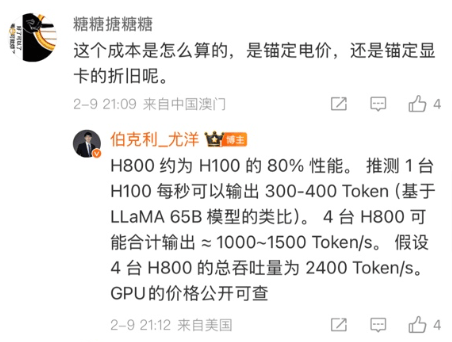
另一方面是尤洋老师在微博的一个评论MaaS的商业模式和平台推理亏损, 这里提到了4台H800的总吞吐量
另一方面是各种私有化部署的需求, 例如小红书上最近经常刷到

还有章明星老师的KTransformer可以在单卡的4090 24GB上配合Intel CPU的AMX部署Q4的量化版本. 通过将Routed Expert放置在CPU上运行来降低内存的使用量.
还有直接ollama找一个1TB内存的CPU实例就开跑的方案.
然后Benchmark的定义上,一会儿20 Tokens/s, 一会儿又是几千Tokens/s的benchmark满天飞, 到底是怎么回事? 其实有很多认知的问题, 让渣B回忆起刚毕业入职工作的时候做运营商级的电话信令网关时, 天天测性能算Erlang模型的日子...
推理性能指标概述
推理是一个在线业务, 因此对第一个Token出来的延迟(Time To First Token,TTFT)和后续token产生的延迟(Time Per output Token,TPOT)都会对用户体感产生影响.
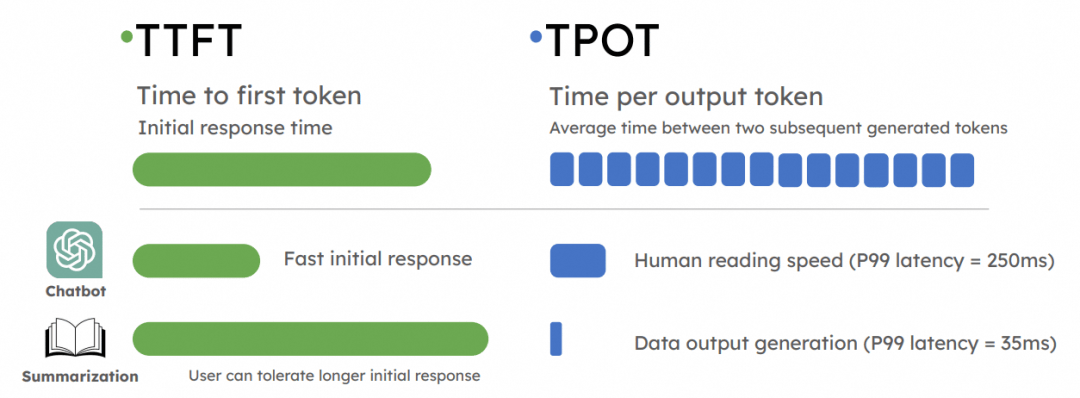
通常会使用测试工具生成如下一个报告, 具体数据就不多说了.
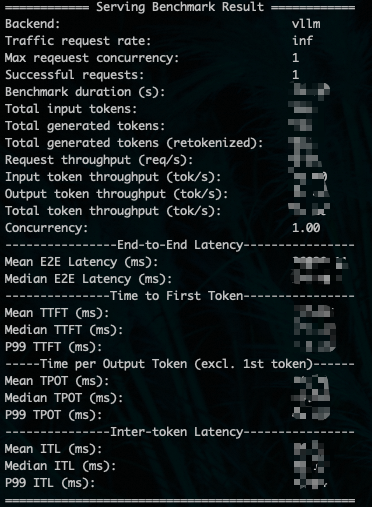
影响这个报告的因素很多, 例如测试工具是采用vllm的benchmark_serving还是采用sglang.bench_serving, 常用的参数是按照多少Request per seconds(RPS)测试或者按照多少并发量进行测试, 但是DeepSeek-R1的推理Reasoning时间很长, 通常都会选择并发数进行约束.测试在一定的并发数量下的吞吐/延迟等指标. 测试命令如下所示:
### vLLM的bench测试
python3 ~/vllm/benchmarks/benchmark_serving.py --backend vllm \
--model ~/deepseek-R1 --port 8000\
--dataset-name random \
--random-input 1234\
--random-output 2345\
--random-range-ratio 0.8\
--dataset-path ~/ShareGPT_V3_unfiltered_cleaned_split.json \
--max-concurrency 16\
--num-prompts 64
### sglangM的bench测试
python3 -m sglang.bench_serving --backend vllm \
--model ~/deepseek-R1 --port 8000\
--dataset-name=random --random-input= 1234\
--random-output= 2345\
--max-concurrency= 64\
--num-prompts= 128\
--random-range-ratio 0.9\
--dataset-path ~/ShareGPT_V3_unfiltered_cleaned_split.json
除了并发数max-concurrency以外, 另两个比较重要的参数是input多少token和output多少token, 这也是非常影响测试结果的. DeepSeek-R1作为一个Reasoning模型, 输出Thinking阶段的token也挺多的, 所以要根据实际的业务需要来进行分析.
