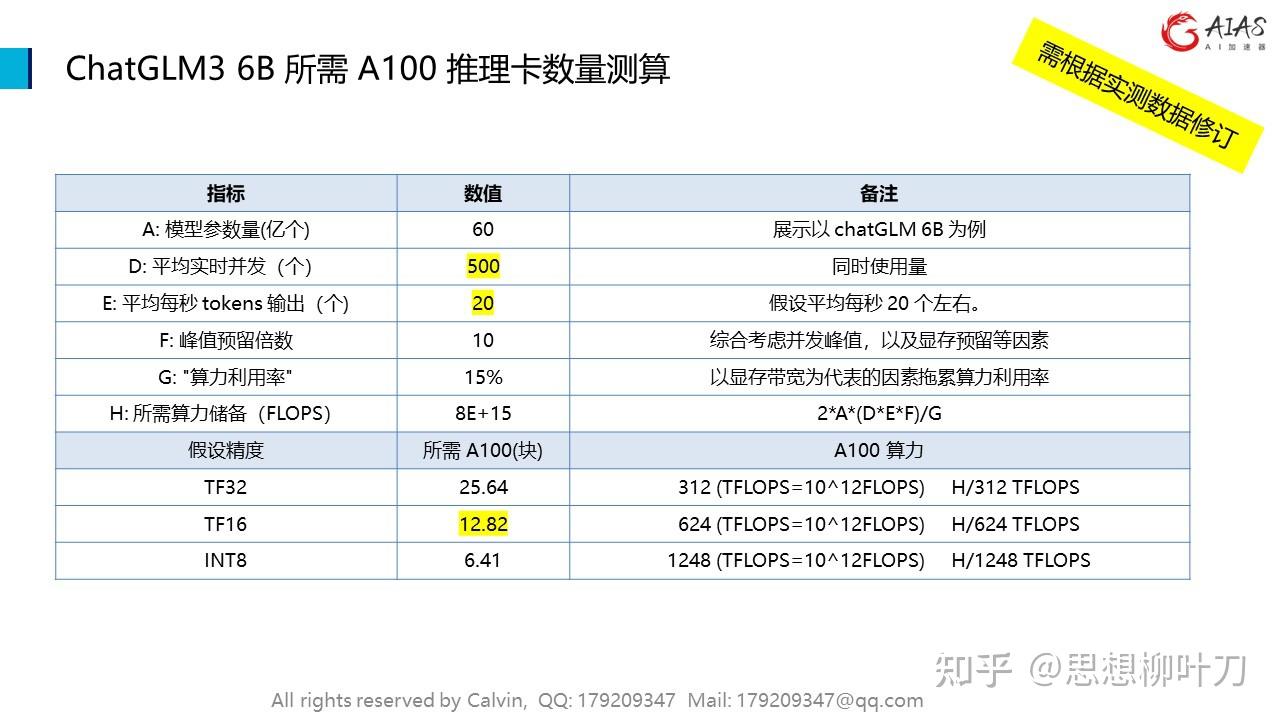
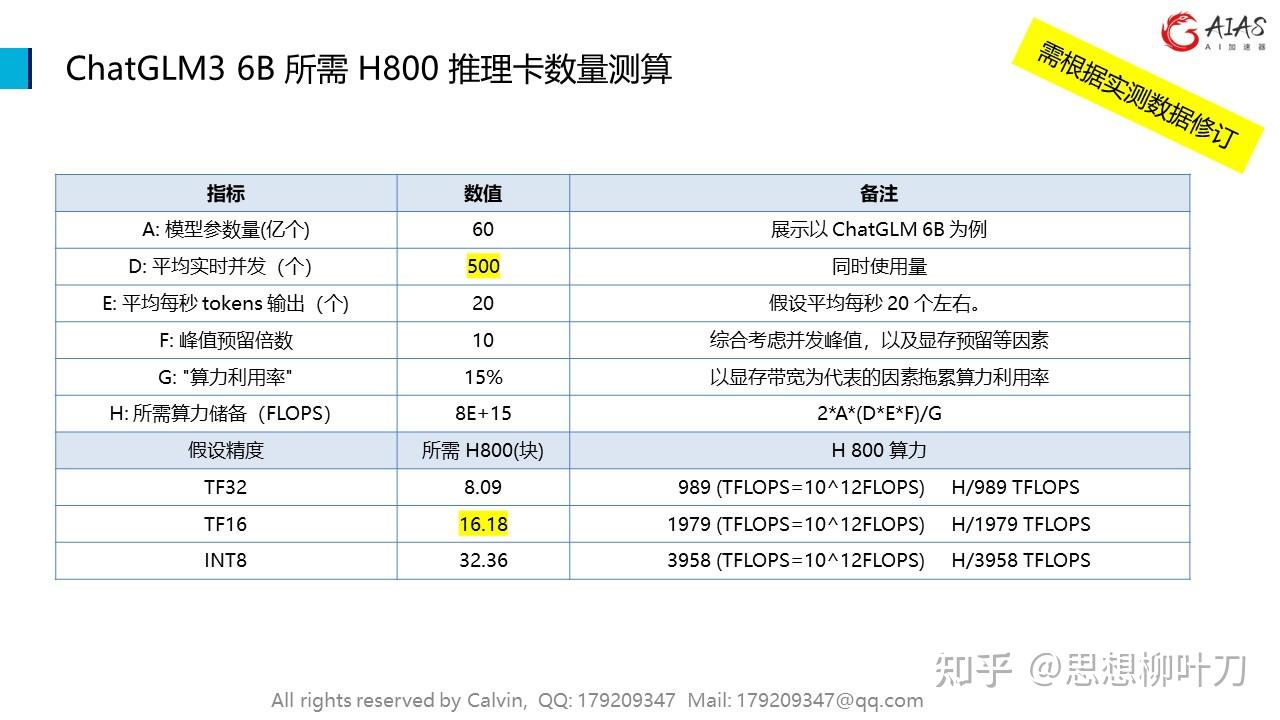
大模型之推理 – 容量估算
- AIGC
- 2025-02-27
- 1167热度
- 0评论
LLM之推理成本高主要原因在于:
•模型自身复杂性:模型参数规模大,对计算和内存的需求增加
•自回归解码:逐token进行,速度太慢
•延迟 (Latency) :主要从用户的视角来看,从提交一个prompt,至返回response的响应时间,衡量指标为生成单个token的速度,如16 ms/token;若batch_size=1,只给一个用户进行服务,Latency最低。
•吞吐量 (Throughput) :主要从系统的角度来看,单位时间内能处理的token数,如16 tokens/s;增加Throughput一般通过增加batch_size,即,将多个用户的请求由串行改为并行

•首次令牌时间 (TTFT):
用户输入查询后开始看到模型输出的速度。较短的响应等待时间对于实时交互至关重要,但对于离线工作负载则不太重要。该指标由处理提示然后生成第一个输出令牌所需的时间驱动。
•每个输出令牌的时间 (TPOT) :
为查询我们系统的每个用户生成输出令牌的时间。该指标与每个用户如何感知模型的“速度”相对应。例如,100 毫秒/token 的 TPOT 意味着每个用户每秒 10 个 token,或每分钟约 450 个单词,这比一般人的阅读速度要快。
•延迟:
