基于大模型的文档知识库实现流程
- 大模型
- 2024-06-03
- 2128热度
- 0评论
1. 前言
大模型技术的横空出世给行业及技术应用带来了全新的变革。今天要讲的场景是“知识库”、“企业搜索”相关场景。在大模型出现以前,我们针对这样的业务往往采用传统的搜索引擎如ES来解决,或者更高级一些,引入NLP和KG技术,可以做出较智能的搜索、问答,如采用知识图谱技术的KBQA。
随着大模型技术的不断迭代,如今我们有了全新的方式去探索建设一个行业垂类或者企业内部知识库。而根据笔者观察,这也是大模型技术落地最常见的一个方向。
网上层出不穷的分析文章多如牛毛,但往往还是从算法、代码层面入手,这里我们尝试以更浅显直接的语言对这一应用场景进行阐述、归纳,本文会涉及少量代码讲解,更容易帮助读者理解。
看完本篇文章你会对如何应用大模型实现个人/企业知识库的核心流程有基本认知。
2. 实现流程简析
2.1 核心功能
首先提出一个最基础的“文档知识库项目”的核心功能,包括以下内容:
-
- 文档上传,生成后台知识库
-
- 检索,返回知识内容
- 其实还会涉及如对话、历史记录等相关功能,但并非核心,暂且不表。
2.2 技术选型
后端:Python
开发框架:Langchain
大模型在线服务:智谱ChatGLM
向量数据库:Chroma
2.3 技术流程
核心技术流程如下
-
- 构建知识库: 首先将用户上传的一批文档(如PDF、TXT等),默认按照段落分割成N个Chunks(块)
-
- 知识库向量化:又称为Embedding,将所有Chunks处理为向量数据,以便计算机理解,这些数据会存入专用的向量数据库
-
- 检索向量化:将用户的Query也转化为向量,然后在向量知识库中去匹配出向量计算最相似的top K个段落
-
- 提交LLM生成回答:将用户query、匹配出的文本打包交给大模型,由大模型理解、归纳形成总结后的完整答案,即检索结果
这也是现在大家都在讲的RAG(检索增强生成/Retrieval-augmented Generation),相当于给大模型外挂了知识库。
下面将依次对以上流程进行详细说明
3. 详细过程说明
3.1 前置内容
在step by step的过本篇技术流程前,还有些前置内容需要了解,我们要介绍Langchain、大模型接入的基础概念。
3.1.1 什么是LangChain
先明确一点,Langchain是一个大语言模型开发框架,是用于大模型相关业务的一个开发套件。LangChain 本身不提供LLM,本质上就是对各种大模型提供的 API 的套壳,是为了方便我们使用这些 API,搭建起来的一些框架、模块和接口。 LangChain 将 LLM 模型(对话模型、embedding模型等)、向量数据库、交互层 Prompt、外部知识、外部代理工具整合到一起,进而可以自由构建 LLM 应用。
LangChain 主要由以下 6 个核心模块组成:
模型输入/输出(Model I/O):与语言模型交互的接口
数据连接(Data connection):与特定应用程序的数据进行交互的接口
链(Chains):将组件组合实现端到端应用
记忆(Memory):用于链的多次运行之间持久化应用程序状态
代理(Agents):扩展模型的推理能力,用于复杂的应用的调用序列
回调(Callbacks):扩展模型的推理能力,用于复杂的应用的调用序列
看到这里你或许不会太明白,没关系,后续我们将给出零星的代码,让你真正理解LangChain是怎么用起来的。
3.1.2 大模型服务接入
目前的大模型接入有两种方式,一种是本地模型私有化部署应用,一种是接厂商的API,这两种没有本质的区别,为了更方便跑起来,本文所介绍的是接入厂商API的方式,不用考虑本地GPU算力要求。
