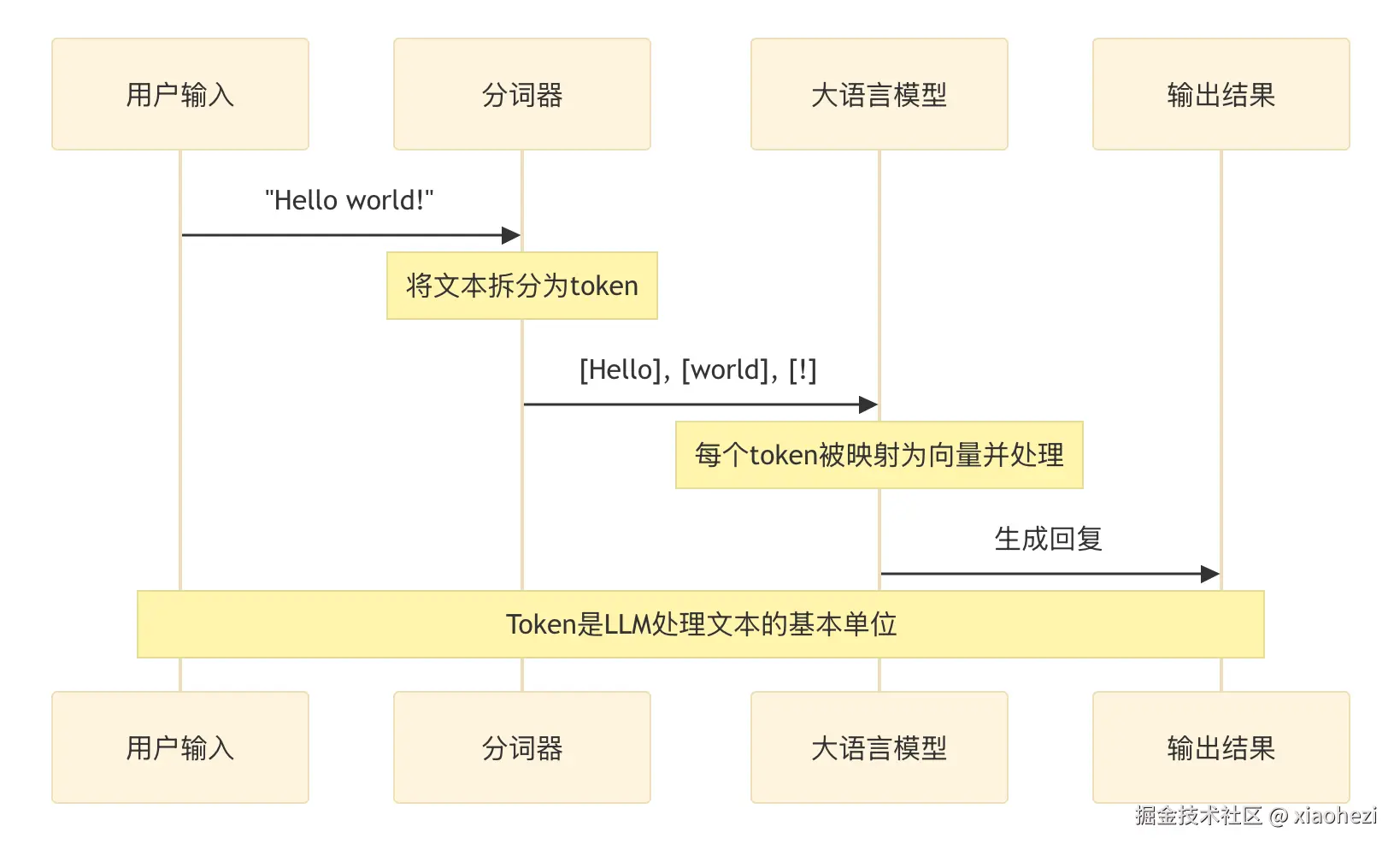
vLLM推理框架本地benchmark测试
- 大模型
- 2025-02-27
- 1245热度
- 0评论
vllm环境搭建:略
本地硬件环境:RTX4090 24G显存 CUDA12.4 多卡
测试命令单卡张量并行:
(vllm_python_source) zxj@zxj:~/zxj/vllm/benchmarks$ python benchmark_throughput.py --backend vllm --input-len 128 --output-len 512 --model ../../models/Llama3-8B-Chinese-Chat-AWQ-4bit/ -q awq --num-prompts 100 --seed 1100 --trust-remote-code --max-model-len 2048 --tensor-parallel-size 1测试结果:
Namespace(backend='vllm', dataset=None, input_len=128, output_len=512, model='../../models/Llama3-8B-Chinese-Chat-AWQ-4bit/', tokenizer='../../models/Llama3-8B-Chinese-Chat-AWQ-4bit/', quantization='awq', tensor_parallel_size=1, n=1, use_beam_search=False, num_prompts=100, seed=1100, hf_max_batch_size=None, trust_remote_code=True, max_model_len=2048, dtype='auto', gpu_memory_utilization=0.9, enforce_eager=False, kv_cache_dtype='auto', quantization_param_path=None, device='cuda', enable_prefix_caching=False, enable_chunked_prefill=False, max_num_batched_tokens=None, download_dir=None)
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
WARNING 05-30 16:10:15 config.py:203] awq quantization is not fully optimized yet. The speed can be slower than non-quantized models.