模型为用户生成完整响应所需的总时间。总体响应延迟可以使用前两个指标来计算:
延迟 = (TTFT) + (TPOT) *(要生成的令牌数量)。
•吞吐量:
推理服务器每秒可以针对所有用户和请求生成的输出令牌数。

延迟 (Latency):
•关注服务体验,返回结果越快,用户体验越好;
•针对延迟的优化,主要还是底层的OP算子、矩阵优化、并行、更高效的C++推理等。针对延迟的优化可以提升吞吐量,但没有直接增加 batch_size 来的更显著。
吞吐量 (Throughput):
•关注系统成本,系统单位时间处理的量越大,系统利用率越高。
•针对吞吐量优化,主要是KV Cache存取优化,本质是降低显存开销,从而可以增加 batch_size。
权衡 (trade-off):
•高并发时,将用户请求组batch后能提升吞吐量,但一定程度上会损害每个用户的延迟,因为之前只计算一个请求,现在合并计算多个请求,每个用户等待的时间就长了。通常,吞吐量随batch_size增大而增大,延迟也随之提升,当然延迟在可接受范围内就是ok的,因此二者需要trade-off。
•对于一些离线的场景,我们对延迟并不敏感,这时会更多的关注吞吐量,但对于一些实时交互类的应用,我们就需要同时考虑延迟和吞吐量。
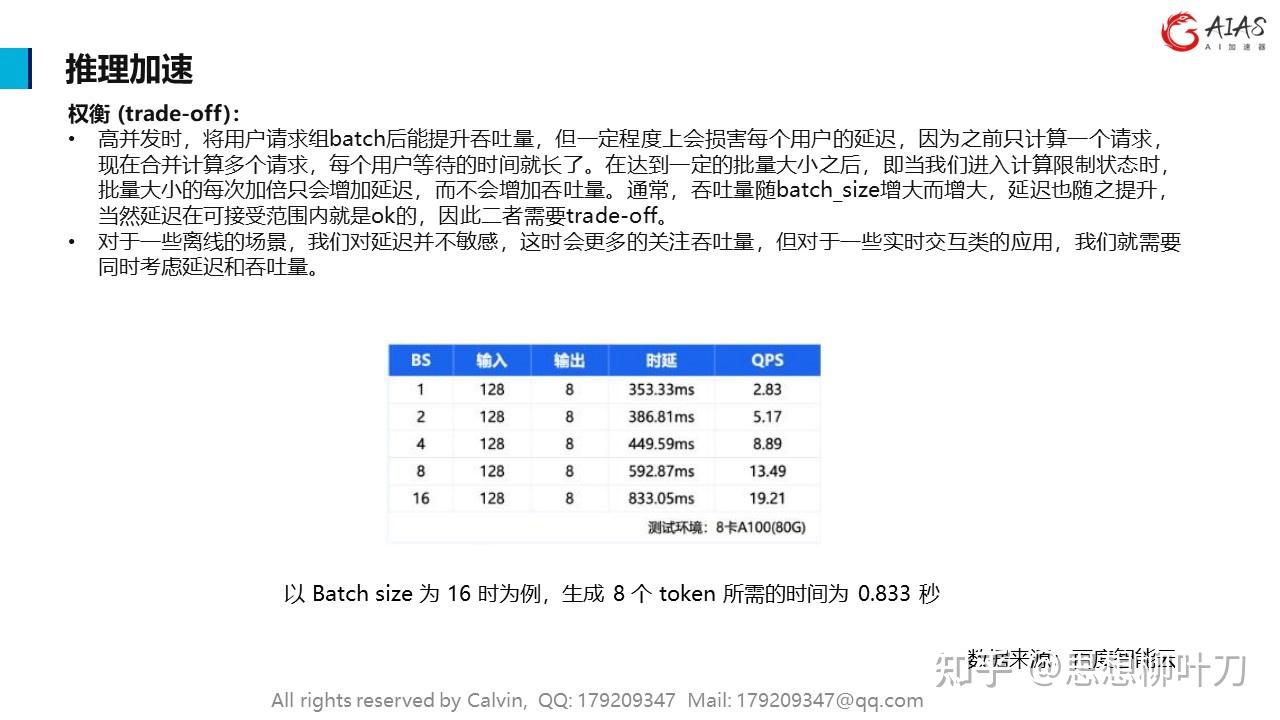
权衡 (trade-off):
