LangChain 介绍
随着各种开源大模型的发布,越来越多的人开始尝试接触和使用大模型。在感叹大模型带来的惊人表现的同时,也发现一些问题,比如没法查询到最新的信息,有时候问一些数学问题时候,会出现错误答案,还有一些专业领域类问题甚至编造回答等等。有没有什么办法能解决这些问题呢?答案就是LangChain。

LangChain 是一个开源的语言模型集成框架,旨在简化使用大型语言模型(LLM)创建应用程序的过程。利用它可以让开发者使用语言模型来实现各种复杂的任务,例如文本到图像的生成、文档问答、聊天机器人、调用特定的SaaS服务等等。随着ChatGPT、midjourney等AI技术的爆火,LangChain也是在短时间内得到6w+的star数,版本迭代也是异常的快,社区十分活跃。
LangChain 在没有任何收入也没有任何明显的创收计划的情况下,获得了 1000 万美元的种子轮融资和 2000-2500 万美元的 A 轮融资,估值达到 2 亿美元左右。
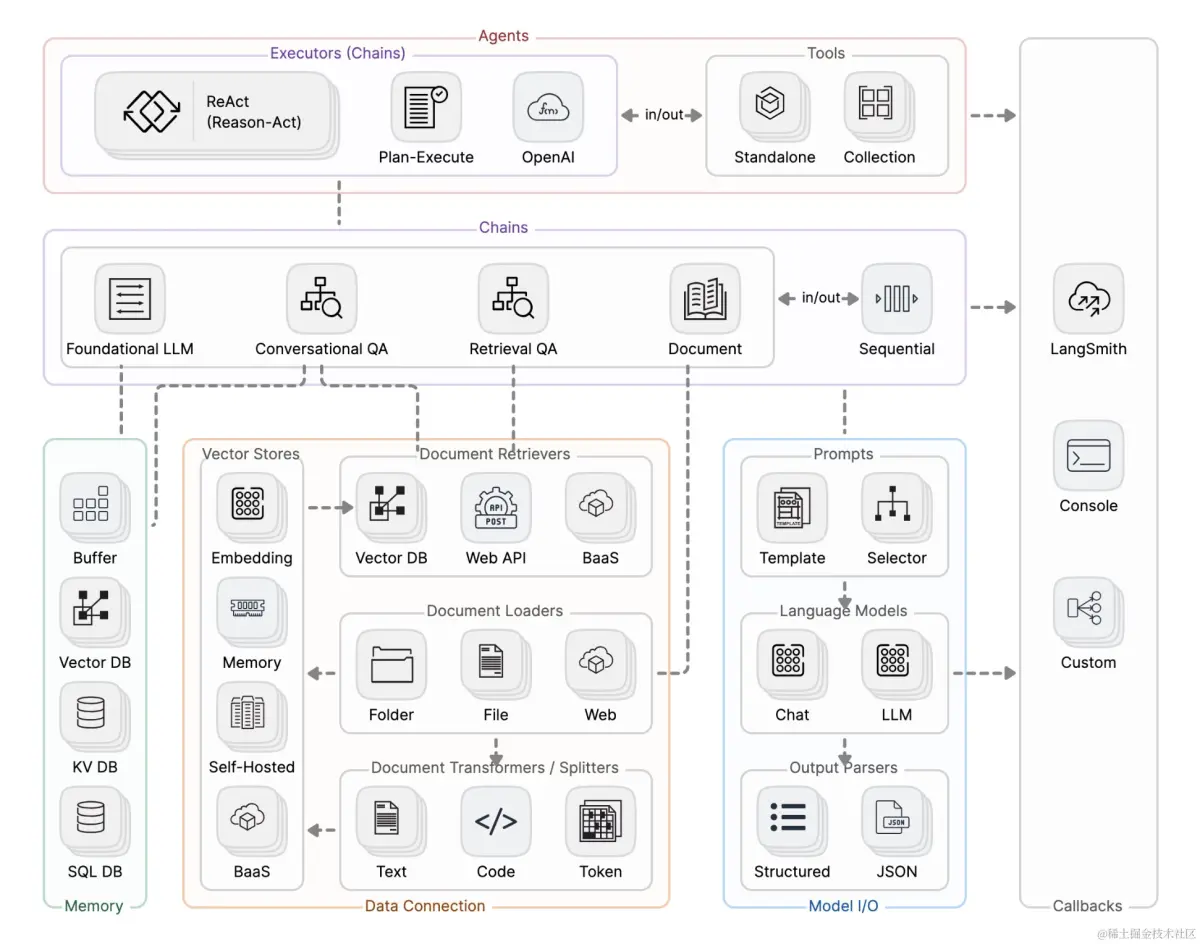
LangChain架构图
上面是LangChain的核心架构图,可以看到LangChain主要包含如下模块:
- Model I/O:大模型的输入输出,包含提示词、任何大模型、结果解析器。
- Retrieval:涉及到数据集相关,主要包含文档提取器、文档转换器、向量数据库等。
- Chains:允许将多个不同组件组合在一起使用,形成链条式调用。
- Memory:在大模型调用期间提供存储能力。
- Agents:链式调用是硬编码的,而代理是由大模型根据实时情况来决定如何调用工具。
- Callbacks:大模型各个阶段的的回调系统,对于日志记录、监控、流传输和其他任务非常有用。
Agent
大模型一般只拥有他们被训练的知识,这种知识可能很快就会过时了,所以在推理的时候大模型与外界是处于“断开”状态。为了克服这一限制,LangChain在Yao等人在2022年11月提出的推理和行动(ReAct)框架上提出了“代理”(Agent)的解决方案。此方案可以获取最新的数据,并将其作为上下文插入到提示中。Agent也可以用来采取行动(例如,运行代码,修改文件等),然后该行动的结果可以被LLM观察到,并被纳入他们关于下一步行动的决定。
运行大体流程: 1用户给出一个任务(Prompt) -> 2思考(Thought) -> 3行动(Action) -> 4观察(Observation),
然后循环执行上述 2-4 的流程,直到大模型认为找到最终答案为止。
Agent内部具体拆解:
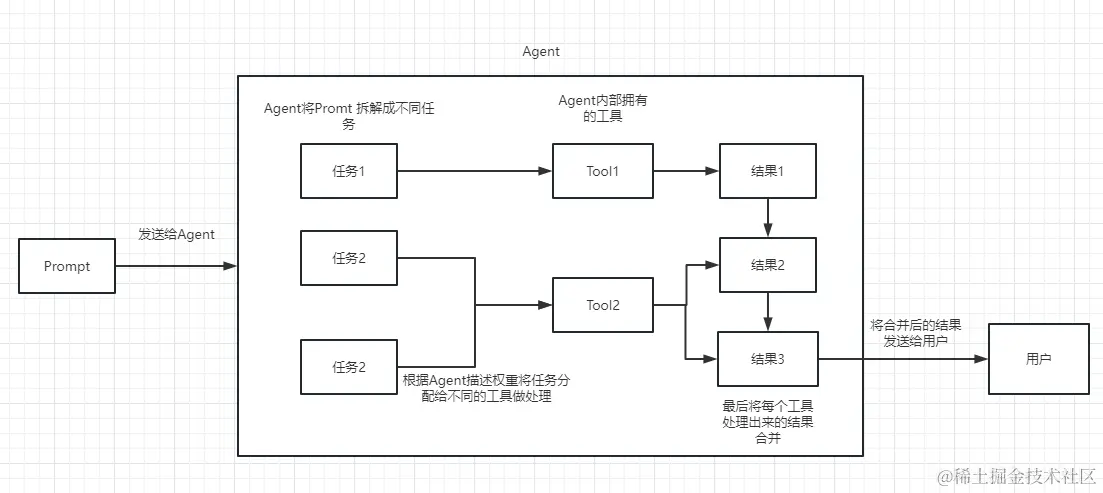
Agent结构图
使用Agent有两个必备条件:相关能力工具和对这些工具的正确描述。
定义工具
工具的定义只需要集成BaseTool类,然后在_run方法中编写你的逻辑就行,大模型会把合适的参数传进来。
需要定义类变量有:
- name: 工具名称,很重要,大模型内部会使用到
- description:工具描述,很重要,告知大模型在什么情况下来使用这个工具
- return\_direct:这个字段默认为false,如果设置为true,工具返回结果后,大模型就不再循环思考了会直接将这个结果当做答案。
LangChain 已经内置了 duckduckgo 搜索引擎,pip install duckduckgo-search安装一下依赖包即可使用,只是需要科学上网才能调通。
下面是我定义的两个工具,一个用于电影搜索,一个用于数学计算:
from langchain.tools import BaseTool, DuckDuckGoSearchRun
# 搜索工具
class SearchTool(BaseTool):
name = "Search"
description = "当问电影相关问题时候,使用这个工具"
return_direct = False # 直接返回结果
def _run(self, query: str) -> str:
