CXL内存池与NVIDIA H100 GPU显存协同工作
- AIGC
- 2025-09-05
- 453热度
- 0评论
引言与研究背景
AI大模型训练与推理的"内存墙"挑战
近年来,以GPT系列、LLaMA等为代表的大型语言模型在自然语言处理领域取得了突破性进展。然而,模型的性能提升往往伴随着参数量的爆炸式增长,从数十亿到数万亿。这给计算基础设施带来了前所未有的压力,其中最突出的是内存容量限制。
以当前最先进的NVIDIA H100 GPU为例,其搭载了高达80GB的HBM3高带宽内存,内存带宽接近3.35TB/s为AI计算提供了强大的动力。即便如此,对于动辄数百GB甚至TB级别的模型来说,单块H100的显存仍是杯水车薪。
CXL技术:下一代内存扩展与池化方案
Compute Express Link (CXL)是一种构建在PCIe物理层之上的开放性互连协议,旨在为CPU、GPU、FPGA等加速器和内存设备之间提供高带宽、低延迟的一致性连接。
CXL标准定义的三种协议:
- CXL.io: 功能等同于PCIe,用于设备发现、配置和I/O
- CXL.cache: 允许加速器与CPU高速缓存进行一致性交互
- CXL.mem: 允许CPU将CXL设备上的内存视作自己的主存进行字节级访问
研究目标与报告结构
本报告的研究目标是"CXL内存池与GPU显存的协同工作主要通过分层内存架构和硬件级缓存一致性协议实现",并以NVIDIA H100为例,深入探究具体的实现方案。
核心技术组件分析
NVIDIA H100 GPU架构与内存体系
NVIDIA H100 Tensor Core GPU是为加速大规模AI和HPC工作负载而设计的旗舰产品。其内存体系的关键特征包括:
- 高带宽内存(HBM3):提供高达80GB的容量和超过3TB/s的带宽,是模型计算核心数据(如激活值、近期使用的权重)的理想存储位置
- NVLink与NVSwitch:第四代NVLink技术提供GPU之间高达900 GB/s的双向带宽,通过NVSwitch可连接多达256个GPU,形成一个具有统一内存地址空间的强大计算集群
- PCIe Gen5接口:H100通过PCIe 5.0与CPU主机连接,提供128GB/s的双向带宽。这是GPU与CPU主存以及未来与CXL设备通信的主要物理通道
CXL内存池的工作原理
一个典型的CXL内存池化系统工作流程如下:
- 硬件连接:CXL内存扩展设备(如一块包含大量DDR5内存的PCIe卡)通过PCIe/CXL物理插槽连接到服务器主板
- 主机发现:支持CXL的主机CPU(如Intel Sapphire Rapids, AMD Genoa等)通过CXL.io协议发现该设备
- 内存映射:主机操作系统(如较新版本的Linux内核)的CXL驱动程序识别出这是一个Type-3内存设备。操作系统随后可以将这部分CXL内存映射到系统的物理地址空间
- 呈现为NUMA节点:通常,为了便于管理和优化,操作系统会将CXL内存作为一个独立的NUMA(Non-Uniform Memory Access)节点呈现给上层应用
CXL内存池的核心优势:
容量扩展
可轻松将系统内存扩展至TB级别,远超单个服务器主板的DIMM插槽限制
资源共享与弹性
内存资源可以按需动态地分配给不同的计算节点,提高利用率和灵活性
分层内存
构建了介于GPU HBM和NVMe SSD之间的新内存层级,其延迟和带宽优于SSD
CUDA内存管理模型
CUDA提供了丰富的API来管理内存,这为我们构想与CXL的协同工作提供了基础:
设备内存 (Device Memory)
通过cudaMalloc()分配,位于GPU的HBM上,访问速度最快
统一内存 (Unified Memory)
通过cudaMallocManaged()分配,创建了一个在CPU和GPU之间共享的地址空间。CUDA驱动程序会根据数据访问模式,在物理上自动迁移页面
内存池 (Memory Pools)
CUDA 11.2引入了Stream-ordered内存分配器和内存池API,如cuMemPoolCreate, cuMemAllocFromPoolAsync等。允许开发者创建和管理自定义的内存池,以优化内存分配和释放的性能
CXL内存池与GPU显存协同工作的理论框架
分层内存架构 (Tiered Memory Architecture)
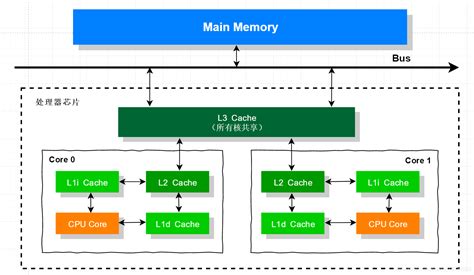
一个集成了CXL内存的AI训练系统内存层级如下:
GPU高速内存
即H100上的80GB HBM3。拥有最高的带宽和最低的延迟。用于存放最核心、最频繁访问的数据,如模型的前向/后向计算所需的激活值、当前层的权重等
CXL扩展内存
通过CXL连接的TB级内存池。其带宽低于HBM但远高于SSD,延迟介于CPU DRAM和SSD之间。用于存放"温数据",如完整的模型权重、优化器状态、部分不常用的激活值、数据集的预取批次等