•高并发时,将用户请求组batch后能提升吞吐量,但一定程度上会损害每个用户的延迟,因为之前只计算一个请求,现在合并计算多个请求,每个用户等待的时间就长了。在达到一定的批量大小之后,即当我们进入计算限制状态时,批量大小的每次加倍只会增加延迟,而不会增加吞吐量。通常,吞吐量随batch_size增大而增大,延迟也随之提升,当然延迟在可接受范围内就是ok的,因此二者需要trade-off。
•对于一些离线的场景,我们对延迟并不敏感,这时会更多的关注吞吐量,但对于一些实时交互类的应用,我们就需要同时考虑延迟和吞吐量。

该类方法主要通过优化 Transformer 的结构以实现推理性能的提升。
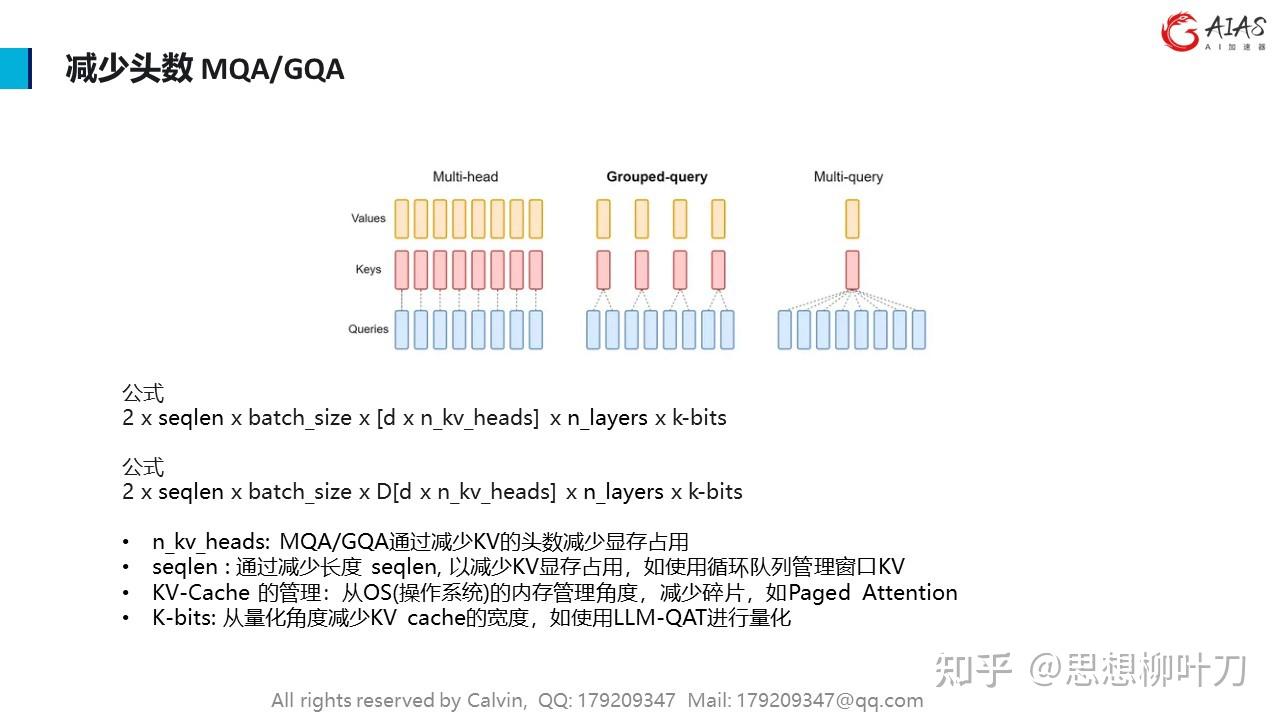
在自回归 decoder 中,所有输入到 LLM 的 token 会产生注意力 key 和 value 的张量,这些张量保存在 GPU 显存中以生成下一个 token。这些缓存 key 和 value 的张量通常被称为 KV cache,其具有以下特点:
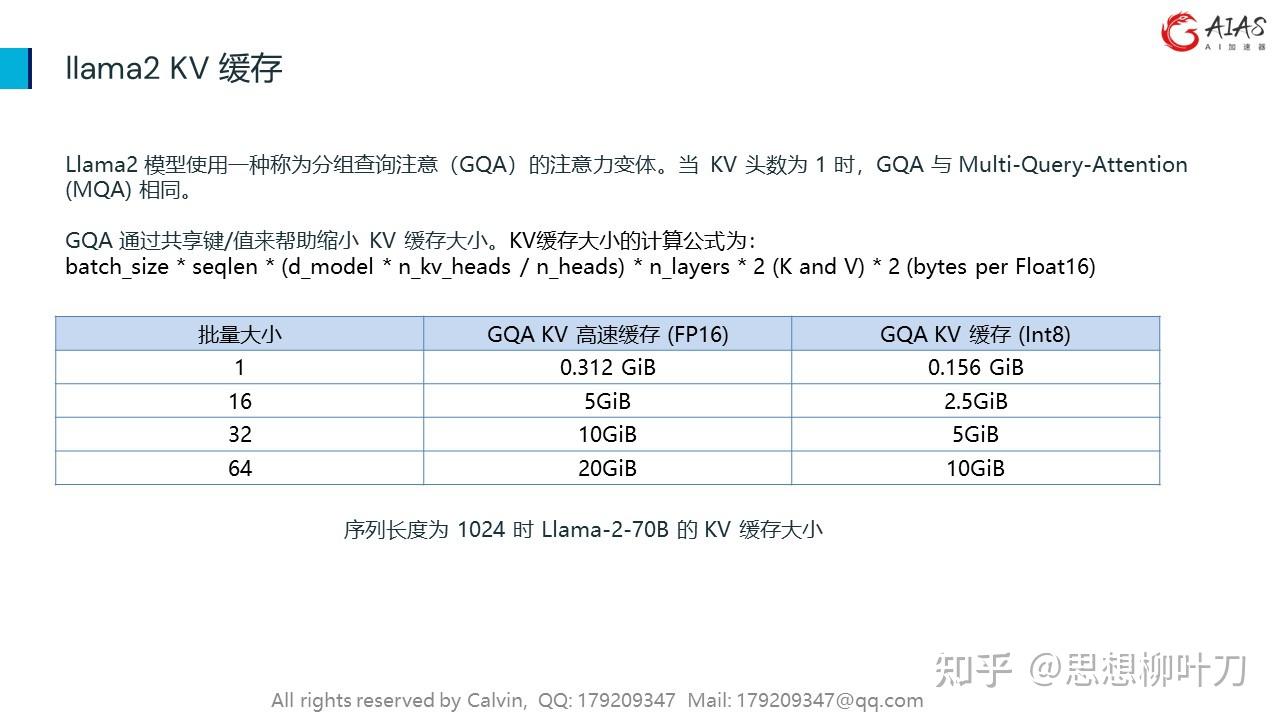
•显存占用大:在 LLaMA-13B 中,缓存单个序列最多需要 1.7GB 显存;
•动态变化:KV 缓存的大小取决于序列长度,这是高度可变和不可预测的。因此,这对有效管理 KV cache 挑战较大。该研究发现,由于碎片化和过度保留,现有系统浪费了 60% - 80% 的显存。
4.1 FlashAttention
•在不访问整个输入的情况下计算 softmax
•不为反向传播存储大的中间 attention 矩阵
