众所周知,大模型的训练需要大量的显存资源,单卡很容易就爆了,于是就有了单机多卡、多机多卡的训练方案。本文主要是介绍如何使用deepspeed框架做多机多卡的分布式训练。

由于PyTorch、NVIDIA、CUDA等运行环境搭建也是很繁琐,所以这次我们用docker来快速搭建,但是deepspeed多机训练是通过ssh来通讯的,不同服务器的docker容器通讯是个麻烦事。还好,docker可以创建overlay网络来解决这个问题。
1. 创建overlay共享网络
假设我们有两台主机,均已经在宿主机上安装完docker、NVIDIA的驱动。
- server1: 10.0.18.1
- server2: 10.0.18.2
宿主机的ip不太重要,我们需要的是能跨网的容器间ip,让它们能跨服务器间通讯。docker官方的overlay-network有详细的使用方法,下面是复现步骤,注意命令是分别在不同的节点上执行的:
1. 初始化集群
我们选择 server1 作为 manager 节点,在此服务器上执行初始化命令:docker swarm init
$ docker swarm init
Swarm initialized: current node (vz1mm9am11qcmo979tlrlox42) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-5g90q48weqrtqryq4kj6ow0e8xm9wmv9o6vgqc5j320ymybd5c-8ex8j0bc40s6hgvy5ui5gl4gy 10.0.18.1:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.2. 加入集群
将 server2 作为 worker 节点加入集群,进入 server2 执行下面join命令:
$ docker swarm join --token SWMTKN-1-5g90q48weqrtqryq4kj6ow0e8xm9wmv9o6vgqc5j320ymybd5c-8ex8j0bc40s6hgvy5ui5gl4gy 10.0.18.1:23773. 创建网络
在 manager 中创建 overlay 网络,执行命令:
$ docker network create --driver=overlay --attachable test-net
uqsof8phj3ak0rq9k86zta6ht执行命令查看当前网络状态,可以看到最后一行,已经创建好了
[root@i-spxeloti ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
873253604b76 bridge bridge local
983eae14396c docker_gwbridge bridge local
720dada15466 host host local
z8hpu4pg07m7 ingress overlay swarm
2f209b7ceaf6 none null local
un6gq3jb0jy9 test-net overlay swarm4. 同步网络
接着进入 worker 节点执行命令查看会发现,看不到上一步创建的网络
[root@i-sboq81f6 code]# docker network ls