因为以前长期做运营商级的呼叫信令网关, 对于请求到达是否按照Poisson过程, 对于结果的影响也很大, 这是一个非常重要的点, sglang的bench例如并发128时, 就是128个请求一起发出去了, 然后大家一起Prefill, 然后一起decode,这样可能导致TTFT偏长. 而vllm的测试是如果设置并发时是按照Poisson过程请求的. 但是似乎做的也不太符合真实的情况.
推理系统性能约束
主要的约束有几个方面:
用户SLA的约束
通常我们可以根据实际业务的需求获得平均输入Token数和输出Token数以及方差, 然后根据企业员工的数量或者承载用户的DAU计算出一个平均请求到达间隔, 然后根据一些SLA的约束, 例如TTFT首Token时间要小于4s, TPOT即用户感知的每秒token输出速度, 例如要大于20Token/S(TPS).然后再来估计用户平均对一个请求的整体持续时间, 通过Erlang模型建模.
但是很多时候性能和成本之间会有一些取舍, 例如是否在一个低成本方案中,放宽对TTFT和TPOT的要求, 慢一点但是足够便宜就好, 或者是另一方面例如袁老师的硅基流动, Pro版本就能够严格保证用户的SLA, 也就是夏Core讲的, 稳定保持TPOT > 20TPS、
但是为了保证API平台的SLA, 通常需要采用更复杂的并行策略, 降低延迟提高吞吐, 例如DeepSeek论文提到的EP320的 40台机器的集群方案.
内存的约束
对于较长的Context,KVCache对显存的占用也特别大, 虽然单机的H20显存也能放得下满血版的671B模型,但是剩余的显存也会约束到模型的并发能力. 通常有些提供API的厂家会配置一个截断, 例如最大长度就8192个Tokens. 通常在这种场景下为了提高并发, 最小配置都会用2台以上的H20, 或者一些MI300的实例, 国外还有一些会采用H200的实例.
约束带来的分叉
正如前一章节所属, 两个约束带来了分叉. 一方面用户希望低成本的私有化部署,带来了一些小型化部署的机会, 例如小红书上看到的, 200w如何私有化部署满血版. 另一方面是大规模的云平台提供服务的时候保障SLA.
这两者直接决定了部署上的区别:
私有化部署: 2台4台并行小规模满足成本的需求, 而不太在意TTFT和TPOT的需求, 能够满足企业内并发需求即可,甚至是季宇老师提到的一个极端的情况,就只做一个并发时, 如何用最低成本的硬件实现大概10~20TPS.
平台部署: 最小320卡到最大数千数万卡并行的需求, 这种需求下并发的请求数量, KVCache的用量和累计整个集群的TFTT和TPOT的约束都非常大, 因此需要在并行策略上进行更多的考虑, 例如EP并行还有PD分离等.
很多较小的提供商通常只有开源软件sglang和vllm的部署能力, 然后并行策略上只有非常局限的TP/PP选择, 因此只有2~4台机器并行一组的方式提供服务, 自然就会遇到一些成本过高,吞吐过低无法通过token收费挣钱的情况. 这也就是所谓的夹在中间非常难受的一个例子.
因此章明星老师讲的这两种部署带来的推理系统分叉将会成为一个必然趋势.
私有化部署
通常的做法是买两台H20或者在云上租用2台H20构建一个最小部署集, 然后自建的方式来部署.
