大模型核心概念科普:Token、上下文长度、最大输出,一次讲透
- admin
- AIGC
- 2025-03-20
- 3386热度
- 0评论
Token 是什么
token 是大模型(LLM)用来表示自然语言文本的基本单位,可以直观的理解为 “字” 或 “词”。
通常 1 个中文词语、1 个英文单词、1 个数字或 1 个符号计为 1 个 token
一般情况下模型中 token 和字数的换算比例大致如下:
- 1 个英文字符 ≈ 0.3 个 token。
- 1 个中文字符 ≈ 0.6 个 token。
所以,我们可以近似的认为一个汉字就是一个 token
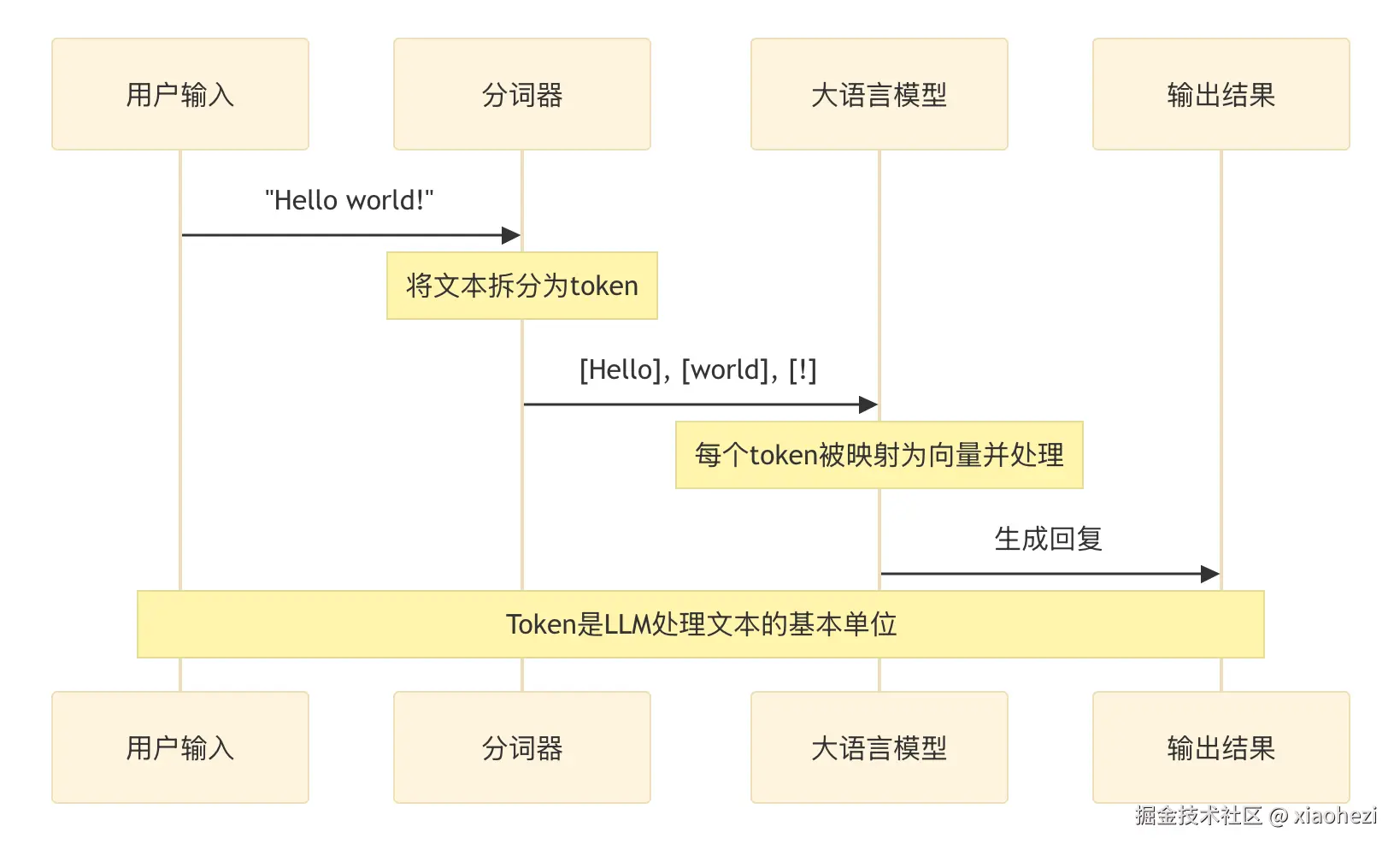
大模型处理我们的输入也是将文本转成 token 再处理的:
最大输出长度
这里我们以 DeepSeek 为例:

上图中 deepseek-chat 模型对应 DeepSeek-V3;deepseek-reasoner 模型对应 DeepSeek-R1
可以看到在 DeepSeek 中,无论是推理模型 R1 还是对话模型 V3 他们的最大输出长度均为 8K 。
我们已经知道一个汉字近似的等于一个 token ,那么这 8K 的意思就可以约等于说:一次输出最多不超过 8000 个字
最大输出长度这个概念非常清晰,很好理解,反正就是模型每次给你的输出最多 8000 个字,多了你就别想了,超限制了,人家做不到~~
上下文窗口
“上下文窗口” 在技术领域实际上有一个专有的名词:Context Window
上下文窗口是AI模型在生成回答时考虑的Token数量,反映模型信息捕捉能力。窗口越大,考虑信息越多,回答更相关连贯,提升模型表现。
GPT-4 Turbo 的上下文窗口高达128k Token,涵盖逾300页文本,显著提升其生成回复的上下文相关性和细腻度,为用户带来更为精准、深入的交互体验。
如果上面这个例子不够直观的话,可以再看一个例子。
LLM模型若设Context Window为5,处理句子“今天天气很好”时,针对“天气”这一Token,会融合“今天”与“很好”两Token的信息,从而精准捕捉“天气”的深层含义,实现高效智能的文本理解。
上下文长度
我们还是以 DeepSeek 为例:

可以看到无论是推理模型还是对话模型 Context length 都是 64K ,
这个 64K 意味着什么呢 ?请继续往下看。
如果我们要给 Context length 下一个定义,那么应该是这样:
LLM 的 Context length 指模型在单次推理过程中可处理的全部 token 序列的最大长度,包括:
- 输入部分(用户提供的提示词、历史对话内容、附加文档等)
- 输出部分(模型当前正在生成的响应内容)
这里我们解释一下,比如当你打开一个 DeepSeek 的会话窗口,开启一个新的会话,然后你输入内容,接着模型给你输出内容。这就是一个 单次推理 过程。在这简单的一来一回的过程中,所有内容(输入+输出)的文字(tokens)总和不能超过 64K(约 6 万多字)。
你可能会问,那输入多少有限制吗?
有。上文我们介绍了 “上下文长度”,我们知道最长 8K,那么输入内容的上限就是:64K- 8K = 56K
总结来说在一次问答中,你最多输入 5 万多字,模型最多给你输出 8 千多字。