INFO 05-30 16:10:15 llm_engine.py:100] Initializing an LLM engine (v0.4.2) with config: model='../../models/Llama3-8B-Chinese-Chat-AWQ-4bit/', speculative_config=None, tokenizer='../../models/Llama3-8B-Chinese-Chat-AWQ-4bit/', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=True, dtype=torch.float16, max_seq_len=2048, download_dir=None, load_format=LoadFormat.AUTO, tensor_parallel_size=1, disable_custom_all_reduce=False, quantization=awq, enforce_eager=False, kv_cache_dtype=auto, quantization_param_path=None, device_config=cuda, decoding_config=DecodingConfig(guided_decoding_backend='outlines'), seed=1100, served_model_name=../../models/Llama3-8B-Chinese-Chat-AWQ-4bit/)
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
INFO 05-30 16:10:15 utils.py:638] Found nccl from library /home1/zxj/.config/vllm/nccl/cu12/libnccl.so.2.18.1
INFO 05-30 16:10:16 selector.py:27] Using FlashAttention-2 backend.
INFO 05-30 16:10:18 model_runner.py:174] Loading model weights took 5.3440 GB
INFO 05-30 16:10:19 gpu_executor.py:120] # GPU blocks: 7410, # CPU blocks: 2048
INFO 05-30 16:10:20 model_runner.py:937] Capturing the model for CUDA graphs. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI.
INFO 05-30 16:10:20 model_runner.py:941] CUDA graphs can take additional 1~3 GiB memory per GPU. If you are running out of memory, consider decreasing `gpu_memory_utilization` or enforcing eager mode. You can also reduce the `max_num_seqs` as needed to decrease memory usage.
INFO 05-30 16:10:25 model_runner.py:1017] Graph capturing finished in 6 secs.
Processed prompts: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████| 100/100 [00:19<00:00, 5.20it/s]
Throughput: 5.19 requests/s, 3320.81 tokens/s测试命令2卡张量并行:
(vllm_python_source) zxj@zxj:~/zxj/vllm/benchmarks$ python benchmark_throughput.py --backend vllm --input-len 128 --output-len 512 --model ../../models/Llama3-8B-Chinese-Chat-AWQ-4bit/ -q awq --num-prompts 100 --seed 1100 --trust-remote-code --max-model-len 2048 --tensor-parallel-size 2测试结果:
Namespace(backend='vllm', dataset=None, input_len=128, output_len=512, model='../../models/Llama3-8B-Chinese-Chat-AWQ-4bit/', tokenizer='../../models/Llama3-8B-Chinese-Chat-AWQ-4bit/', quantization='awq', tensor_parallel_size=2, n=1, use_beam_search=False, num_prompts=100, seed=1100, hf_max_batch_size=None, trust_remote_code=True, max_model_len=2048, dtype='auto', gpu_memory_utilization=0.9, enforce_eager=False, kv_cache_dtype='auto', quantization_param_path=None, device='cuda', enable_prefix_caching=False, enable_chunked_prefill=False, max_num_batched_tokens=None, download_dir=None)
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
WARNING 05-30 16:17:02 config.py:203] awq quantization is not fully optimized yet. The speed can be slower than non-quantized models.