NETWORK ID NAME DRIVER SCOPE
cab8b04240be bridge bridge local
289c7a4e3a88 docker_gwbridge bridge local
7912cd38ffbd host host local
z8hpu4pg07m7 ingress overlay swarm
5668efe47596 none null local这时候我们只需要开启一个容器,强制指定网络为test-net,docker就会自动同步对应网络了
$ docker run -dit --name alpine2 --network test-net alpine
fb635f5ece59563e7b8b99556f816d24e6949a5f6a5b1fbd92ca244db17a4342这个时候再来查看,worker 节点中就有了刚刚创建的网络了。
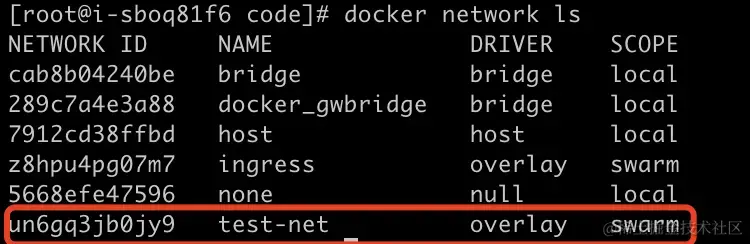
image.png
2. 运行容器搭建
进入manager节点,先创建一个 workspace 文件夹,内部的文件列表如下:
├── workspace/
├── code/
├── docker-compose.yml
├── Dockerfile1. 训练框架准备
我用的是 hiyouga/LLaMA-Factory: Easy-to-use LLM fine-tuning framework 这个大模型训练微调框架,它支持目前市面上主流的大模型(llama2、chatglm2、baichuan2、qwen等),以及多种训练模式(sft、pt、ppo、dpo等),使用起来挺方便的,作者更新和回复也挺勤。
# 进入工作目录
$ cd workspace
# 克隆项目到code文件夹
$ git clone https://github.com/hiyouga/LLaMA-Factory code
# 进入特定commit
$ git checkout 2caf91f824320b226daa4666eda2da7cb853db9c我这边测试成功的环境:
- 显卡驱动版本是
CUDA Version: 11.8 - torch版本
2.0.1 - 训练框架的commit是
2caf91f824320b226daa4666eda2da7cb853db9c
requirements.txt 主要安装包版本如下:
torch==2.0.1
transformers==4.33.1
datasets==2.14.6
accelerate==0.24.1
peft==0.6.0
trl==0.7.2
gradio==3.38.0
scipy==1.11.3
sentencepiece==0.1.99
protobuf==4.25.0
tiktoken==0.5.1
jieba==0.42.1
rouge-chinese==1.0.3
nltk==3.8.1
uvicorn==0.24.0
pydantic==1.10.11
fastapi==0.95.1
sse-starlette==1.6.5
matplotlib==3.8.12. 启动容器
我用的基础镜像是nvidia/cuda:11.7.1-devel-ubuntu22.04,需要安装一下python3.10,Dockerfile文件如下:
FROM nvidia/cuda:11.7.1-devel-ubuntu22.04