4.2 PagedAttention
PagedAttention 允许在非连续的内存空间中存储连续的 key 和 value 。
具体来说,PagedAttention 将每个序列的 KV cache 划分为块,每个块包含固定数量 token 的键和值。在注意力计算期间,PagedAttention 内核可以有效地识别和获取这些块。
4.3 FLAT Attention
FLAT-Attention 与 FlashAttention 采取不同的路线来解决同一问题。 提出的解决方案有所不同,但关键思想是相同的(tiling 和 scheudling)。
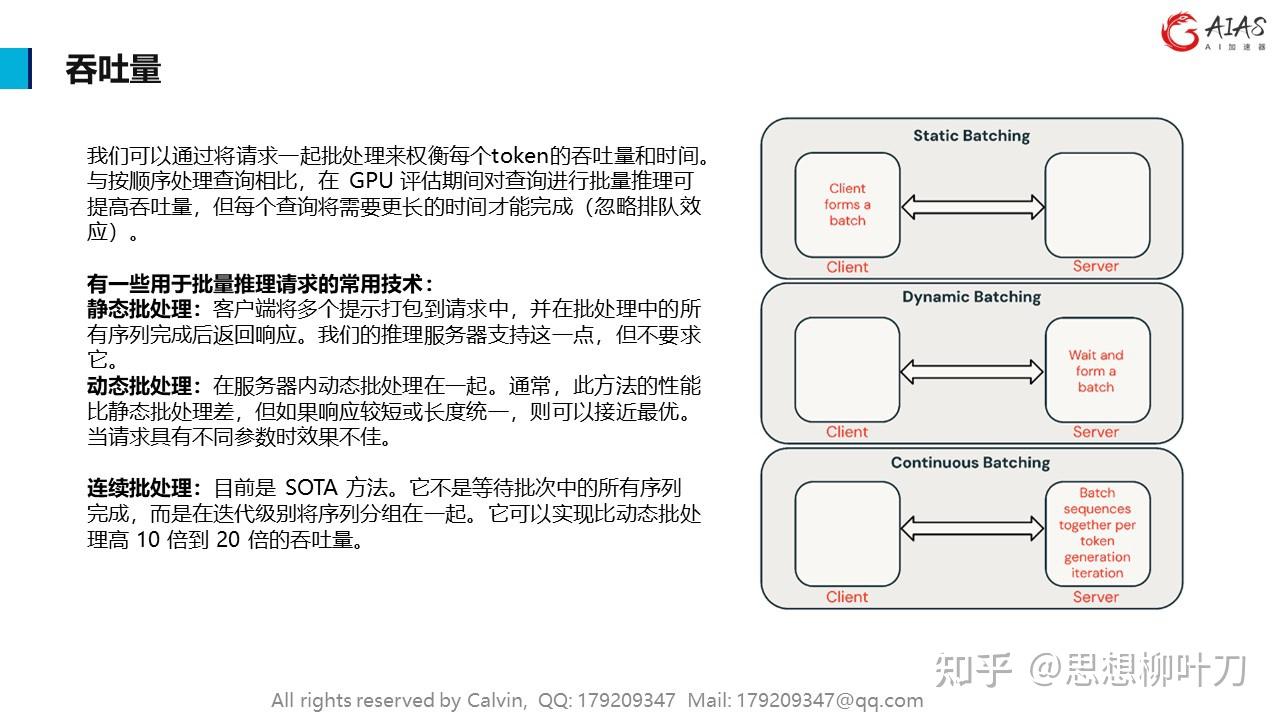
我们可以通过将请求一起批处理来权衡每个token的吞吐量和时间。与按顺序处理查询相比,在 GPU 评估期间对查询进行批量推理可提高吞吐量,但每个查询将需要更长的时间才能完成(忽略排队效应)。
有一些用于批量推理请求的常用技术:
静态批处理:客户端将多个提示打包到请求中,并在批处理中的所有序列完成后返回响应。我们的推理服务器支持这一点,但不要求它。
动态批处理:在服务器内动态批处理在一起。通常,此方法的性能比静态批处理差,但如果响应较短或长度统一,则可以接近最优。当请求具有不同参数时效果不佳。
连续批处理:目前是 SOTA 方法。它不是等待批次中的所有序列完成,而是在迭代级别将序列分组在一起。它可以实现比动态批处理高 10 倍到 20 倍的吞吐量。

