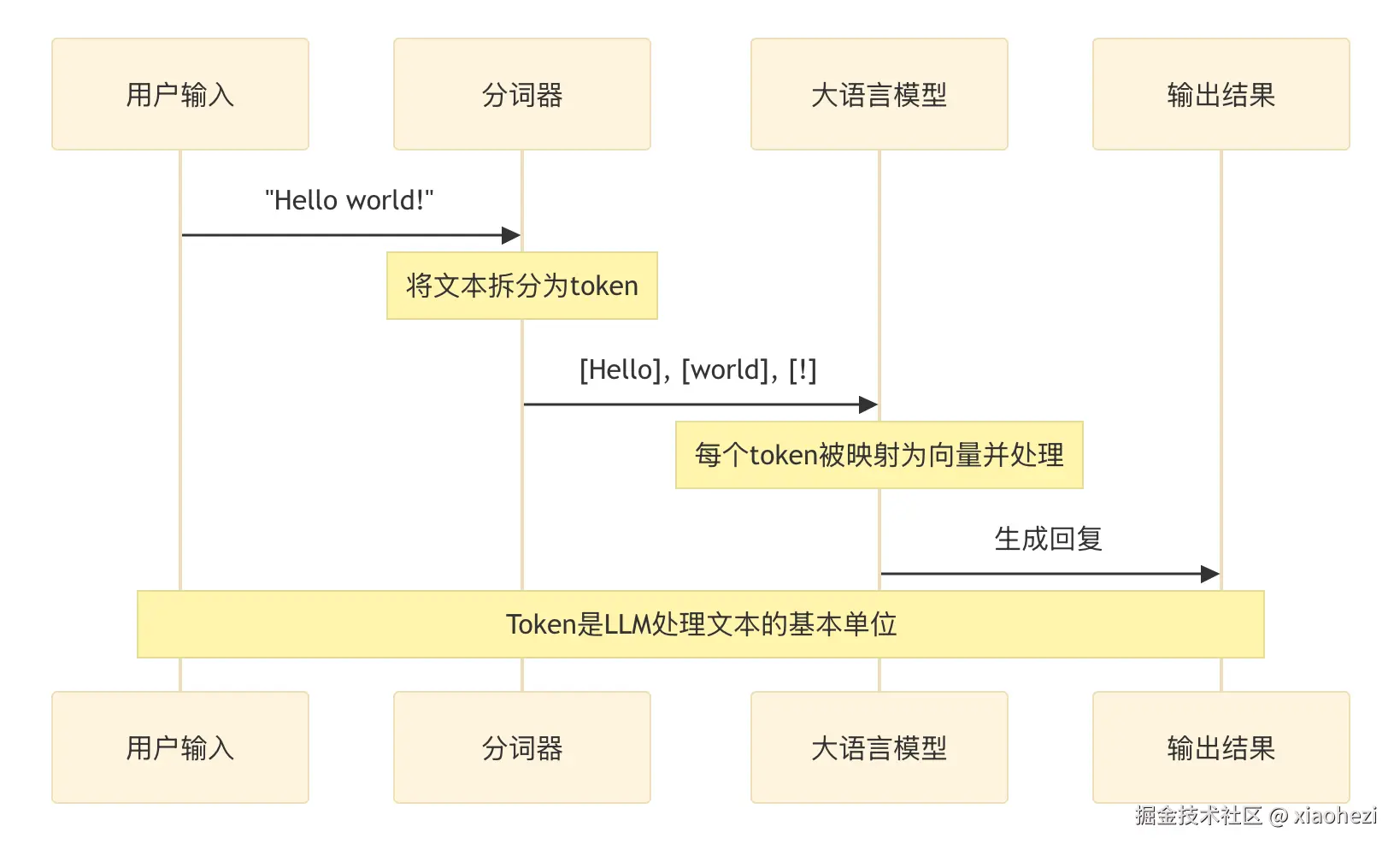
详细分析大模型推理为什么要PD分离-看完本文就明白!