基于SGLang
基于Sglang的部署方式如下, 两台机器安装sglang
pip install sgl-kernel --force-reinstall --no-deps
pip install "sglang[all]>=0.4.2.post3"--find-links https://flashinfer.ai/whl/cu124/torch2.5/flashinfer/
第一台机器执行时, nnodes=2, node-rank=0, dist-init-addr都是第一台机器的IP地址.
python3 -m sglang.launch_server \
--model-path ~/deepseek-R1/ \
--tp 16 --dist-init-addr 1.1.1.1:20000 \
--nnodes 2 --node-rank 0 \
--trust-remote-code --host 0.0.0.0 --port 8000
第二台机器执行时,--nnodes 2 --node-rank 1
python3 -m sglang.launch_server \
--model-path ~/deepseek-R1/ \
--tp 16 --dist-init-addr 1.1.1.1:20000 \
--nnodes 2 --node-rank 1 \
--trust-remote-code --host 0.0.0.0 --port 8000
需要注意的是,现阶段Sglang只支持TP并行, PP并行在未来几周可能会支持.
基于vLLM
vLLM需要基于Ray部署, 如下图所示:
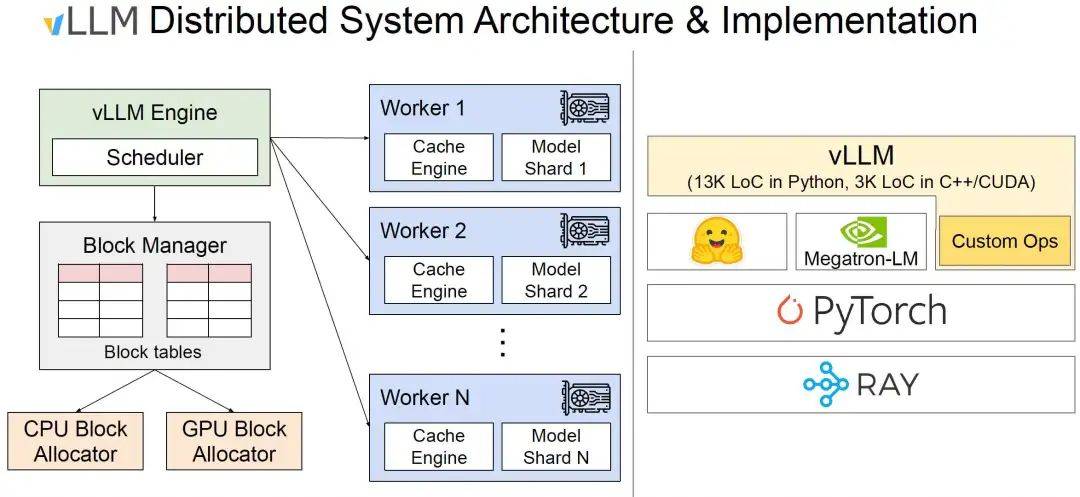
首先需要安装Ray
pip3 install ray
然后第一台机器配置
ray start --head --dashboard-host 0.0.0.0
第二个机器根据第一个机器的提示输入加入集群
ray start --address= '<first-node-ip>:6379'
然后检查集群状态
ray status
Node status
---------------------------------------------------------------
Active:
1 node_50018fxxxxx
1 node_11cc6xxxxx
Pending:
(no pending nodes)
Recent failures:
(no failures)
Resources
---------------------------------------------------------------
Usage:
0.0/256.0 CPU
0.0/16.0 GPU
0B/1.59TiB memory
0B/372.53GiB object_store_memory
Demands:
(no resource demands)
然后两台机器都安装vllm, 注意需要安装最新版的vllm 0.7.2性能有很大提升.
pip3 install vllm
最后在第一台机器上开启服务即可, 然后需要根据容忍的最大输入和模型输出调整max-num-batched-tokens和max-model-len
vllm serve ~/deepseek-R1 \
--tensor-parallel-size 16 \
-- enable-reasoning \
--reasoning-parser deepseek_r1 \
--max-num-batched-tokens 8192 \
--max-model-len 16384 \
-- enable-prefix-caching \
--trust-remote-code \
-- enable-chunked-prefill \
--host 0.0.0.0
单个输入的测试脚本如下
#test.py
fromopenai importOpenAI
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list
model = models.data[ 0].id
# Round 1
messages = [{ "role": "user", "content": "what is the presheaf? and how to prove yoneda lemma?"}]
response = client.chat.completions.create(model=model, messages=messages)
reasoning_content = response.choices[ 0].message.reasoning_content
content = response.choices[ 0].message.content
print( "reasoning_content:", reasoning_content)
print( "content:", content)
并行策略选择
如果选择sglang,当前只有TP并行策略, 因此需要为每个GPU配置400Gbps网卡构成双机3.2Tbps互联, 这是一笔不小的开销. 当然TP并行理论上说在Token generate的速度上会有优势, 但事实上和vLLM新版本的PP并行差距并不大. 相反TP并行的SGlang在Prefill阶段的性能还是有很大问题的, TTFT比起PP并行的vLLM很多场景下慢了一倍.
