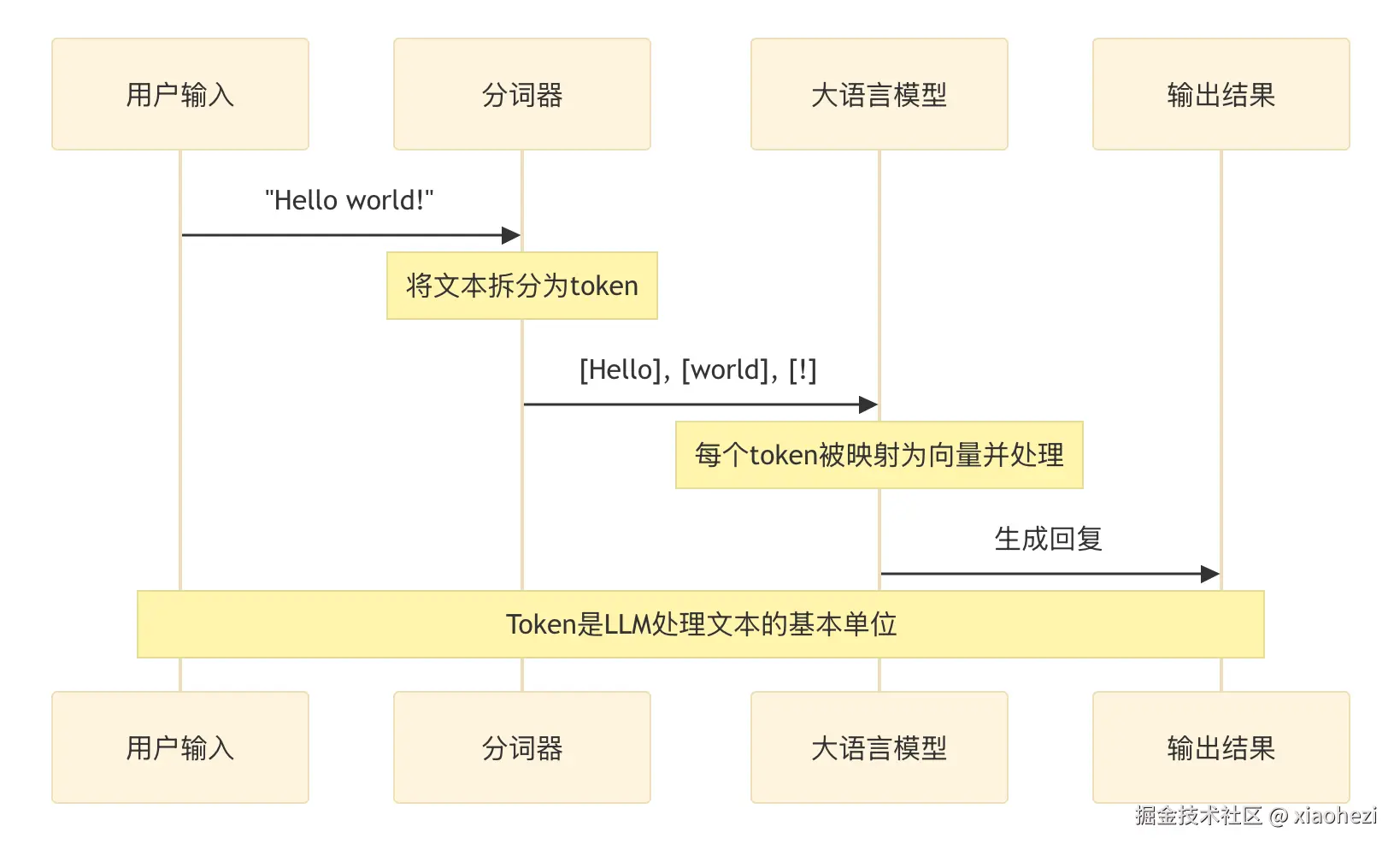
大模型核心概念科普:Token、上下文长度、最大输出,一次讲透 Post Views: 1,674 Token 是什么 token 是大模型(LLM)用来表示自然语言文本的基本单位,可以直观的理解为 “字” 或 “词”。 通常 1 个中文词语、1 个英文单词、1 个数字或 1 个符号计为 1 个 token 一般情况下模型中 token 和字数的换算比例大致如下: 1 个英文字符 ≈ 0.3 个 token。 1 个中文字符 ≈ 0.6 个 token。 所以 AIGC admin 2025-03-20 1541 热度 0评论
vllm serve的参数大全及其解释 Post Views: 1,354 以下是 vllm serve 的常见参数说明以及它们的作用: 1. 基本参数 model_tag 说明:用于指定要加载的模型,可以是 Hugging Face 模型仓库中的模型名称,也可以是本地路径。 示例: vllm serve \"gpt-neo-2.7B\" --config CONFIG 说明:允许从 YAML 配置文件加载参数。适合复杂配置。 示例: vl 大模型 admin 2025-03-03 1399 热度 0评论