# 更新系统包
RUN apt-get update && apt-get install -y git build-essential zlib1g-dev libncurses5-dev libgdbm-dev libnss3-dev libssl-dev libsqlite3-dev libreadline-dev libffi-dev liblzma-dev libbz2-dev curl wget net-tools iputils-ping pdsh
# 安装Python
WORKDIR /home/user
RUN wget https://www.python.org/ftp/python/3.10.6/Python-3.10.6.tgz && \
tar -zvxf Python-3.10.6.tgz && cd Python-3.10.6 && \
./configure --enable-optimizations && make -j 4 && make install这里我们分别到 manager , worker 节点使用 docker-compose up -d 命令启动容器,相应的配置文件如下:
version: "3"
services:
llm:
build:
context: .
dockerfile: Dockerfile
container_name: llm
tty: true
restart: always
ulimits:
memlock: -1
stack: 67108864
shm_size: 40G
deploy:
resources:
reservations:
devices:
- capabilities: [gpu]
volumes:
- ./code:/home/user/code:cached
networks:
- test-net
networks:
test-net:
external: true3. 验证网络
启动之后,可以使用docker inspect llm 命令查看对应容器的网络结构
manager 节点网络ip如下:
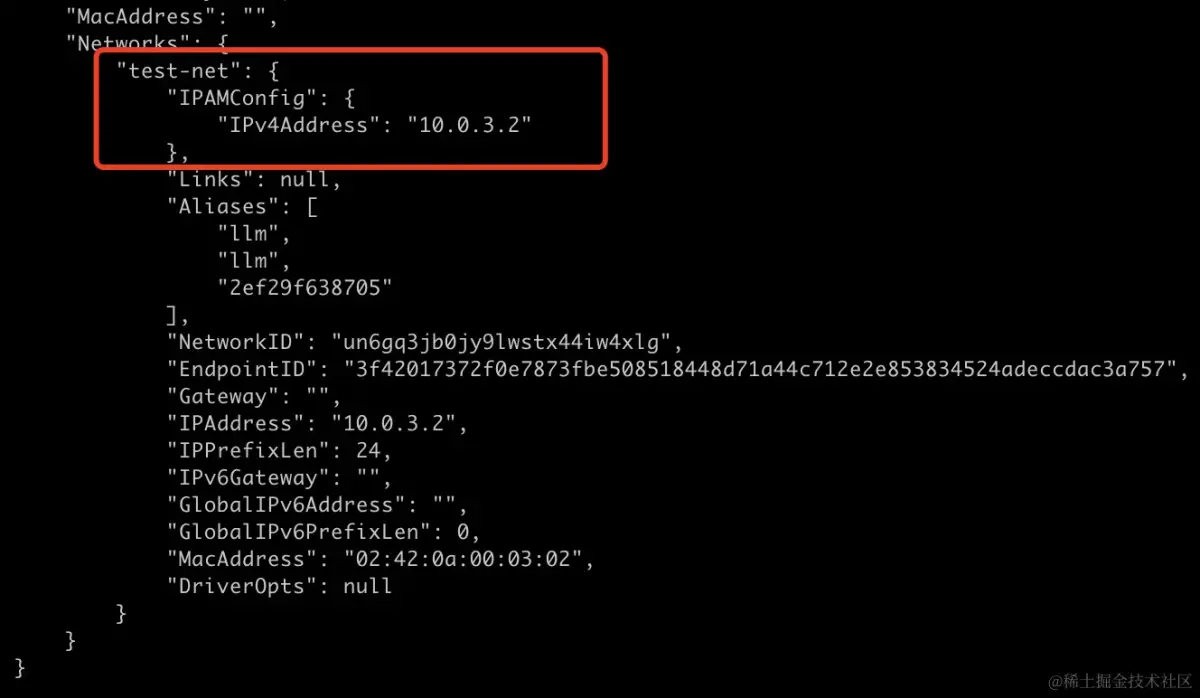
\`manager\` 节点网络ip
worker 节点网络ip如下:
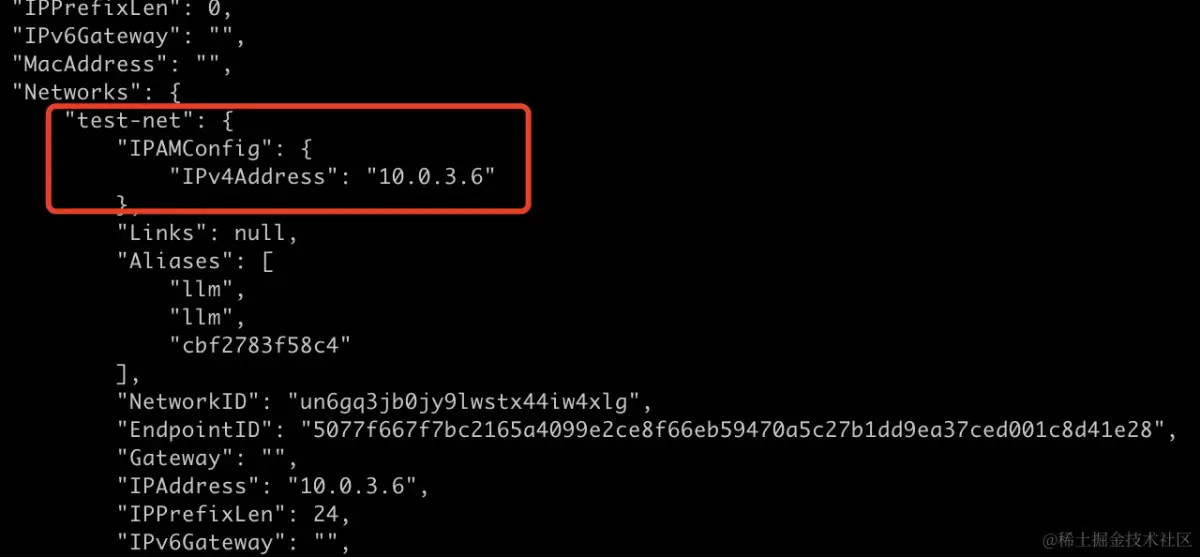
\`worker\` 节点网络ip
然后去 manager 节点执行 docker exec -it llm bash 命令进入容器, ping 一下 worker 节点
root@2ef29f638705:/home/user/code# ping 10.0.3.6
PING 10.0.3.6 (10.0.3.6) 56(84) bytes of data.
64 bytes from 10.0.3.6: icmp_seq=1 ttl=64 time=0.414 ms
64 bytes from 10.0.3.6: icmp_seq=2 ttl=64 time=0.311 ms同样的操作去 worker 节点也ping一下
root@cbf2783f58c4:/home/user/code# ping 10.0.3.2
PING 10.0.3.2 (10.0.3.2) 56(84) bytes of data.