而vLLM更推荐PP并行, 主要是压根就不需要RDMA网络, 就CPU上插一张网卡即可, 同时KV Cache的容量和吞吐都有提升. 特别是KVCache, 比起TP并行省了很多, 对于私有化部署提高并发很有好处.
有一篇关于 vLLM 0.7.2优化的分析文章[1]其中提到

具体分析一下两种并行方式, PP并行也就是在模型的中间按层分开, 按照一个Token hidden-dim 7168和FP8计算, 如果每秒吞吐为1000个token, 则累积的带宽需求为7MB/s 即便是Prefill阶段需要5000tokens/s的能力,也就35MB/s, 一般一张100Gbps的网卡就够了.
而TP并行在Sglang中的实现是采用了对MLA进行DP并行, 每张卡维护不同Seq的KVCache, 并分别通过DP worker完成prefill/decode一类的任务, 从而相对于TP并行节省KVCache开销, 然后再进行一次allgather 让不同的卡都拿到hidden-state进行MoE的计算.
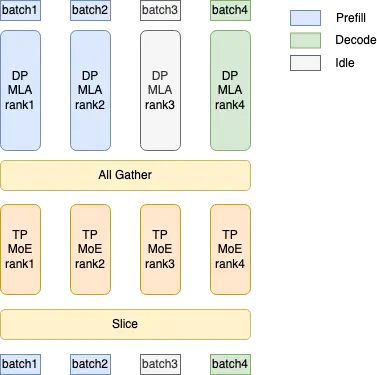
但是官方的 文档[2]似乎并没有开启这种模式, 而是采用标准的TP并行, 这样每个卡都要有全量的kvcache.
综合来看, 从私有化部署的成本来考虑, 选择vLLM或者未来支持pp并行的Sglang是一个更好的选择. 性能差距很小的情况下,省掉了一个专用的GPU RDMA网络的成本还是非常好的, 而且也适合企业部署, 随便找个机柜放两台, CPU的网卡接交换机上即可,无需特别的维护. 另一方面伴随着两三个星期以后两个框架都支持了MTP, 应该整体性能还有进一步的提升.
另外针对这样的小规模两机部署,通常会采用Chunk-Prefill的技术, 将Prefill的计算拆分成chunk穿插在Decode任务中, 来避免同一个卡运行Prefill和Decode时, 两阶段的资源争抢干扰会导致TTFT和TPOT都很难达到SLA的标准.
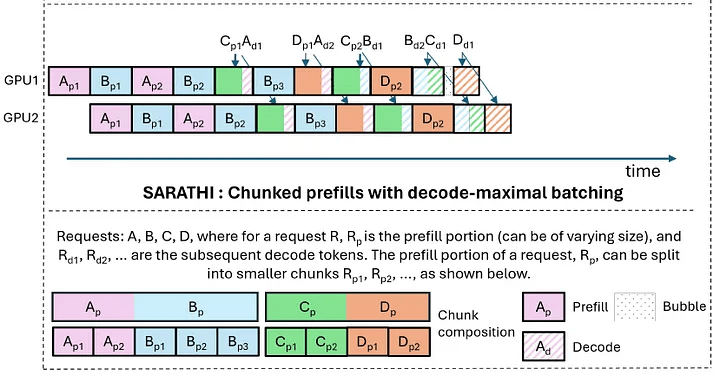
平台部署
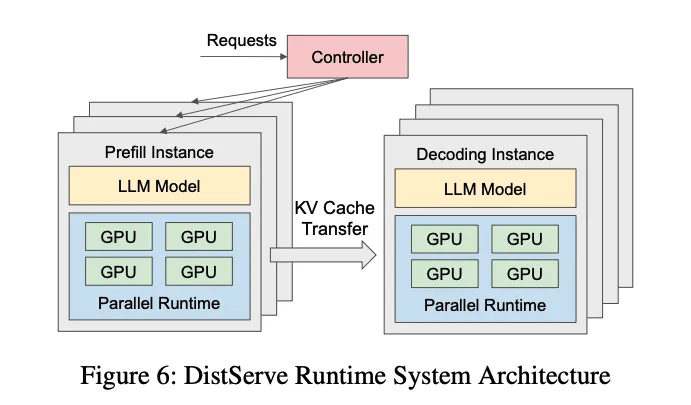
平台部署,更多的就要参考Deepseek-V3的论文了. DeepSeek首先采用了PD分离的技术.
