AsteraLabs:CXL内存扩展在推理场景的应用
- 大模型
- 2025-09-05
- 254热度
- 0评论
关键要点
1. CXL内存优化了AI推理性能和系统性能。
2. AI模型需要大量的内存和网络带宽来存储上下文窗口和键值对缓存。
3. 使用CXL内存可以提高GPU利用率并降低CPU使用率。
4. CXL内存可以帮助缓解内存瓶颈问题。
5. 使用CXL内存可以加速AI推理过程并提高并发实例数。
关于 AsteraLabs [1]
公司专注于为数据密集型系统设计、制造和销售定制化的连接解决方案。Astera Labs的产品组合包括系统感知半导体,旨在提升云和人工智能基础设施的性能。
AsteraLabs:CXL内存扩展在推理场景的应用-Fig-1
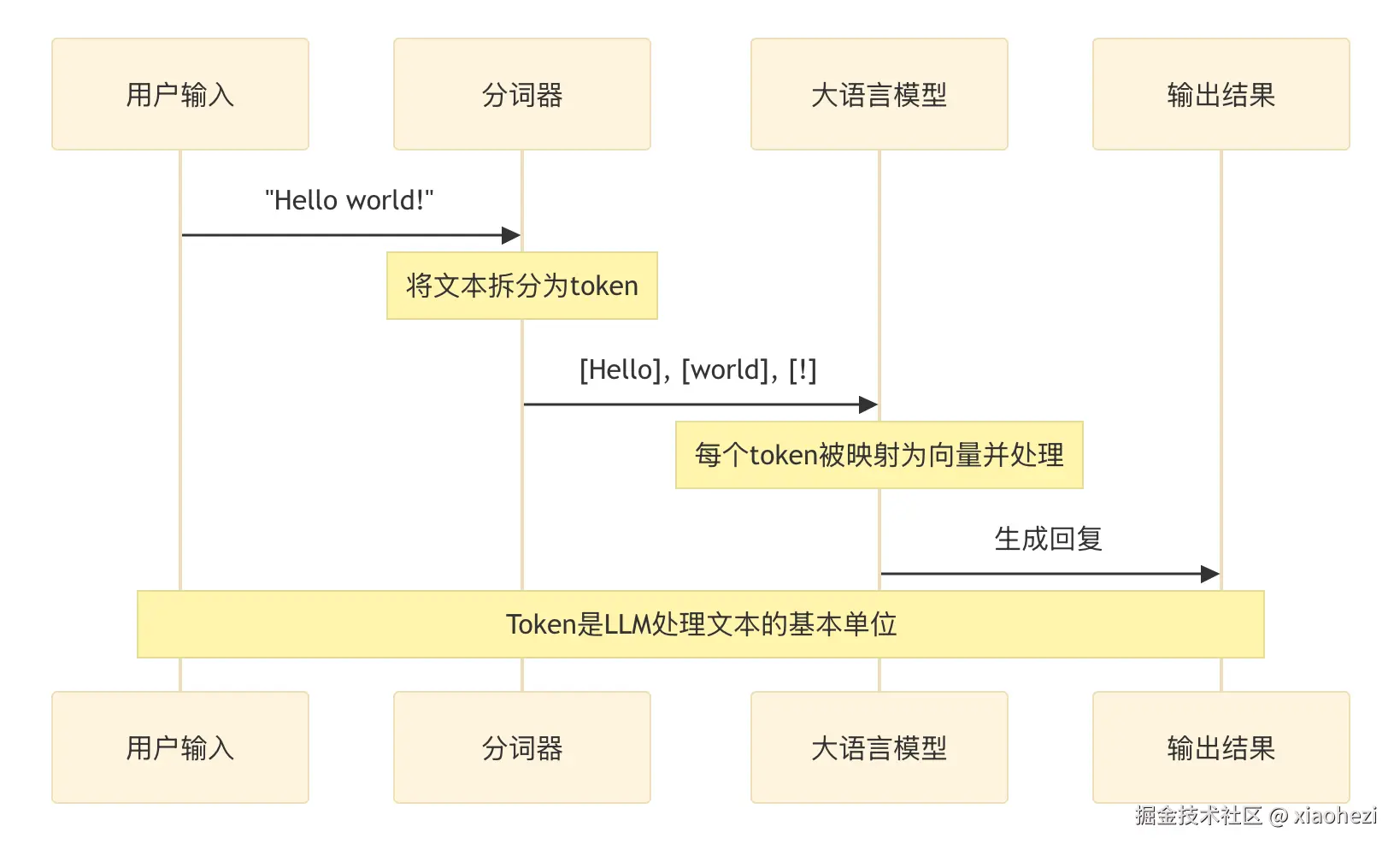
AI 推理的内存需求
LLM推理:
- • 重点是高效解码数据
- • 更加依赖内存且对网络延迟敏感
- • 类GPT应用需要更多RAM来处理更大的上下文窗口
- • 示例:GPT、OPT、LLaMA、Mistral等
关键组成部分:
- • 上下文窗口:定义了KV缓存的边界
- • KV缓存:存储所有先前token的键和值
- • KV缓存消耗大量内存:
- • 注意力模型可能消耗约1MB/token的内存
- • KV缓存的大小取决于数据精度,如:FP32、BF16、FP16、INT8、FP8等
KV缓存存储了所有先前token的键和值