连续批处理(Continuous batch)方法主要是针对多 Batch 的场景,通过对 Batch 的时序优化,以达到去除 padding、提高吞吐和设备利用率。传统的 Batch 处理方法是静态的,因为Batch size 的大小在推理完成之前保持不变。
Continuous Batch不是等到 Batch 中的所有序列完成生成,而是实现 iteration 级调度,其中Batch size由每次迭代确定。 结果是,一旦 Batch 中的序列完成生成,就可以在其位置插入新序列,从而比静态 Batch 产生更高的 GPU 利用率。

vLLM 功能:
•支持动态 batch。
•使用 PagedAttention 优化 KV cache 显存管理。
•支持linux。
vLLM 优点:
•最快的推理速度
•最好的服务吞吐性能
•与 HuggingFace 模型无缝集成(目前支持GPT2, GPTNeo, LLaMA, OPT 系列)
•高吞吐量服务与各种 decoder 算法,包括并行采样、beam search 等
•张量并行(TP)以支持分布式推理
•流输出
•兼容 OpenAI 的 API 服务
vLLM 缺点:
•添加自定义模型:虽然可以合并自己的模型,但如果模型没有使用与vLLM中现有模型类似的架构,则过程会变得更加复杂。例如,增加Falcon的支持,这似乎很有挑战性;
•缺乏对适配器(LoRA、QLoRA等)的支持:当针对特定任务进行微调时,开源LLM具有重要价值。然而,在当前的实现中,没有单独使用模型和适配器权重的选项,这限制了有效利用此类模型的灵活性。