你可能还会问,那多轮对话呢?每一轮都一样吗?
不一样。这里我们要稍微介绍一下多轮对话的原理
多轮对话
我们仍然以 DeepSeek 为例,假设我们使用的是 API 来调用模型。
多轮对话发起时,服务端不记录用户请求的上下文,用户在每次请求时,需将之前所有对话历史拼接好后,传递给对话 API。
以下是个示例代码,看不懂没关系就是示意一下:
python
from openai import OpenAI
client = OpenAI(api_key="<DeepSeek API Key>", base_url="https://api.deepseek.com")
# Round 1
messages = [{"role": "user", "content": "What's the highest mountain in the world?"}]
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages
)
messages.append(response.choices[0].message)
print(f"Messages Round 1: {messages}")
# Round 2
messages.append({"role": "user", "content": "What is the second?"})
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages
)
messages.append(response.choices[0].message)
print(f"Messages Round 2: {messages}")
在第一轮请求时,传递给 API 的 messages 为:
json
[
{"role": "user", "content": "What's the highest mountain in the world?"}
]
在第二轮请求时:
- 要将第一轮中模型的输出添加到 messages 末尾
- 将新的提问添加到 messages 末尾
最终传递给 API 的 messages 为:
json
[
{"role": "user", "content": "What's the highest mountain in the world?"},
{"role": "assistant", "content": "The highest mountain in the world is Mount Everest."},
{"role": "user", "content": "What is the second?"}
]
所以多轮对话其实就是:把历史的记录(输入+输出)后面拼接上最新的输入,然后一起提交给大模型。
那么在多轮对话的情况下,**实际上并不是每一轮对话的 Context Window 都是 64K,而是随着对话轮次的增多 Context Window 越来越小。**比如第一轮对话的输入+输出使用了 32K,那么第二轮就只剩下 32K 了,原理正如上文我们分析的那样。
到这里你可能还有疑问 🤔 :不对呀,如果按照你这么说,那么我每轮对话的输入+输出 都很长的话,那么用不了几轮就超过模型限制无法使用了啊。可是我却能正常使用,无论多少轮,模型都能响应并输出内容。