附加说明:
- • 一个大小相当于10本小说的输入,需要大约1000K的上下文窗口,并消耗大约1TB的内存
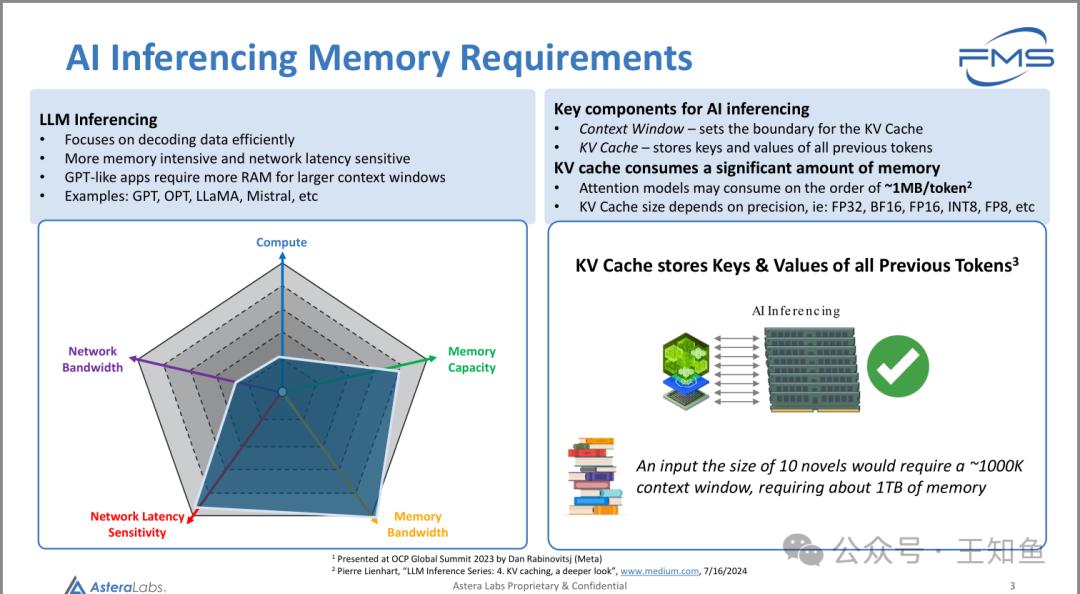
AsteraLabs:CXL内存扩展在推理场景的应用-Fig-2
左图:配置NVMe-SSD的存储架构
右图:使用CXL扩展主存取代SSD
Note:前两天的材料里主要介绍了SSD厂商在推理场景的创新草图,CXL扩展主存来满足推理需求是容易理解的,存在的问题是:CXL协议自身的延迟能否达到适配主存的要求?否则SSD来做推理存储,天然具备成本优势。
参考阅读:

AsteraLabs:CXL内存扩展在推理场景的应用-Fig-3
基于CXL优化的AI推理服务器性能结果
左侧:四块不带CXL的GPU(24个DIMMs)
- • 服务器型号:Supermicro AS-4125GS-TNRT
- • 使用DDR5 4800内存
- • 配置两块NVIDIA L40S每个Socket
右侧:四块带四个Leo CXL控制器的GPU(40个DIMMs)
- • 服务器型号:Supermicro AS-4125GS-TNRT,配备Astera Labs的Leo CXL内存
- • 使用DDR5 5600内存
- • 配置两块NVIDIA L40S和两个Leo CXL内存每个Socket
使用CXL控制器的系统:
- • 数据洞察速度快40%
- • CPU利用率降低40%