•缺少权重量化:这对于减少GPU显存消耗至关重要。



模型推理(inference)是指在已经训练好的模型上对新的数据进行预测或分类。推理阶段通常比训练阶段要求更低的显存,因为不涉及梯度计算和参数更新等大量计算。以下是计算模型推理时所需显存的一些关键因素:
模型结构: 模型的结构包括层数、每层的神经元数量、卷积核大小等。较深的模型通常需要更多的显存,因为每一层都会产生中间计算结果。
输入数据: 推理时所需的显存与输入数据的尺寸有关。更大尺寸的输入数据会占用更多的显存。
批处理大小 BatchSize: 批处理大小是指一次推理中处理的样本数量。较大的批处理大小可能会增加显存使用,因为需要同时存储多个样本的计算结果。
数据类型: 使用的数据类型(如单精度浮点数、半精度浮点数)也会影响显存需求。较低精度的数据类型通常会减少显存需求。
中间计算: 在模型的推理过程中,可能会产生一些中间计算结果,这些中间结果也会占用一定的显存。
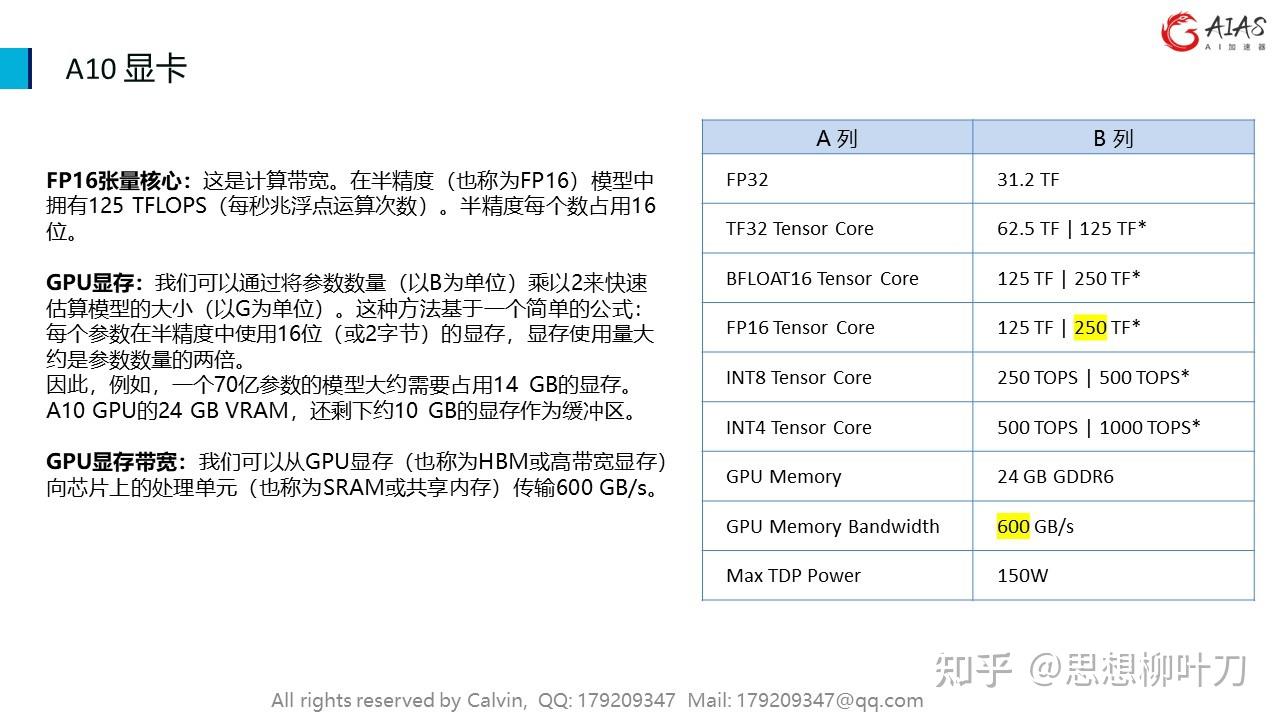
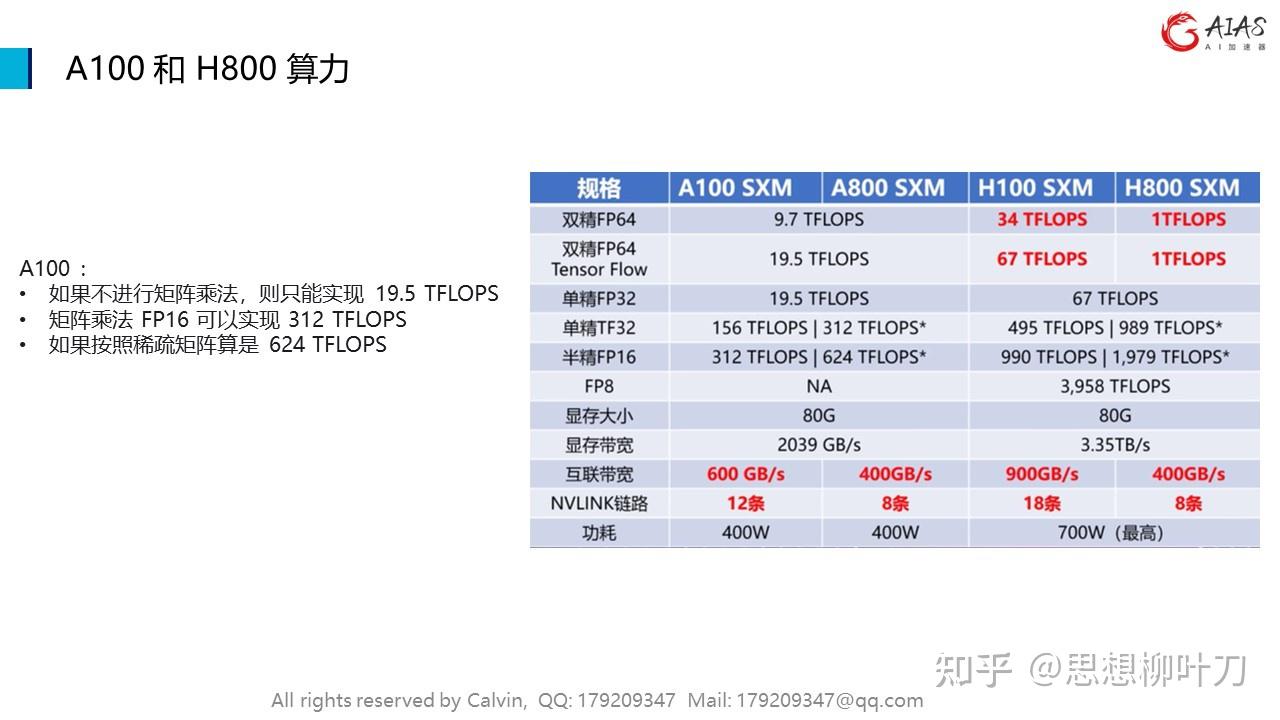
FP16张量核心:这是计算带宽。在半精度(也称为FP16)模型中拥有125 TFLOPS(每秒兆浮点运算次数)。半精度每个数占用16位。
GPU显存:我们可以通过将参数数量(以B为单位)乘以2来快速估算模型的大小(以G为单位)。这种方法基于一个简单的公式:每个参数在半精度中使用16位(或2字节)的显存,显存使用量大约是参数数量的两倍。