这是一个非常好的问题,这个问题涉及下一个概念,我把它叫做 “上下文截断”
上下文截断
在我们使用基于大模型的产品时(比如 DeepSeek、智谱清言),服务提供商不会让用户直接面对硬性限制,而是通过 “上下文截断” 策略实现“超长文本处理”。
举例来说:模型原生支持 64K,但用户累计输入+输出已达 64K ,当用户再进行一次请求(比如输入有 2K)时就超限了,这时候服务端仅保留最后 64K tokens 供模型参考,前 2K 被丢弃。对用户来说,最后输入的内容被保留了下来,最早的输入(甚至输出)被丢弃了。
这就是为什么在我们进行多轮对话时,虽然还是能够得到正常响应,但大模型会产生 “失忆” 的状况。没办法,Context Window 就那么多,记不住那么多东西,只能记住后面的忘了前面的。
这里请注意,“上下文截断” 是工程层面的策略,而非模型原生能力 ,我们在使用时无感,是因为服务端隐藏了截断过程。
到这里我们总结一下:
- 上下文长度(如 64K)是模型处理单次请求的硬限制,输入+输出总和不可突破;
- 服务端通过上下文截断历史 tokens,允许用户在多轮对话中突破
Context length限制,但牺牲长期记忆 - 上下文窗口限制是服务端为控制成本或风险设置的策略,与模型能力无关
各模型参数对比
各模型厂商对于 最大输出长度和上下文长度的参数设置是不一样的,我们以 OpenAI 和 Anthropic 为例,概览一下:

上图中,Context Tokens 就是上下文长度,Output Tokens 是最大输出长度。
技术原理
为什么要有这些限制呢?从技术的角度讲比较复杂,我们简单说一下,感兴趣的可以顺着关键词再去探索一下。
在模型架构层面,上下文窗口是硬性约束,由以下因素决定:
-
位置编码的范围:
Transformer模型通过位置编码(如 RoPE、ALiBi)为每个 token 分配位置信息,其设计范围直接限制模型能处理的最大序列长度。 -
自注意力机制的计算方式:生成每个新
token时,模型需计算其与所有历史token(输入+已生成输出) 的注意力权重,因此总序列长度严格受限。KV Cache 的显存占用与总序列长度成正比,超过窗口会导致显存溢出或计算错误。
典型场景与应对策略
既然知道了最大输出长度和上下文长度的概念,也知道了它们背后的逻辑和原理,那么我们在使用大模型工具时就要有自己的使用策略,这样才能事半功倍。
-
短输入 + 长输出
- 场景:输入 1K tokens,希望生成长篇内容。
- 配置:设置 max_tokens=63,000(需满足 1K + 63K ≤ 64K)。
- 风险:输出可能因内容质量检测(如重复性、敏感词)被提前终止。
-
长输入 + 短输出
- 场景:输入 60K tokens 的文档,要求生成摘要。
- 配置:设置 max_tokens=4,000(60K + 4K ≤ 64K)。
- 风险:若实际输出需要更多 tokens,需压缩输入(如提取关键段落)。
-
多轮对话管理
规则:历史对话的累计输入+输出总和 ≤ 64K(超出部分被截断)。
示例:
- 第1轮:输入 10K + 输出 10K → 累计 20K
- 第2轮:输入 30K + 输出 14K → 累计 64K
- 第3轮:新输入 5K → 服务端丢弃最早的 5K tokens,保留最后 59K 历史 + 新输入 5K = 64K。