以下给出调用ChatGLM在线服务的示例
3.2 构建知识库
首先一步是收集用户的知识文档原文件,如操作手册、Wiki、文献等等,读者可自行类比。这里我们先介绍Langchain对文件的引入功能
以上是简单的Python代码,我们可以可到通过引入了langchain的document\_loaders的module,就实现了对用户的“SQL基础教程.pdf”文件的入库。同理,通过工程化可以实现文件批量导入。
其次,是对文件进行分割。同样使用LangChain来实现,可按照字符数量长度等一系列参数进行分割,这里咱们只需要要了解是根据规则把文档进行分割即可,不用吃透具体怎么切分的。
分割完后的效果如下所示:
3.3 知识库向量化
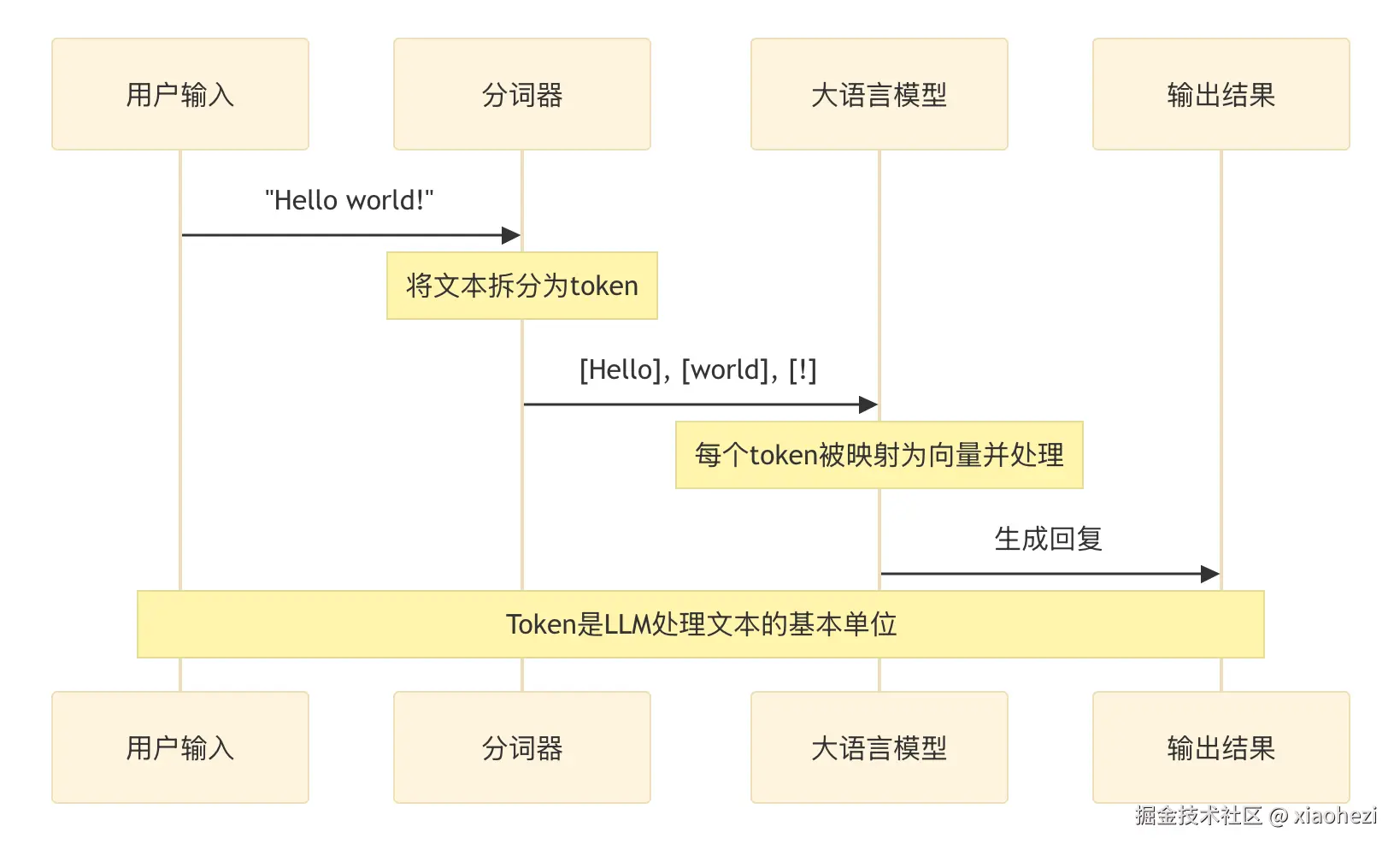
取得分割后的文档,我们需要将其向量化,也就是NLP领域常见的Embedding。所谓Embedding,不求甚解理解就是将文字转换成向量形式,这样机器处理的其实是矩阵运算而不是一个个文字。对文档进行Embedding通常有2种手段。
- • 采用大模型在线接口:如OpenAI或者ChatGLM的接口
- • 本地部署Embedding模型:如M3E、Moka等
方便起见,我们直接使用ChatGLM的接口服务,还是采用LangChain对接:
Embedding以后,我们的文档究竟变成什么样了呢,就上述几个词给出示例:
“旅游”向量化以后会转换成一个1024维的向量,具体多少维和你使用的大模型本身有关。
之后,在把每个文档向量化以后,我们将采用数据库将这些结果存起来。这里我们使用一款名为Chroma的轻量级向量数据库,LangChain也集成了这个数据库方便使用。
如上所示,经过zhipu的embedding接口处理过的数据存在了本地的chroma目录中
3.4 检索向量化
前面我们用大量的篇幅讲了文档向量化,其实主要的目的是将文字转换成机器能处理的矩阵形式来进行后续计算。 首先先看以下的科普内容。每个词语都会有一个向量来表示,我们就可以利用向量计算对文本进行处理。最常见的的做法,计算两个文本的余弦相似度,来判断文本之间的的相似度,如:
越接近于 1 越相似,越接近 0 越不相似。 可以看到,算法判断火箭和航天意义相近,而旅游和火箭、航天意义一般,符合实际。 所以我们检索的流程,是将用户的Query也处理成一个向量,再去匹配向量知识库中已有的Chunks,然后召回最相似匹配的几个结果,比如TOP 3,TOP 5。
以下我们以“什么是数据库”为query给出执行过程,选择输出TOP 3的内容。
打印检索到的内容
这样,我们就找到了这本书中和“什么是数据库”最相似的3个段落内容。
3.5 提交LLM生成回答
在上一步,我们得到3个段落后,会连同Query“什么是数据库”一起提交给LLM,让大模型帮我们总结归纳,生成最终的答案。如下所示。
首先我们通过LangChain构建一个Prompt,以及一个检索链,本文对Prompt不过多展开。
如下,用户检索“什么是数据库”,经过一系列检索链路,可以得到以下回答。
这样,我们就实现了从文档的入库 => 向量化检索 => 大模型回答的整个流程。
4. 以百度文心APP示例分析
最后,我们使用一个典型的文档知识库应用来分析,以加深整个技术实现的认识。 从上到下,依次是Prompt设计、知识库上传、模型与参数配置选项,基本都能对应到上文LangChain的相关模块功能,大家可以有个感性认识。
参考资料:
动手学大模型应用开发
datawhalechina.github.io/llm-universe/



{kind=link}