64 bytes from 10.0.3.2: icmp_seq=1 ttl=64 time=0.527 ms
64 bytes from 10.0.3.2: icmp_seq=2 ttl=64 time=0.485 ms
64 bytes from 10.0.3.2: icmp_seq=3 ttl=64 time=0.506 ms到此,两台服务器间的容器网络就通了。
3. 开启容器间免密访问
1. 安装openssh-server服务
首先分别去manager,worker节点的容器中安装openssh-server服务并启动
# 安装ssh服务
apt-get install openssh-server -y
# 启动ssh服务
/etc/init.d/ssh start2. 配置免密登录
注意:以下操作都是在manager,worker节点容器内部
分别去manager,worker节点的容器中执行 ssh-keygen -t rsa 命令,一直回车即可
root@2ef29f638705:/home/user/code# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:tUB6SjLnvqM7p2l+bmHUZGNqUyyOPmXGyiMp3tC9xNA root@2ef29f638705
The key's randomart image is:
+---[RSA 2048]----+
| .. |
| .oB |
| +++Oo.. |
| ..E@o.o . |
| .++Bo.S . |
|..o.*=o |
|..o..+o. |
| . .oo=. |
| o*Xo. |
+----[SHA256]-----+然后
- 将
manager节点中的~/.ssh/id_rsa.pub的内容复制写入到manager节点和worker节点中的~/.ssh/authorized_keys文件中。 - 将
worker节点中的~/.ssh/id_rsa.pub的内容复制写入到manager节点和worker节点中的~/.ssh/authorized_keys文件中。
接着分别去manager,worker节点的/etc/hosts文件中增加映射
10.0.3.2 manager
10.0.3.6 worker最后测试服务器容器之间是否可以免密登录
root@2ef29f638705:/home/user/code# ssh root@worker
Welcome to Ubuntu 22.04.3 LTS (GNU/Linux 3.10.0-1160.102.1.el7.x86_64 x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
This system has been minimized by removing packages and content that are
not required on a system that users do not log into.
To restore this content, you can run the 'unminimize' command.
Last login: Tue Nov 21 12:01:18 2023 from 10.0.3.24. 配置NCCL网络
NCCL相关配置需要修改一下,要不然训练的时候会卡住。先要看容器使用的是哪个网卡,就是看节点的ip对应的网卡。
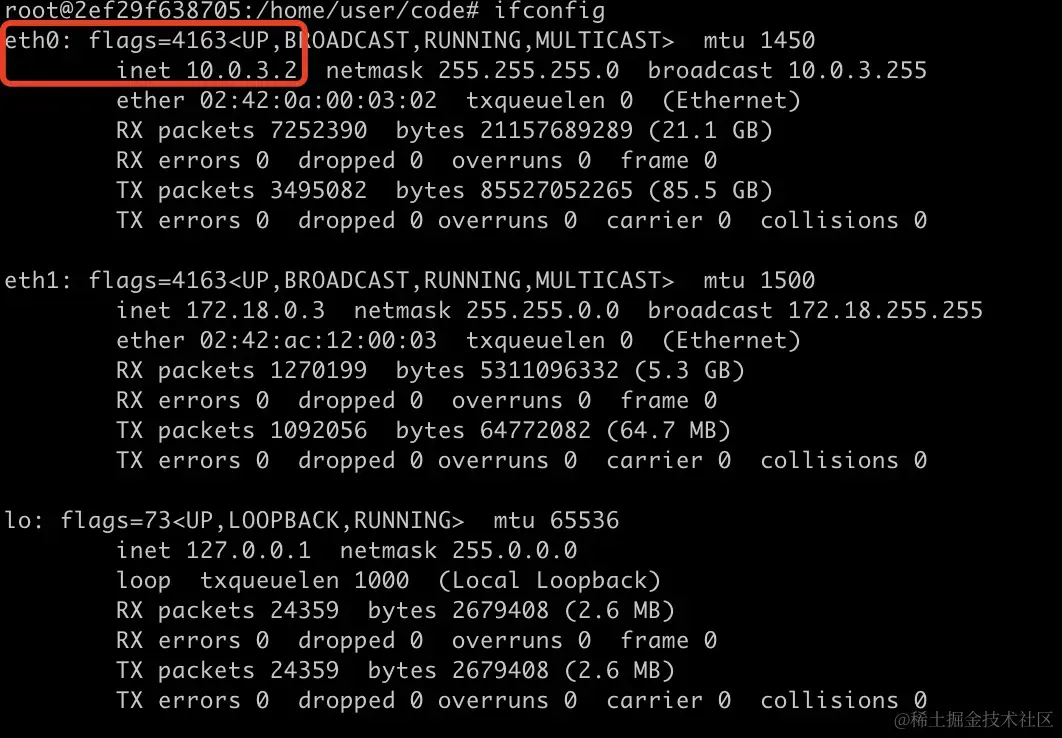
image.png
可以看到manager节点用的是eth0网卡
我一般是直接将这个环境变量写入到 /etc/profile 中
...