- • 每台服务器支持的LLM实例数是原来的两倍
Note:使用CXL内存扩展效率比SSD高,结果并不让人意外,关键还是成本,成本,成本!
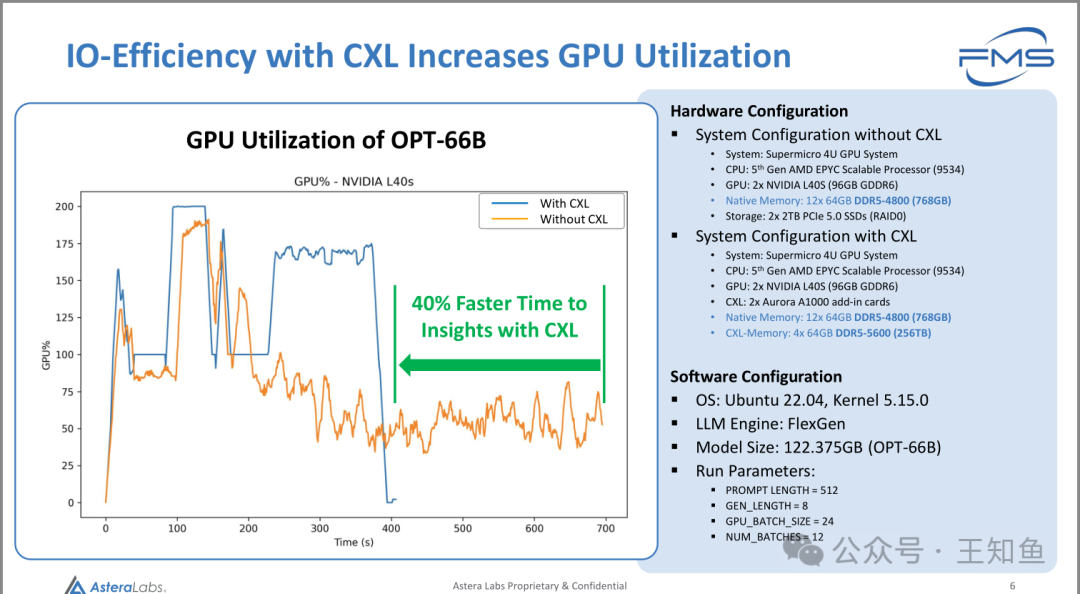
AsteraLabs:CXL内存扩展在推理场景的应用-Fig-4
推理场景实测图-加速推理速度
CXL提高IO效率,从而提升GPU利用率
GPU利用率对比图:显示了OPT-66B模型在NVIDIA L40s GPU上的利用率对比。图表中有两条曲线:
- • 蓝线:使用CXL
- • 橙线:未使用CXL 可以看到,使用CXL时,GPU利用率显著提升,推理速度加快了40%。
硬件配置:
- • 不带CXL的系统配置:
- • 服务器:Supermicro 4U GPU系统
- • CPU:第五代AMD EPYC可扩展处理器(9534)
- • GPU:2块NVIDIA L40S(96GB GDDR6)
- • 原生内存:12块64GB DDR5-4800(768GB)
- • 存储:2块2TB PCIe 5.0 SSD(RAID0)
- • 带CXL的系统配置:
- • 服务器:Supermicro 4U GPU系统
- • CPU:第五代AMD EPYC可扩展处理器(9534)
- • GPU:2块NVIDIA L40S(96GB GDDR6)
- • CXL:2个Aurora A1000扩展卡
- • 原生内存:12块64GB DDR5-4800(768GB)
