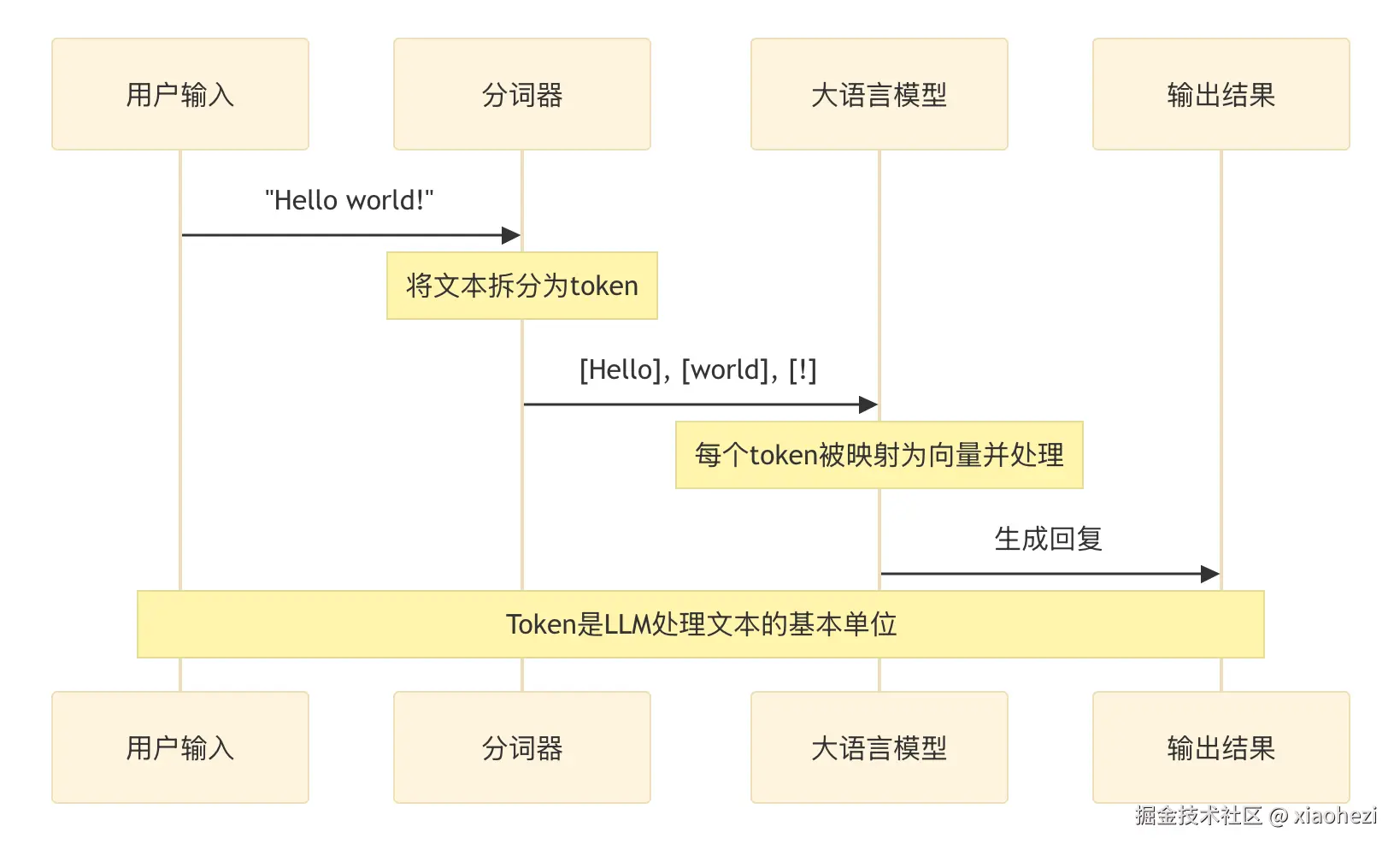
vllm serve的参数大全及其解释
- 大模型
- 2025-03-03
- 2228热度
- 0评论
以下是 vllm serve 的常见参数说明以及它们的作用:
1. 基本参数
model_tag
说明:用于指定要加载的模型,可以是 Hugging Face 模型仓库中的模型名称,也可以是本地路径。
示例:
vllm serve "gpt-neo-2.7B"
--config CONFIG
说明:允许从 YAML 配置文件加载参数。适合复杂配置。
示例:
vllm serve "gpt-neo-2.7B" --config /path/to/config.yaml
--host HOST 和 --port PORT
说明:设置服务运行的主机地址和端口。
默认值:host=127.0.0.1,port=8000
示例:
vllm serve "gpt-neo-2.7B" --host 0.0.0.0 --port 8080
2. 模型加载与优化
--tensor-parallel-size
说明:设置 Tensor 并行的数量(多 GPU 分布式推理)。
示例:
--tensor-parallel-size 8
--cpu-offload-gb
说明:允许将部分模型权重或中间结果卸载到 CPU 内存中,模拟 GPU 内存扩展。
默认值:0(禁用 CPU 卸载)。
示例:
--cpu-offload-gb 128
--gpu-memory-utilization
说明:指定 GPU 内存利用率,值为 0-1 的小数。
默认值:0.9
示例:
--gpu-memory-utilization 0.8
--max-model-len
说明:模型的最大上下文长度(序列长度)。
示例:
--max-model-len 16384
--max-num-batched-tokens
说明:每批次处理的最大 token 数量。适用于优化吞吐量。
示例:
--max-num-batched-tokens 60000
--dtype
说明:设置数据类型,通常用于控制权重和激活值的精度。
float32:32位浮点数(精确但消耗内存)。
float16:16位浮点数(推荐)。
bfloat16:16位浮点数(适合 NVIDIA A100 等设备)。
示例:
--dtype float16
3. 日志与调试
--uvicorn-log-level
说明:控制 uvicorn Web 服务器的日志级别。
选项:debug, info, warning, error, critical, trace
示例:
--uvicorn-log-level debug1.
--disable-log-stats
说明:禁用统计日志,减少性能开销。