主机DRAM与NVMe存储
CPU直连的DRAM和高速NVMe SSD。用于存放"冷数据",如整个训练数据集、检查点(Checkpoints)等
数据通路与访问机制
GPU访问T1层的CXL内存,理论上存在两种数据通路:
路径一:通过CPU间接访问(当前可行)
- GPU需要CXL内存中的数据
- CUDA驱动将请求发给CPU
- CPU通过其内存控制器访问CXL内存
- 数据通过PCIe总线从CPU主存(或直接从CXL设备,取决于系统架构)拷贝到GPU的HBM中
- GPU进行计算
这种方式利用了现有的OS和驱动框架,但CPU成为了中间人和瓶颈,PCIe传输也带来了额外开销
路径二:GPU直接访问(GPUDirect for CXL - 假设性)
这是理想的未来方案。类似于GPUDirect RDMA(允许GPU直接访问网络接口卡),"GPUDirect for CXL"将允许H100 GPU绕过CPU,直接在CXL总线上发起对CXL内存的读写请求。这将极大降低访问延迟和CPU负载。
实现这一路径需要:
- GPU硬件支持作为CXL主机或对等设备(Peer-to-Peer)
- 服务器主板的PCIe/CXL Root Complex支持GPU与CXL设备间的直接路由
- NVIDIA驱动和CUDA运行时的深度集成,能够识别和管理CXL内存地址空间
代码级实现方案探讨与概念验证
环境配置与硬件拓扑(假设)
硬件要求
- 服务器:支持CXL 1.1/2.0的CPU(如Intel Sapphire Rapids / Emerald Rapids, AMD Genoa / Turin)
- GPU:NVIDIA H100 80GB PCIe版本
- CXL内存设备:一块符合CXL 2.0规范的Type-3内存扩展卡(例如,1TB DDR5内存)
软件要求
- 操作系统:Linux Kernel 6.2+(对CXL支持较为完善)
- 驱动/软件:NVIDIA Driver 535+,CUDA Toolkit 12.0+
方案一:基于操作系统与统一内存的透明分层方案
此方案利用现有成熟技术,实现简单,对应用代码侵入性小。
核心思想
将CXL内存配置为系统的NUMA节点,然后使用cudaMallocManaged分配内存。让CUDA的统一内存系统和操作系统内核协同,根据页面访问的冷热自动在HBM(T0)和CXL内存(T1)之间迁移数据。
实现步骤与代码示例
#include <cuda_runtime.h>
#include <iostream>
// 假设CXL内存被识别为NUMA Node 1
#define CXL_NUMA_NODE 1
void check_cuda_error(cudaError_t err) {
if (err != cudaSuccess) {
std::cerr << "CUDA Error: " << cudaGetErrorString(err) << std::endl;
exit(EXIT_FAILURE);
}
}
// 假设这是一个巨大的模型层,例如优化器状态,大小为200GB
// H100的80GB HBM装不下,但系统总内存(DRAM + CXL)足够
const size_t large_tensor_size = 200 * 1024 * 1024 * 1024ULL;
int main() {
// 获取当前GPU设备
int device;
check_cuda_error(cudaGetDevice(&device));
// 1. 使用cudaMallocManaged分配超大张量
// 该内存将在CPU和GPU之间共享
void* managed_ptr;
check_cuda_error(cudaMallocManaged(&managed_ptr, large_tensor_size));
// 2. (关键步骤) 使用内存策略提示(Memory Advise)
// 告诉CUDA驱动,这个张量主要由GPU访问,并且它的首选位置是GPU设备
// 同时,将其初始CPU关联设置到CXL NUMA节点上,让不活跃的数据停留在CXL内存中
check_cuda_error(cudaMemAdvise(managed_ptr, large_tensor_size, cudaMemAdviseSetPreferredLocation, device));
check_cuda_error(cudaMemAdvise(managed_ptr, large_tensor_size, cudaMemAdviseSetAccessedBy, device));
std::cout << "Successfully allocated 200GB of managed memory." << std::endl;
// ... 在这里执行模型的训练或推理循环 ...