PD分离技术
当Prefill和Decode两个阶段在同一个卡上运行时, 两阶段的资源争抢干扰会导致TTFT和TPOT都很难达到SLA的标准. 例如突然来一个很长的prompt的请求需要大量的计算资源来进行prefill运算, 同时也需要大量的显存来存储这个请求的KV Cache. 针对Prefill Compute-Bound计算和Decode Memory-bound计算的特点, 以及不同卡的算力差异, 出现了Prefill-Decode分离的架构, 即用高算力的卡做Prefill, 低算力的卡做Decode, 并且Prefill节点在完成计算传输KV Cache给Decode节点后就可以free掉本地显存.
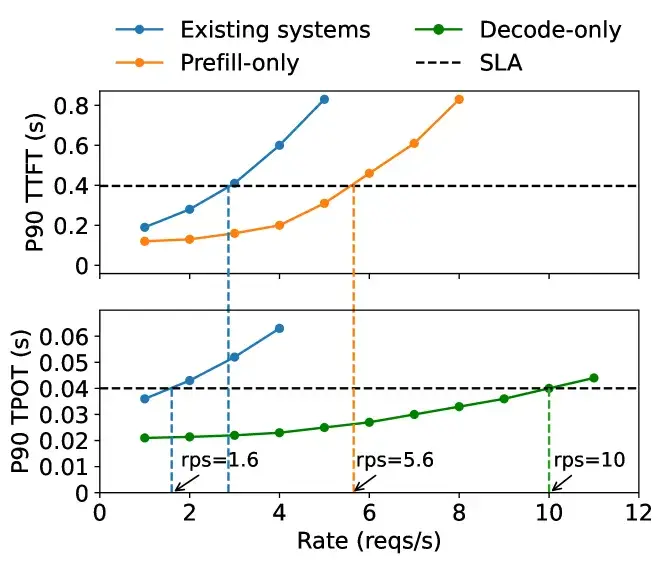
分离后的延迟和性能(来自论文DistServe), 可以看到在满足SLA的条件下, 分离后的性能会更好.
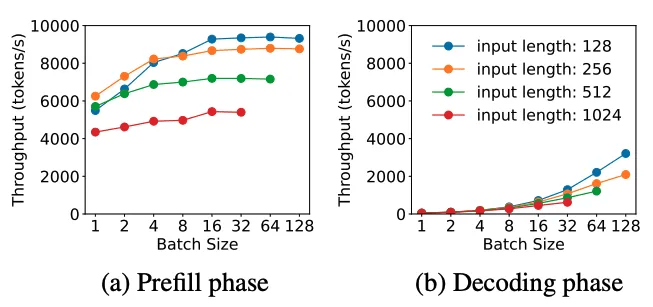
在PD分离架构下, 可以分别针对Compute-bound和Memory-bound进行有针对性的优化. 例如对请求的batch处理, Prefill阶段由于每个token都要计算,当batch中的总token数达到计算瓶颈门限后, 吞吐率就趋于平缓了. 而在Decode阶段随着batchsize增大可以显著的增加吞吐率
Prefill阶段
预填充阶段的最小部署单元由4个节点和32个GPU组成。
Attention block 采用4路张量并行(TP4)与序列并行(SP)结合,并辅以8路数据并行(DP8)。其较小的TP尺寸为4,限制了TP通信的开销。
对于MoE部分,使用32路专家并行(EP32),确保每个专家处理足够大的批量大小,从而提升计算效率。对于MoE的all-to-all通信,采用与训练时相同的方法:首先通过InfiniBand(IB)在节点间传输token,然后通过NVLink在节点内的GPU之间转发。
特别地,在最开始三层的 Dense MLP中使用1路张量并行,以节省TP通信开销。
为了实现MoE部分中不同专家之间的负载均衡,需要确保每个GPU处理大致相同数量的token。为此,引入了冗余专家的部署策略,通过复制高负载专家并冗余部署它们来达到这一目的。高负载专家是基于在线部署期间收集的统计数据检测出来的,并会定期调整(例如每10分钟一次)。在确定冗余专家集合后,会根据观察到的负载,在节点内的GPU之间精心重新安排专家,尽可能在不增加跨节点alltoall通信开销的情况下,实现GPU之间的负载均衡。在DeepSeek-V3的部署中,为预填充阶段设置了32个冗余专家。对于每个GPU,除了其原本负责的8个专家外,还会额外负责一个冗余专家。
此外,在预填充阶段,为了提高吞吐量并隐藏alltoall和TP通信的开销,采用了两个计算量相当的micro-batches,将一个micro ba t ch的Attention和MoE计算与另一个microbatch的Disptach和Combine操作overlap。
另外,论文还提到了他们正在探索动态的专家冗余策略, 即每个GPU负责更多的专家(例如16个专家),但在每个推理步骤中只激活其中的9个。在每一层的AlltoAll操作开始之前,动态计算全局最优的路由方案.
