
标签 deepspeed 下的文章
众所周知,大模型的训练需要大量的显存资源,单卡很容易就爆了,于是就有了单机多卡、多机多卡的训练方案。本文主要是介绍如何使用deepspeed框架做多机多卡的分布式训练。由于PyTorch、NVIDIA、CUDA等运行环境搭建也是很繁琐...
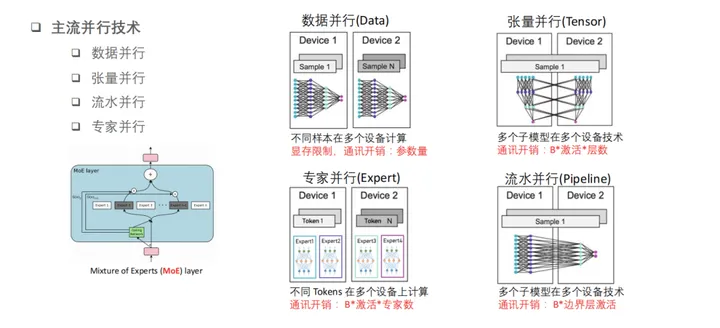
一,背景知识1.1,LLM 应用的难点1,模型训练时间过长伴随着 Transformer 结构的提出,后续 LLM 参数开始从亿级到百亿、乃至万亿级增长,与超高速增长到模型参数量相比, GPU 显存的增长实属有限,有数据显示每 18 ...