// CUDA驱动会按需将managed_ptr指向的内存页面从CXL内存(经由CPU)移动到H100的HBM中
// 3. 释放内存
check_cuda_error(cudaFree(managed_ptr));
return 0;
}优点
对应用程序透明,开发简单
缺点
性能依赖于CUDA驱动和OS的自动页面迁移策略,可能不是最优的。数据迁移路径为 CXL -> CPU -> PCIe -> GPU,延迟较高
方案二:基于CUDA内存池API的显式管理方案(前瞻性)
此方案更为复杂,但提供了最大的控制力和潜在性能。它假设未来NVIDIA驱动能将CXL内存区域封装成一个CUDA内存池。
核心思想
应用开发者显式地将数据划分为"热数据"和"冷数据"。热数据直接在HBM(T0)上分配,冷数据(如完整的优化器状态)则从代表CXL内存(T1)的特定内存池中分配。应用在需要时,通过CUDA流异步地在两个内存池之间拷贝数据。
实现步骤与伪代码示例
#include <cuda.h>
#include <iostream>
// 伪API: 用于获取与CXL设备关联的CUDA内存池
// 实际实现可能更复杂,需要设备ID等参数
CUresult getCxlMemoryPool(CUmemoryPool* pool, int cxl_device_id);
void check_cu_result(CUresult res) {
if (res != CUDA_SUCCESS) {
const char* err_str;
cuGetErrorString(res, &err_str);
std::cerr << "CUDA Driver API Error: " << err_str << std::endl;
exit(EXIT_FAILURE);
}
}
int main() {
cuInit(0);
CUdevice device;
CUcontext context;
check_cu_result(cuDeviceGet(&device, 0));
check_cu_result(cuCtxCreate(&context, 0, device));
// 1. 获取CXL内存池句柄 (假设性API调用)
CUmemoryPool cxl_pool;
// 假设系统中ID为0的CXL设备是我们想要的
check_cu_result(getCxlMemoryPool(&cxl_pool, 0));
std::cout << "Obtained handle to CXL memory pool." << std::endl;
// 2. 在CXL内存池中为"冷数据"分配空间
// 例如,一个庞大的Adam优化器状态(FP32参数、动量、方差)
size_t optimizer_states_size = 300 * 1024 * 1024 * 1024ULL; // 300GB
CUdeviceptr d_optimizer_states_cxl;
CUstream stream;
check_cu_result(cuStreamCreate(&stream, CU_STREAM_DEFAULT));
// 从CXL池中异步分配
check_cu_result(cuMemAllocFromPoolAsync(&d_optimizer_states_cxl, optimizer_states_size, cxl_pool, stream));
std::cout << "Allocated 300GB for optimizer states in CXL pool." << std::endl;
// 3. 在GPU本地HBM上为"热数据"分配空间
// 例如,当前需要更新的一小部分模型参数及其优化器状态
size_t working_set_size = 2 * 1024 * 1024 * 1024ULL; // 2GB
CUdeviceptr d_working_set_hbm;
check_cu_result(cuMemAlloc(&d_working_set_hbm, working_set_size));
std::cout << "Allocated 2GB for working set in HBM." << std::endl;
// --- 训练循环 ---
// for (auto& layer : model_layers) {
// // 4. 显式地将下一层所需的优化器状态从CXL内存异步拷贝到HBM工作区
// // 这是此方案的核心:由程序员精准控制数据移动
// CUdeviceptr src_ptr_in_cxl = d_optimizer_states_cxl + layer.offset;
// check_cu_result(cuMemcpyDtoDAsync(d_working_set_hbm, src_ptr_in_cxl, layer.size, stream));
//
// // ... 在HBM上执行计算(梯度更新等) ...