Decode阶段
在Decode阶段, 将Shared Expert和其它Routed Expert一视同仁. 从这个角度来看,每个token在路由时会选择9个专家,其中共享专家被视为一个高负载专家,始终会被选中。解码阶段的最小部署单元由40个节点和320个GPU组成。注意力部分采用TP4与SP结合,并辅以DP80,而MoE部分则使用EP320。在MoE部分,每个GPU仅负责一个专家,其中64个GPU专门用于托管冗余专家和共享专家。
需要注意的是, dispatch和combine部分的AlltoAll通信通过IB的直接点对点传输实现,以降低延迟。此外,还利用IBGDA技术进一步最小化延迟并提升通信效率,即直接利用GPU构建RDMA队列和控制网卡doorbell
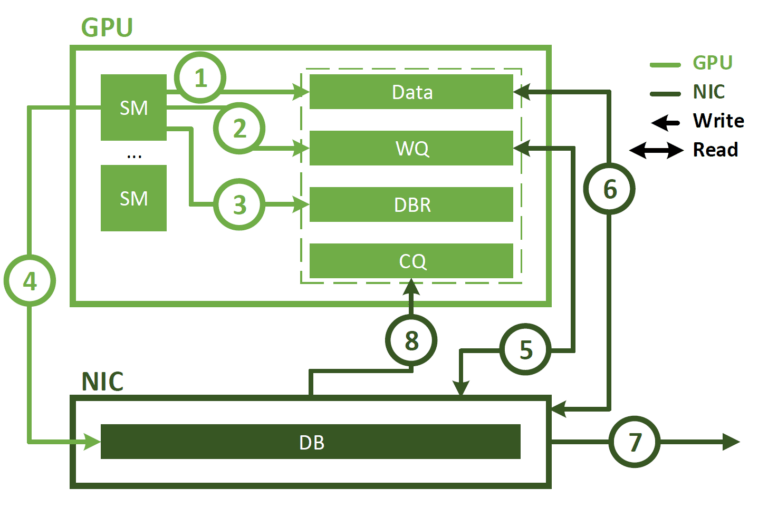
与Prefill阶段类似, 基于在线服务的统计专家负载,定期确定冗余专家的集合。然而,由于每个GPU仅负责一个专家,因此不需要重新安排专家的位置。同时也在探索解码阶段的动态冗余策略。不过,这需要对计算全局最优路由方案的算法以及与Dispatch Kernel的融合进行更细致的优化,以减少开销。
此外,为了提高吞吐量并隐藏AlltoAll通信的开销,还在探索在解码阶段同时处理两个计算工作量相似的microbatch。与预填充阶段不同,解码阶段中Attention计算占据了更大的时间比例。因此,需要将一个Microbatch的注意力计算与另一个microbatch的Dispatch+MoE+Combine操作Overlap。
在Decode阶段,每个专家的批量大小相对较小(通常在256个token以内),瓶颈在于内存访问而非计算。由于MoE部分只需加载一个专家的参数,内存访问开销极小,因此使用较少的SM不会显著影响整体性能。因此,为了避免影响Attention block的计算速度,可以仅为Dispatch+MoE+Combine分配一小部分SMs。
其实DeepSeek的工作已经做的非常细致了, 例如Prefill阶段通过两个microbatch来隐藏attention和MoE的A2A和TP通信开销. 并且通过冗余专家来降低Alltoall开销, 而在Decode阶段并没采用原来的训练中那样的PXN方式, 而是采用了直接p2p IB通信的方式, 并启用了IBGDA降低延迟. 对于一个大集群来看, 使用这些优化比起尤洋老师估计的每台机器400tokens/s的量, 应该起码高出20~50倍.