#需要注意NCCL的配置,这里需要根据机器的情况指定NCCL的通讯网卡
export NCCL_SOCKET_IFNAME=eth0然后不要忘了 source /etc/profile 让其生效,worker节点要执行同样的操作。
5. 分布式训练
1. 模型准备
先去下载chatglm2-6b模型,然后放到容器的 /home/user/code
2. 安装依赖
root@2ef29f638705:~# cd /home/user/code/
root@2ef29f638705:/home/user/code# pip3 install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple3. 准备配置文件
/home/user/code/目录下新建 hostfile 文件,写入:
manager slots=1
worker slots=1/home/user/code/目录下新建 ds_config.json 文件,写入:
{
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"zero_allow_untested_optimizer": true,
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"initial_scale_power": 16,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"zero_optimization": {
"stage": 2,
"allgather_partitions": true,
"allgather_bucket_size": 5e8,
"reduce_scatter": true,
"reduce_bucket_size": 5e8,
"overlap_comm": false,
"contiguous_gradients": true
}
}manager和worker节点需要执行同样的操作,保证训练代码和训练运行的环境一致
4. 执行训练命令
进入manager节点的 /home/user/code/ 文件夹,执行
deepspeed --hostfile hostfile src/train_bash.py \
--deepspeed ds_config.json \
--stage sft \
--model_name_or_path /home/user/code/chatglm2-6b \
--do_train \
--dataset alpaca_gpt4_zh \
--template chatglm2 \
--finetuning_type lora \
--lora_target query_key_value \
--output_dir chatglm2_sft \
--overwrite_cache \
--overwrite_output_dir \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 10000 \
--learning_rate 5e-5 \
--num_train_epochs 0.25 \
--plot_loss \
--fp16可以看到,训练已经跑起来了,并且输出了两台机器的日志
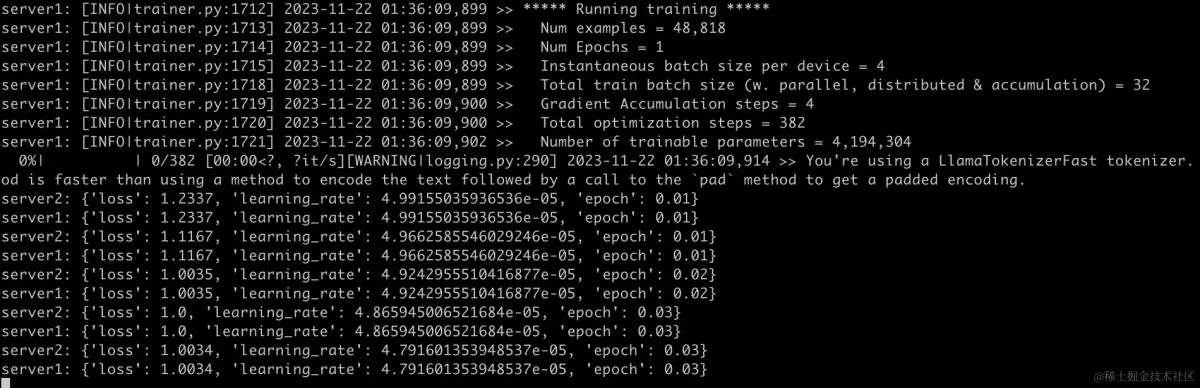
多机多卡训练
分别去两台服务器中执行 nvidia-smi,可以看到显卡均有被使用,至此,分布式训练完毕。
6. 常见报错
1. pdsh 问题
raise RuntimeError(f"launcher '{args.launcher}' not installed.")
这个错误一般是 pdsh 没安装,容器里面执行 apt-get install pdsh 命令安装即可
2. NCCL 问题
Proxy Call to rank 0 failed (Connect)
这个是NCCL问题,按照上面的教程,配置一下环境变量就行
参考链接:
- [[Question] How to launch jobs with Docker env using multiple nodes in DeepSpeed? · Issue #2920 · microsoft/DeepSpeed (github.com)](https://links.jianshu.com/go?to=https%3A%2F%2Fgithub.com%2Fmicrosoft%2FDeepSpeed%2Fissues%2F2920)
- Networking with overlay networks | Docker Docs
- DeepSpeed在docker容器内实现多机多卡\_deepspeed 多机多卡训练-CSDN博客
版权申明
作者:雨田君的记事本
转自:https://www.jianshu.com/p/2792ebf9af71