- admin
- 大模型
- 2025-09-22
- 370热度
- 0评论
15
一、背景:大模型推理的两大阶段
| 阶段 | 主要工作 | 资源特征 |
|---|---|---|
| Prefill(全量填充) | 把用户的完整 Prompt(数百到数千 token)一次性送入 Transformer,计算出对应的 Key‑Value(KV)Cache 并生成第一个 token。 | 计算密集型(矩阵乘法占主导),对显存需求相对较小,但对算力(GPU/ NPU)利用率要求高。 |
| Decode(增量解码) | 依据上一步的输出 token,逐 token 读取已有 KV Cache 并生成后续 token。 | 访存/带宽密集型(每个 token 只做一次注意力查询),显存占用随上下文长度线性增长,单 token 计算量很小,容易出现算力利用率低下的瓶颈。 |
这两阶段的 计算‑访存特性截然不同,如果把它们放在同一套机器上共同竞争资源,往往会导致:
- Prefill 抢占算力 → Decode 的带宽需求被压制,导致 TBT(Token‑to‑Token 延迟) 增大。
- Decode 抢占显存/带宽 → Prefill 的算力利用率下降,TTFT(Time‑to‑First‑Token) 变慢。
因此,业界提出 PD(Prefill‑Decode)分离——把两阶段分别部署在不同的硬件资源上,以实现资源的“负载分离”。
二、PD 分离的核心原理
-
资源异构化
- Prefill 节点:使用计算密集型的 NPU/GPU(如华为 Ascend 910)并配备足够的算力,但显存可以相对小。
- Decode 节点:使用访存带宽更大的卡或多卡并行,显存容量更大,以容纳长 KV Cache 并支持大 batch‑size 的增量推理。
-
KV Cache 跨节点传输
- Prefill 完成后,把 KV Cache(Key、Value) 通过 零拷贝 D2D / D2H‑H2D 或专用 LLM‑DataDist 链路传输到 Decode 节点。
- 传输过程采用 块(block)或分页(paged) 方式,配合 PagedAttention / KV Cache Transfer,保证带宽利用率并避免全量拷贝。
-
调度与配比
- 通过 Scheduler/Controller 动态决定 Prefill 与 Decode 节点的比例(如
default_p_rate、default_d_rate),在业务负载变化时自动伸缩。 - 采用 Continuous Batching(Decode 端的多请求合批)提升吞吐,同时保持 TTFT 的低延迟。
- 通过 Scheduler/Controller 动态决定 Prefill 与 Decode 节点的比例(如
-
跨集群/边缘‑云协同(可选)
- 将 Prefill 前几层或全部放在边缘节点,Decode 的后层放在云端,利用 Split Learning 与 KV Cache 复用 实现数据隐私与算力弹性。
三、主流实现方案
| 系统/文档 | 关键技术点 | 参考来源 |
|---|---|---|
| MindIE(华为) | 将 Prefill 与 Decode 实例化为独立容器,调度器负责 KV Cache 的点对点传输;支持手动/自动配比调优(default_p_rate、default_d_rate) |
|
| CANN LLM‑DataDist | 提供 Prefill Node 与 Decode Node 之间的 KV Cache 传输、块表(block_table)管理、零拷贝 D2D/H2D 机制 | |
| DistServe(北京大学等) | 通过 Prefill 实例 与 Decode 实例 分离,使用 KV Cache Transfer 进行跨实例通信,调度器实现 Goodput‑优化 | |
| Nexus / Proactive Intra‑GPU Disaggregation | 在单卡内部主动划分计算/访存资源,实现 Prefill‑Decode 动态调度,显著提升 GPU 利用率与吞吐 | |
| Splitwise / PIC 分离(业界报告) | 将 Prefill 与 Decode 部署到异构集群,实现负载分离,提升整体吞吐 | |