未来优化的方向和对开源生态的建议
私有化部署和平台部署将会带来推理生态的分叉, 在双机部署或者未来大内存的单机部署下, 可能更多的是考虑片上网络如何高效的互联, 例如带AMX的CPU来做MoE而辅助一些TensorCore做Attention Block, 例如GB200 NVL4这样的单机推理平台

或者就是极致的,像Apple M4那样的Unified Memory, 带一些NPU, 或者例如Project Digits那样的GB10的chip, 然后做到大概10万人民币能够完成满血版671B的部署, 这些单U的服务器或许也逐渐会成为云服务提供商的主力机型. 另一方面最近在做一些R1-Zero的复现和算法分析相关的事情, 觉得似乎这样的一些小规模集群对于强化学习RLFT也可能成为一个很好融合的机会. 例如4台~8台的小规模集群做一些垂域的模型蒸馏等, 这个市场会逐渐打开.
对于这些小机器, 内存通常受限的, 是否可以做一个双向加载?例如论文《Compute or Load KV Cache? Why not both?》采用了双向fill的机制, 从最后一个token开始倒着向前读取KV-Cache, 然后前向从第一个Token开始进行KVCache计算, 直到两个过程交汇.
而另一个方向, 是大集群的MaaS/SaaS服务提供, 通信和计算的Overlap,计算集群的负载均衡等, 当然首先还是要一些开源生态先去把一些EP并行框架的问题解决了才有后续, 当然我个人是一直比较看好vLLM+Ray的部署的, Ray本身和计算节点的负载以及内存的ojbect抽象其实蛮好的, 其实在看《Infinite-LLM: Efficient LLM Service for Long Context with DistAttention and Distributed KVCache》的工作, 在多个实例间共享内存实现分布式的KV-Cache存储.
还有一些很细致的内存管理的工作, 例如GMLake/vTensor等...进一步解决它的一些通信延迟后, 可能和其它在线业务融合是一个蛮大的优势.而另一方面Sglang也非常厉害, 前期性能超过vLLM很多.
更进一步,作为PaaS的基于SLA的调度还有很多工作和机会可以去做. 例如KVCache的存储和优化. 其实每个做推理的PaaS或许都应该下场参与到开源生态中, 例如当年的Spark.
当然还有一些更细节的内容涉密就不多说了, 宏观说几点吧....从算子层来看, Group GEMM的细粒度打满TensorCore, Warp specialization的处理, 如何统一ScaleUP和ScaleOut network, 如何更加容易的融入到现在的在线链路上? 然后这些RL模型是否可以逐渐做到按天的夜间FineTune白天上线快速迭代等?
最最后一条, 当前MoE性能的优化主要还是在AlltoAll, 优化的方式并不是说, ok, 因为延迟敏感需要一个更低延迟的网络通信, 而是如何通过一些microbatch等调度策略, 保证在一定通信延迟门限下能够足够的隐藏延迟.
举个例子吧, DeepSeek为什么Decode阶段要采用P2P直接RDMA通信,而不是像训练那样采用PXN呢? 其实在一定的SLA约束下, ScaleUP的带宽和延迟并不是那么极致的需求, 相反如何scaleOut, 才是关键. 这样就会导致一个潜在的问题, 例如采用Multi-Rail或者Rail-Only的组网,可能由于Expert的放置和过载, 需要跨越不同机器的不同Rank通信. IBGDA可能只是一个暂时的方案, 是否会因为这些新的需求, 又回到传统的CLOS架构, 放弃Rail-based部署呢? 特别是Decode阶段的延迟问题处理上, 假设未来部署的集群专家并行规模大幅度提升呢? 这就成为一个软硬件协同的很有趣的问题了, 建议算法团队和一些有硬件能力的团队更加紧密的合作, 算法对硬件妥协, 硬件进一步解锁...
再进一步, 正如DeepSeek论文所示, Dynamic Routing, Experts placement也是一个很有趣的话题. 而DeepSeek对于未来硬件的建议也非常清楚的摆在那里了, 后面随着推理的规模上量, 各个云之间卷推理成本而提高性能的事情