因此,例如,一个70亿参数的模型大约需要占用14 GB的显存。A10 GPU的24 GB VRAM,还剩下约10 GB的显存作为缓冲区。
GPU显存带宽:我们可以从GPU显存(也称为HBM或高带宽显存)向芯片上的处理单元(也称为SRAM或共享内存)传输600 GB/s。

访存比:每访问一字节显存,我们可以完成多少浮点运算每秒(FLOPS)。根据规格表中的数字,我们计算A10的访存比。
以非稀疏矩阵计算为例:
上面的数字意味着为了充分利用我们的计算资源,我们需要完成每个显存访问字节的208.3个浮点运算。
•如果我们发现每个字节只能完成少于208.3个运算,那么我们的系统性能受限于显存吞吐。这基本上意味着我们的系统速度和效率受限于数据传输速率或其所能处理的输入输出操作的速度。
•如果我们希望每个字节执行超过208.3个浮点运算,那么我们的系统受限于计算能力。在这种情况下,我们的效率和性能受限于芯片所拥有的计算单元数量,而不是显存。
了解我们是受限于计算能力还是显存是至关重要的,这样我们就知道在哪个方面应该集中优化工作。
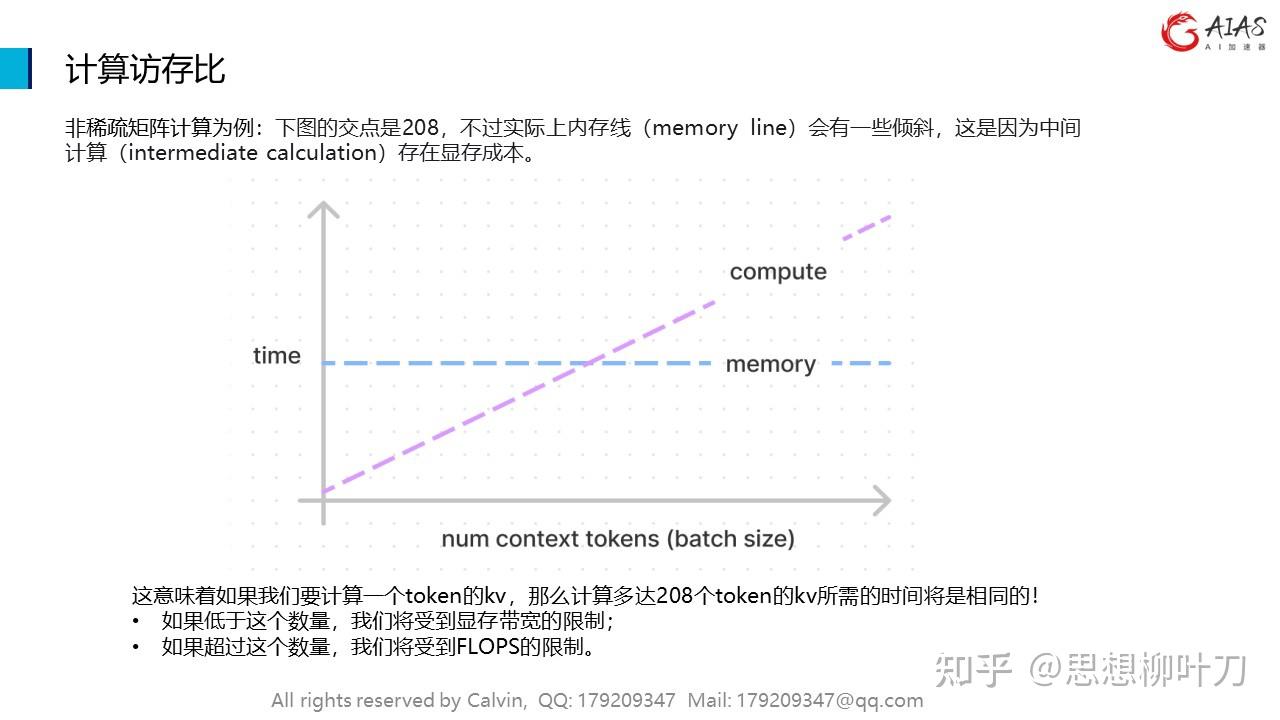
非稀疏矩阵计算为例:下图的交点是208,不过实际上内存线(memory line)会有一些倾斜,这是因为中间计算(intermediate calculation)存在显存成本。
这意味着如果我们要计算一个token的kv,那么计算多达208个token的kv所需的时间将是相同的!