| Mooncake(KV‑Cache‑centric) | KV Cache 扩展至 SSD,配合 PD 分离实现 TB 级缓存,缓解显存压力 |
四、PD 分离带来的主要收益
- 吞吐提升
- 通过在 Decode 端增大 batch‑size(因为显存足够),整体 Goodput 可提升 2‑5 倍(如 DistServe 实验)
- 延迟优化
- Prefill 仍保持单请求、低 TTFT;Decode 采用 Continuous Batching,在保持低 TBT 的同时提升并发。
- 资源利用率均衡
- 计算密集型算力集中在 Prefill,访存/带宽资源集中在 Decode,避免资源争抢导致的“瓶颈交叉”。
- 弹性伸缩
- 业务高峰时可水平扩展 Decode 节点(显存/带宽),而 Prefill 节点保持相对固定,降低成本。
- 支持超长上下文
- KV Cache 可在 Decode 节点上使用 PagedAttention、多级 KV Cache(显存→RAM→SSD),实现 100 K‑1 M token 级别的上下文,而不受单卡显存限制。
五、实现时的关键挑战与对策
| 挑战 | 说明 | 常见对策 |
|---|---|---|
| KV Cache 传输开销 | Prefill 完成后需要把数百 MB‑GB 的 KV Cache 送到 Decode。 | 使用 零拷贝 D2D、块化分页(PagedAttention)以及 高速 PCIe/InfinityFabric;在传输期间进行 异步调度,隐藏延迟 |
| 调度与配比 | 不同业务的 TTFT 与 TBT 需求差异大,固定配比可能导致资源浪费。 | 引入 自动配比算法(基于实时负载、GPU 利用率)或 在线调度(如 DistServe 的放置算法) |
| 一致性与容错 | KV Cache 跨节点失效会导致推理错误或回滚。 | 采用 可靠的链路管理(LLM‑DataDist 提供的 D2D/H2D 可靠传输)并在 Scheduler 中实现 重试/回滚 机制 |
| 跨集群/边缘‑云协同 | 网络带宽与安全限制可能影响 KV Cache 迁移。 | 采用 Split Learning 将前几层放在边缘,后层在云端,边缘仅保留 KV Cache,降低跨网传输量 |
| 硬件异构兼容 | 不同厂商的 NPU/GPU 接口差异。 | 通过 统一的 DataDist 接口(CANN、MindSpore)抽象底层传输,实现跨平台部署。 |
六、实践要点(部署建议)
- 明确业务指标:先确定 TTFT(交互式)与 TBT(批量)占比,决定 Prefill 与 Decode 的节点配比。
- 选型硬件:
- Prefill:算力强、显存适中(如 Ascend 910、A100)。
- Decode:显存大、带宽高(如 A100 80 GB、H100),或多卡并行。
- 使用成熟框架:MindIE、CANN DataDist、DistServe、Nexus 等均提供 Scheduler + KV Transfer 的完整实现,建议直接基于这些框架进行二次开发。
- 开启 KV Cache 分页:在 Decode 端启用 PagedAttention 或 多级 KV Cache(显存→RAM→SSD),防止显存 OOM。
- 监控与自动调优:实时监控 GPU 利用率、PCIe 带宽、KV Cache 传输时延,结合 自动配比(
default_p_rate/default_d_rate)动态调整节点数。 - 容错设计:为 KV Cache 传输加入 ACK/重传,并在 Scheduler 中实现 故障节点剔除 与 请求回滚。
七、结论
PD 分离是一种 系统级、资源异构化 的优化思路,核心在于把 计算密集的 Prefill 与 访存密集的 Decode 分别放在最适合的硬件上,并通过 高效的 KV Cache 传输 与 智能调度 实现两者的协同工作。它能够显著提升大模型推理的 吞吐、延迟与显存利用率,并为 超长上下文、弹性伸缩 与 边缘‑云协同 提供技术支撑。当前已有 华为 MindIE、CANN DataDist、DistServe、Nexus、Splitwise 等成熟实现,企业在部署大模型服务时可直接选用或在其基础上进行定制,以满足不同业务场景的性能与成本需求。