示例:
--disable-log-stats
--disable-log-requests
说明:禁用请求的日志记录。
示例:
--disable-log-requests
4. 分布式设置
--distributed-executor-backend
说明:设置分布式推理的执行后端。
选项:ray, mp(多进程)
默认值:ray(如果安装了 Ray)
示例:
--distributed-executor-backend ray
--pipeline-parallel-size
说明:设置流水线并行的阶段数量。
示例:
--pipeline-parallel-size 4
5. 前端与安全
--api-key
说明:启用 API 访问控制,客户端需提供此密钥。
示例:
--api-key my_secure_api_key
--ssl-keyfile 和 --ssl-certfile
说明:配置 HTTPS 证书,启用安全通信。
示例:
--ssl-keyfile /path/to/keyfile.pem --ssl-certfile /path/to/certfile.pem
--disable-fastapi-docs
说明:禁用 FastAPI 的 OpenAPI 文档(Swagger UI)。
示例:
--disable-fastapi-docs
6. 调度与优化
--swap-space
说明:每个 GPU 的 CPU 换页空间(GiB)。
示例:
--swap-space 8
--max-num-seqs
说明:每次迭代的最大序列数量,适合控制吞吐量。
示例:
--max-num-seqs 16
--enable-prefix-caching
说明:启用前缀缓存以减少重复计算。
示例:
--enable-prefix-caching
7. 特殊用途参数
--quantization
说明:设置量化方法,减少内存占用。
选项:
bitsandbytes:8位量化(推荐)。
fp8:FP8(需要支持 FP8 的设备)。
示例:
--quantization bitsandbytes
--enable-lora
说明:启用 LoRA(低秩适配器)功能。
示例:
--enable-lora
示例命令
结合以上参数的一个完整示例:
vllm serve "defog/sqlcoder-70b-alpha" \
--tensor-parallel-size 8 \
--cpu-offload-gb 128 \
--gpu-memory-utilization 0.9 \
--max-model-len 16384 \
--max-num-batched-tokens 60000 \
--uvicorn-log-level debug
如需进一步调整,请参阅 vLLM 官方文档。