// // update_kernel<<<..., stream>>>(d_working_set_hbm, ...);
//
// // 5. 将更新后的优化器状态异步地写回CXL内存
// check_cu_result(cuMemcpyDtoDAsync(src_ptr_in_cxl, d_working_set_hbm, layer.size, stream));
// }
check_cu_result(cuStreamSynchronize(stream));
// 6. 释放内存
check_cu_result(cuMemFreeAsync(d_optimizer_states_cxl, stream));
check_cu_result(cuMemFree(d_working_set_hbm));
check_cu_result(cuStreamDestroy(stream));
cuCtxDestroy(context);
return 0;
}优点
提供了精细的控制粒度,开发者可以根据算法特性设计最优的数据移动策略,最大化隐藏数据传输延迟,有望实现最高性能
缺点
实现复杂,对应用代码侵入性强,需要开发者对模型的数据访问模式有深刻理解。严重依赖未来硬件和驱动的支持
性能提升分析
大模型训练
突破单卡容量限制
最直接的好处是能够训练参数量远超H100 HBM容量的单个大模型,而无需诉诸于复杂且昂贵的多节点分布式训练
优化ZeRO-Offload性能
相较于将数据卸载到CPU主存,卸载到CXL内存将显著降低数据传输的延迟。这能有效减少训练步骤中的"气泡"时间
容错与快速恢复
CXL内存可以是持久性的(CXL-PNM),可以将关键的优化器状态等保存在持久内存中,在训练任务失败时实现秒级恢复
大模型推理
支持更大模型的单GPU部署
允许将一个数百GB的巨型模型完整加载到 HBM + CXL内存 的统一地址空间中,从而在单块H100上提供推理服务
提升多模型服务吞吐量
在多租户或多模型服务场景下,可以在CXL内存中同时存放多个模型的权重。当请求到来时,只需将目标模型的权重快速从CXL内存换入HBM
降低推理延迟
对于超出HBM容量的模型,推理时需要从外部存储动态加载部分权重。CXL内存的低延迟特性将使这种"权重流式加载"过程比从NVMe SSD加载快得多
性能权衡与挑战
尽管前景广阔,但该方案仍面临挑战:
- 性能分层:CXL内存的带宽和延迟终究劣于HBM3。因此,协同工作的核心挑战在于设计高效的数据放置和迁移策略,确保最热的数据始终在HBM中
- 软件生态成熟度:从操作系统、虚拟化管理程序到NVIDIA驱动和CUDA编程模型,整个软件栈都需要进行深度适配和优化,才能充分发挥CXL的潜力
- 硬件依赖:方案的最终性能和可行性,特别是高性能的"方案二",完全取决于未来CPU、GPU和CXL设备对相关标准和直接通信协议的支持程度
结论与展望
CXL内存池技术为解决AI大模型带来的"内存墙"问题提供了一条极具吸引力的路径。通过与NVIDIA H100等顶级GPU的HBM显存构建分层内存体系,可以在不牺牲过多性能的前提下,将GPU可访问的内存容量扩展一个数量级以上。
本研究报告的分析表明,尽管当前NVIDIA官方尚未提供H100对CXL内存池的直接支持方案,但基于现有的CUDA统一内存和操作系统NUMA机制,已经可以构建出 透明的、对应用友好的协同方案(方案一) 。更进一步,我们展望了 一种基于CUDA内存池API的显式管理方案(方案二) ,它虽然需要未来的硬件和软件支持,但代表了获取极致性能和控制力的发展方向。
展望未来,随着CXL生态系统的不断成熟和硬件厂商(包括NVIDIA)的持续投入,我们有理由相信,CXL内存池与GPU的深度、原生融合将成为下一代AI计算平台的标准配置。这将彻底改变我们设计、训练和部署超大规模模型的方式,推动人工智能向着更广阔的领域迈进。