- • CXL内存:4块64GB DDR5-5600(256GB)
软件配置:
- • 操作系统:Ubuntu 22.04,内核5.15.0
- • 大语言模型引擎:FlexGen
- • 模型大小:122.375GB(OPT-66B)
运行参数:
- • 提示长度(PROMPT LENGTH):512
- • 生成长度(GEN_LENGTH):8
- • GPU批处理大小(GPU_BATCH_SIZE):2
- • 并发批处理(NUM_BATCHES):12
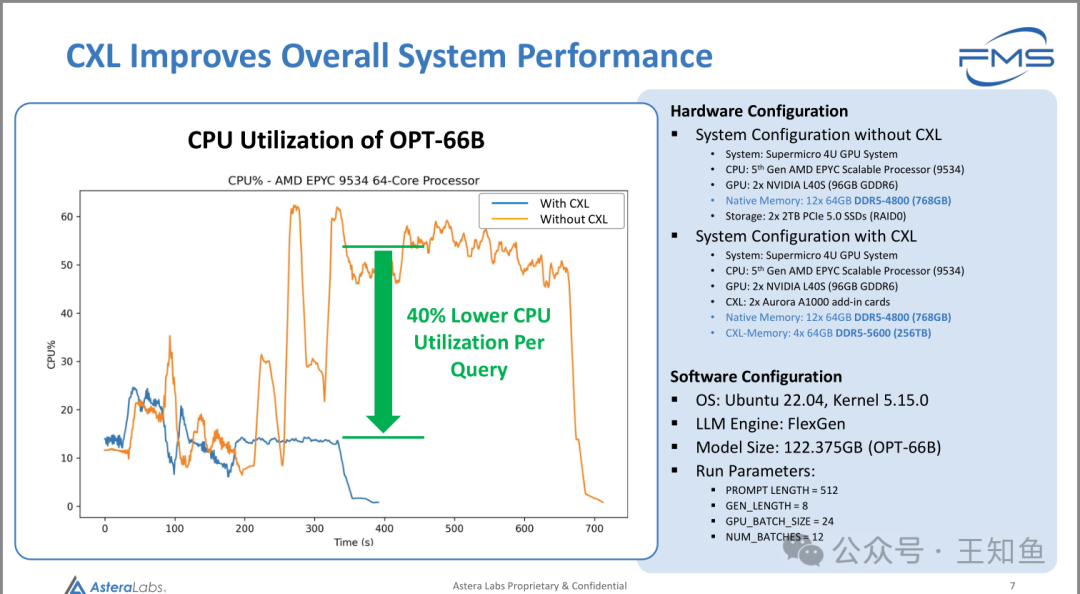
AsteraLabs:CXL内存扩展在推理场景的应用-Fig-5
减少CPU负载
CPU利用率对比图(左):展示了OPT-66B模型在AMD EPYC 9534 64核处理器上的CPU利用率对比。图表显示了使用CXL(蓝线)与未使用CXL(橙线)之间的区别。使用CXL后,每个查询的CPU利用率降低了40%。
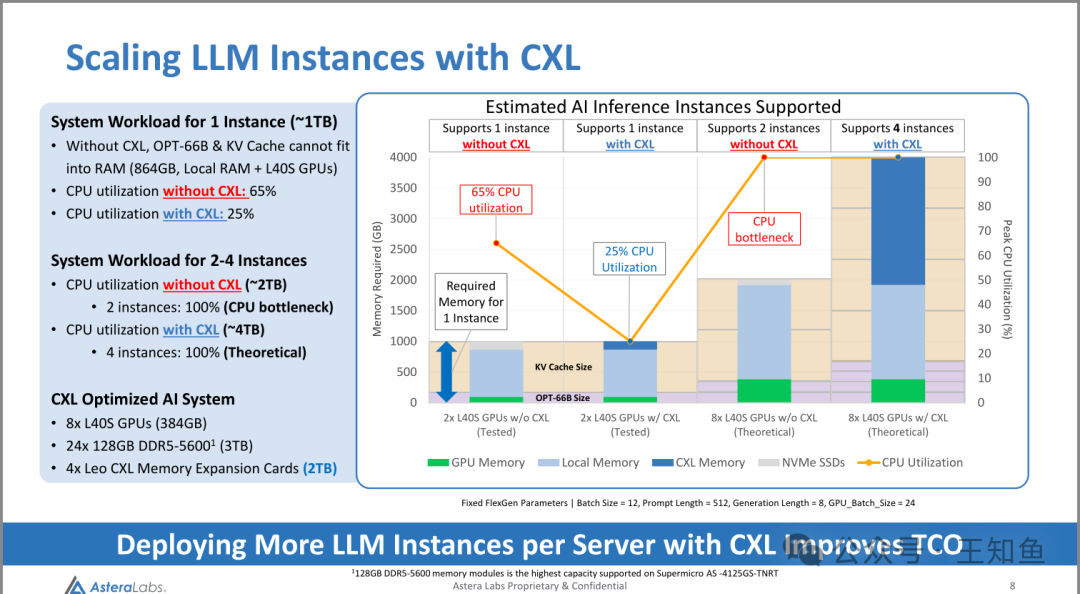
AsteraLabs:CXL内存扩展在推理场景的应用-Fig-6
主要看右侧的图即可,
比较了使用CXL与否的两个测试组,CPU使用率和可支持示例数差异,结论:
单个实例的系统工作负载(约1TB):
- • 在没有CXL的情况下,OPT-66B和KV缓存无法完全放入RAM(864GB,本地RAM + L40S GPUs)。
