实战:vLLM多机多卡部署大模型
- 大模型
- 2025-02-26
- 1232热度
- 0评论
简介
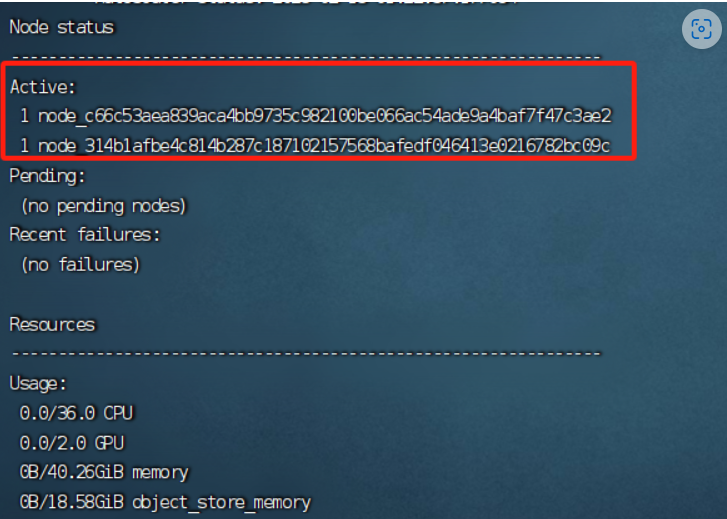
两台GPU服务器,每台GPU服务器8卡GPU,400G IB网络,模型deepseek R1 671B
1. Docker容器中使用GPU
必须确保已安装并配置 NVIDIA Docker。你可以安装 nvidia-docker 来确保 GPU 驱动能够被 Docker 使用
#安装 nvidia-docker:
sudo apt-get install nvidia-docker2
#然后重启 Docker:
sudo systemctl restart docker
2.下载vllm-openai镜像
当前latest版本: v0.7.2
docker pull vllm/vllm-openai:latest
3. 启动vllm-openai容器
会启动一个node容器
![]()
3.1 启动脚本
# master 服务器1执行
sudo bash run_cluster.sh \
vllm/vllm-openai \ # 镜像名称
172.16.3.38 \ # head服务器IP
--head \ # 代表head
/home/llm/ai/model \ # huggingface 模型路径
-v /home/llm/ai/model:/home/llm/ai/model \ # 宿主机本地模型映射到容器内
-e GLOO_SOCKET_IFNAME=enp4s0 \ # 服务器IP对应的网卡名称
-e NCCL_SOCKET_IFNAME=enp4s0 \ # 服务器IP对应的网卡名称
-e VLLM_HOST_IP=172.16.3.38
# worker 服务器2执行
bash run_cluster.sh \
vllm/vllm-openai \
172.16.3.38 \
--worker \ # 代表 从服务器
/home/llm/ai/model \
-v /home/llm/ai/model:/home/llm/ai/model \
-e GLOO_SOCKET_IFNAME=enp5s0 \
-e NCCL_SOCKET_IFNAME=enp5s0 \
-e VLLM_HOST_IP=172.16.3.37
run_cluster.sh
#!/bin/bash
# Check for minimum number of required arguments
if [ $# -lt 4 ]; then
echo "Usage: $0 docker_image head_node_address --head|--worker path_to_hf_home [additional_args...]"
exit 1
fi
# Assign the first three arguments and shift them away
DOCKER_IMAGE="$1"
HEAD_NODE_ADDRESS="$2"
NODE_TYPE="$3" # Should be --head or --worker
PATH_TO_HF_HOME="$4"
shift 4
# Additional arguments are passed directly to the Docker command
ADDITIONAL_ARGS=("$@")
# Validate node type
if [ "${NODE_TYPE}" != "--head" ] && [ "${NODE_TYPE}" != "--worker" ]; then
echo "Error: Node type must be --head or --worker"
exit 1
fi
# Define a function to cleanup on EXIT signal
cleanup() {
docker stop node
docker rm node
}
trap cleanup EXIT
# Command setup for head or worker node
RAY_START_CMD="ray start --block"
if [ "${NODE_TYPE}" == "--head" ]; then
RAY_START_CMD+=" --head --port=6379"
else
RAY_START_CMD+=" --address=${HEAD_NODE_ADDRESS}:6379"
fi
# Run the docker command with the user specified parameters and additional arguments
docker run \
--entrypoint /bin/bash \
--network host \
--name node \
--shm-size 10.24g \
--gpus all \
-v "${PATH_TO_HF_HOME}:/root/.cache/huggingface" \
"${ADDITIONAL_ARGS[@]}" \
"${DOCKER_IMAGE}" -c "${RAY_START_CMD}"
4. 进入到容器内部加载模型
# 进入容器内部
docker exec -it node /bin/bash
# tensor-parallel-size 每台服务器显卡数量
# pipeline-parallel-size 服务器数量
vllm serve /home/llm/ai/model/Qwen/Qwen1___5-1___8B-Chat --port 8080 --tensor-parallel-size 1 --pipeline-parallel-size 2 --dtype float16
5. 查看集群状态