•如果低于这个数量,我们将受到显存带宽的限制;
•如果超过这个数量,我们将受到FLOPS的限制。
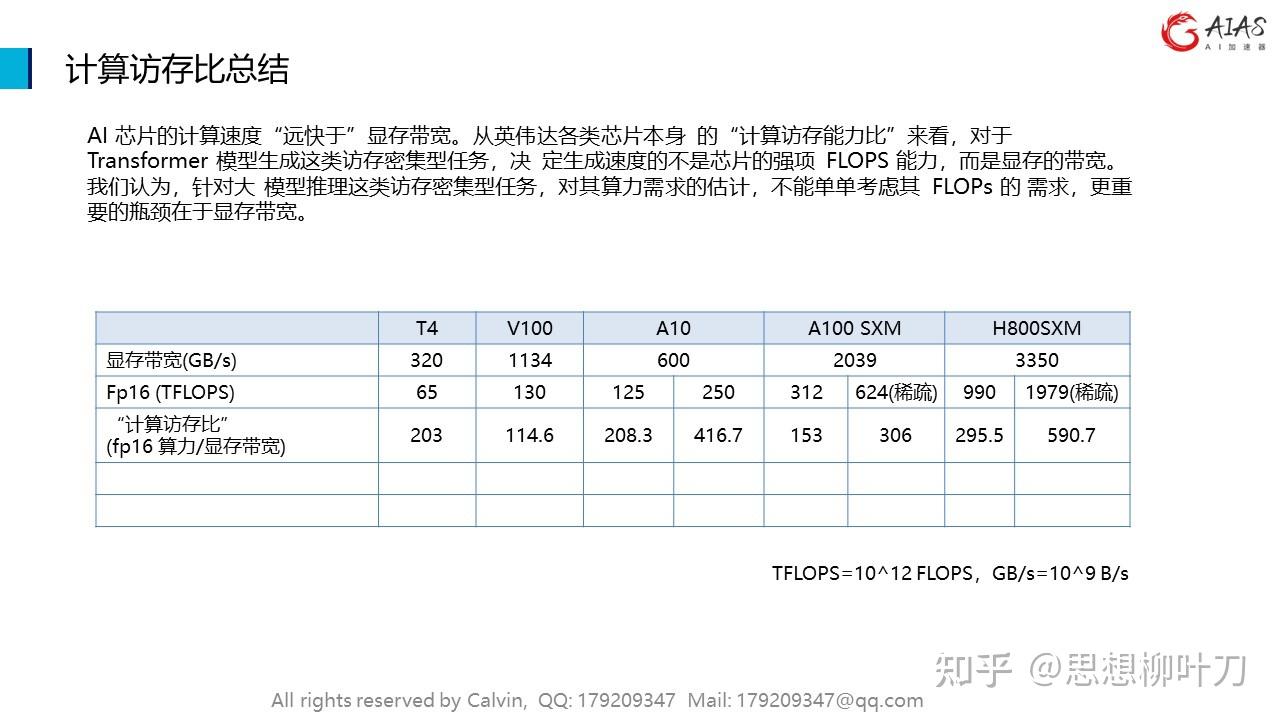
AI 芯片的计算速度“远快于”显存带宽。从英伟达各类芯片本身 的“计算访存能力比”来看,对于 Transformer 模型生成这类访存密集型任务,决 定生成速度的不是芯片的强项 FLOPS 能力,而是显存的带宽。我们认为,针对大 模型推理这类访存密集型任务,对其算力需求的估计,不能单单考虑其 FLOPs 的 需求,更重要的瓶颈在于显存带宽。