Post Views: 35 简介 FormulaEase 是一款面向大众的免费 AI 电子表格公式生成工具,专门为不熟悉函数语法的办公用户打造。无论是 Excel 还是 Google Sheets 用户,只需用日常语言描述清楚计算需求,AI 就能自动输出精准可用的完整公式。全程无需上传本地表格文件,也不用注册登录账号,每位用户每天可免费使用 3 次 AI 生成服务,足以覆盖日常办公中绝大多数公式
Post Views: 249 在人工智能技术迭代的狂飙时代,行业目光往往聚焦于参数规模的扩张——更大、更强、更快的暴力美学。然而,月之暗面(Moonshot AI)最新开源的 Kimi K2.6,却以一种截然不同的路径,向业界展示了 AI 进化的另一种可能:从追求极致的单体智能,转向追求高效的集群协作。 ▍核心进化:从“天才大脑”到“高效组织” Kimi K2.6 的核心突破在于其对“Agent
Post Views: 289 简介 如果你关注AI绘图圈,那么肯定听说过Midjourney。它是目前最火爆、最好用的AI画图工具。不管你是做概念设计、品牌插画、游戏美术,还是单纯喜欢玩创意,Midjourney都能帮你轻松搞定。你只需要在Discord里输入几句话,AI就能在几秒钟内生成高质量、风格多变的图片。它不仅速度快、门槛低,而且支持各种艺术风格、分辨率和细节调整,连专业设计师都赞不绝口
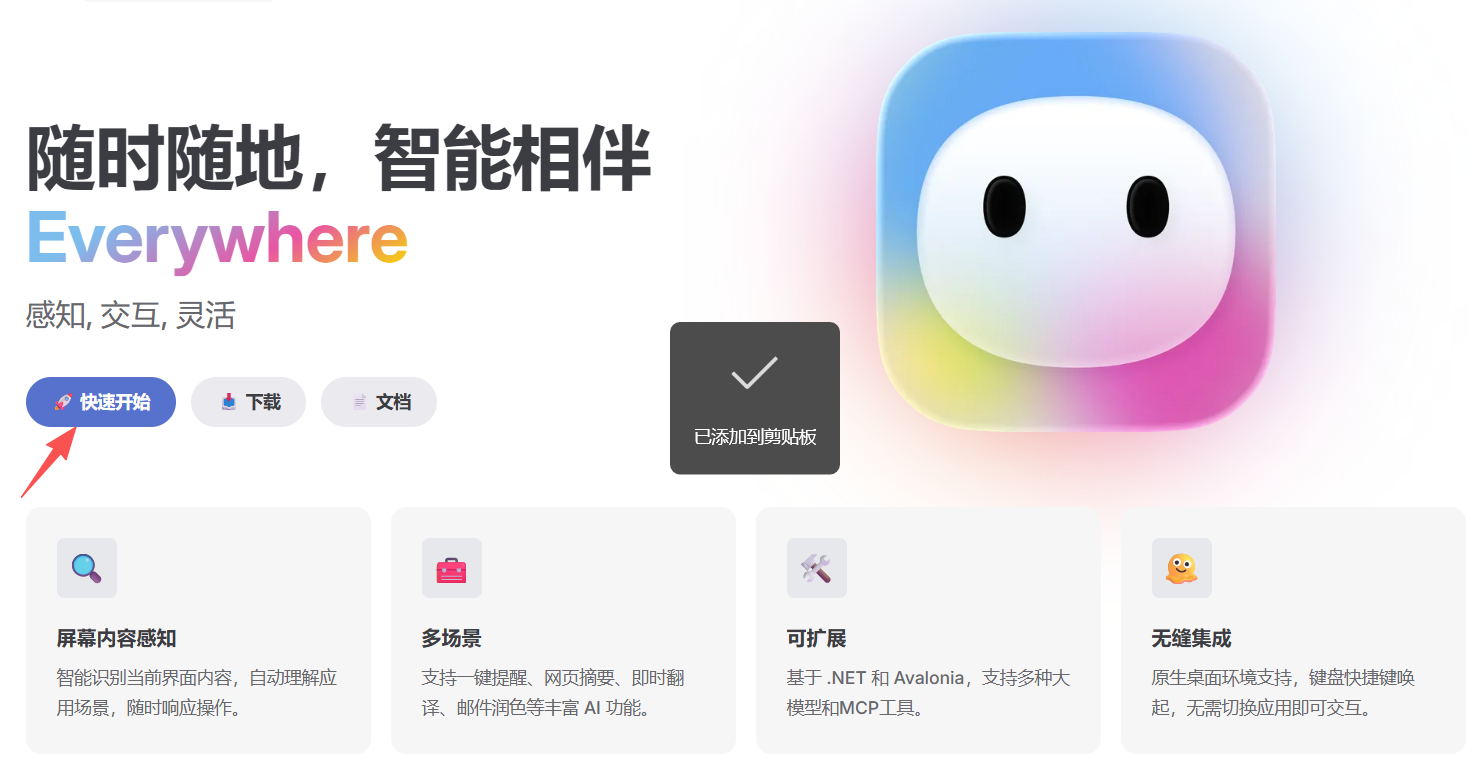
Post Views: 110 安装简介 Everywhere 作为一款独具创新的上下文感知 AI 助手,致力于为用户提供无缝衔接的智能支持。与传统 AI 工具大不相同,它拥有独特的感知能力,能即时洞察并理解用户屏幕上呈现的内容。用户无需进行截图、复制或切换应用程序等繁琐操作,仅需按下快捷键,就能迅速获得所需的帮助,为工作和生活带来极大便利。 功能特性 高效任务处理 Everywhe