2024-05-30 16:17:04,243 INFO worker.py:1749 -- Started a local Ray instance.
INFO 05-30 16:17:05 llm_engine.py:100] Initializing an LLM engine (v0.4.2) with config: model='../../models/Llama3-8B-Chinese-Chat-AWQ-4bit/', speculative_config=None, tokenizer='../../models/Llama3-8B-Chinese-Chat-AWQ-4bit/', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=True, dtype=torch.float16, max_seq_len=2048, download_dir=None, load_format=LoadFormat.AUTO, tensor_parallel_size=2, disable_custom_all_reduce=False, quantization=awq, enforce_eager=False, kv_cache_dtype=auto, quantization_param_path=None, device_config=cuda, decoding_config=DecodingConfig(guided_decoding_backend='outlines'), seed=1100, served_model_name=../../models/Llama3-8B-Chinese-Chat-AWQ-4bit/)
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
INFO 05-30 16:17:09 utils.py:638] Found nccl from library /home1/zxj/.config/vllm/nccl/cu12/libnccl.so.2.18.1
(RayWorkerWrapper pid=93372) INFO 05-30 16:17:09 utils.py:638] Found nccl from library /home1/zxj/.config/vllm/nccl/cu12/libnccl.so.2.18.1
INFO 05-30 16:17:10 selector.py:27] Using FlashAttention-2 backend.
(RayWorkerWrapper pid=93372) INFO 05-30 16:17:10 selector.py:27] Using FlashAttention-2 backend.
INFO 05-30 16:17:11 pynccl_utils.py:43] vLLM is using nccl==2.18.1
(RayWorkerWrapper pid=93372) INFO 05-30 16:17:11 pynccl_utils.py:43] vLLM is using nccl==2.18.1
INFO 05-30 16:17:12 utils.py:132] reading GPU P2P access cache from /home1/zxj/.config/vllm/gpu_p2p_access_cache_for_6,7.json
WARNING 05-30 16:17:12 custom_all_reduce.py:74] Custom allreduce is disabled because your platform lacks GPU P2P capability or P2P test failed. To silence this warning, specify disable_custom_all_reduce=True explicitly.
(RayWorkerWrapper pid=93372) INFO 05-30 16:17:12 utils.py:132] reading GPU P2P access cache from /home1/zxj/.config/vllm/gpu_p2p_access_cache_for_6,7.json
(RayWorkerWrapper pid=93372) WARNING 05-30 16:17:12 custom_all_reduce.py:74] Custom allreduce is disabled because your platform lacks GPU P2P capability or P2P test failed. To silence this warning, specify disable_custom_all_reduce=True explicitly.
INFO 05-30 16:17:13 model_runner.py:174] Loading model weights took 2.6714 GB
(RayWorkerWrapper pid=93372) INFO 05-30 16:17:13 model_runner.py:174] Loading model weights took 2.6714 GB
INFO 05-30 16:17:14 distributed_gpu_executor.py:45] # GPU blocks: 17549, # CPU blocks: 4096
(RayWorkerWrapper pid=93372) INFO 05-30 16:17:15 model_runner.py:937] Capturing the model for CUDA graphs. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI.
(RayWorkerWrapper pid=93372) INFO 05-30 16:17:15 model_runner.py:941] CUDA graphs can take additional 1~3 GiB memory per GPU. If you are running out of memory, consider decreasing `gpu_memory_utilization` or enforcing eager mode. You can also reduce the `max_num_seqs` as needed to decrease memory usage.
INFO 05-30 16:17:16 model_runner.py:937] Capturing the model for CUDA graphs. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI.
INFO 05-30 16:17:16 model_runner.py:941] CUDA graphs can take additional 1~3 GiB memory per GPU. If you are running out of memory, consider decreasing `gpu_memory_utilization` or enforcing eager mode. You can also reduce the `max_num_seqs` as needed to decrease memory usage.
(RayWorkerWrapper pid=93372) INFO 05-30 16:17:22 model_runner.py:1017] Graph capturing finished in 7 secs.
INFO 05-30 16:17:22 model_runner.py:1017] Graph capturing finished in 7 secs.
Processed prompts: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████| 100/100 [00:28<00:00, 3.53it/s]
Throughput: 3.52 requests/s, 2254.46 tokens/s记录~