- • CPU利用率:
- • 没有CXL:65%
- • 使用CXL:25%
2到4个实例的系统工作负载(约2TB-4TB):
- • CPU利用率:
- • 没有CXL(约2TB):2个实例,100%(CPU瓶颈)
- • 使用CXL(约4TB):4个实例,100%(理论值)
如何理解图中实例的含义,与并发用户数是什么关系?
"LLM实例"指的是大语言模型在推理时的独立运行实例。每个实例独立占用系统资源(如GPU、内存),用于处理推理任务。实例的数量决定了服务器可以同时支持多少推理任务。
与并发用户数的关系在于,一个实例可以通过批处理技术同时处理多个用户的请求,因此实例数并不直接等于并发用户数。例如,批处理技术可以将多个用户请求打包,通过一个实例处理,提升并发能力。
总结
- 1. 推理IO行为与数据检索相似,对系统内存带宽、容量及网络实验比较敏感;训练场景对算力和网络带宽敏感,两个场景有显著差异(Fig-1)。
- 2. 基于CXL扩展内存,能有效提高推理效率(QPS ↑40%),降低CPU利用率(↓ 40%),从而能在单位硬件系统中提供更密集的推理服务。(Fig4-6)。
- 3. CXL扩展内存的方案,是将推理参数、过程数据保留在DRAM的方案,可以和SSD方案对比分析,不同厂商自家核心技术存在差异,故方案上有所取舍,落地应用得具体推动力和成本。
引用链接
[1] 关于 AsteraLabs : https://metaso.cn/s/FjoyBV4