print("\n正在调用搜索引擎执行查询: " + query)
search = DuckDuckGoSearchRun()
return search.run(query)
# 计算工具
class CalculatorTool(BaseTool):
name = "Calculator"
description = "如果问数学相关问题时,使用这个工具"
return_direct = False # 直接返回结果
def _run(self, query: str) -> str:
return eval(query)定义结果解析类
每次大模型输出之后,都会对结果进行解析,如果找到action就会去调用。但是默认的解析类我测试的时候总报错,所以我改写了一下:
from typing import Dict, Union, Any, List
from langchain.output_parsers.json import parse_json_markdown
from langchain.agents.conversational_chat.prompt import FORMAT_INSTRUCTIONS
from langchain.agents import AgentExecutor, AgentOutputParser
from langchain.schema import AgentAction, AgentFinish
# 自定义解析类
class CustomOutputParser(AgentOutputParser):
def get_format_instructions(self) -> str:
return FORMAT_INSTRUCTIONS
def parse(self, text: str) -> Union[AgentAction, AgentFinish]:
print(text)
cleaned_output = text.strip()
# 定义匹配正则
action_pattern = r'"action":\s*"([^"]*)"'
action_input_pattern = r'"action_input":\s*"([^"]*)"'
# 提取出匹配到的action值
action = re.search(action_pattern, cleaned_output)
action_input = re.search(action_input_pattern, cleaned_output)
if action:
action_value = action.group(1)
if action_input:
action_input_value = action_input.group(1)
# 如果遇到'Final Answer',则判断为本次提问的最终答案了
if action_value and action_input_value:
if action_value == "Final Answer":
return AgentFinish({"output": action_input_value}, text)
else:
return AgentAction(action_value, action_input_value, text)
# 如果声明的正则未匹配到,则用json格式进行匹配
response = parse_json_markdown(text)
action_value = response["action"]
action_input_value = response["action_input"]
if action_value == "Final Answer":
return AgentFinish({"output": action_input_value}, text)
else:
return AgentAction(action_value, action_input_value, text)
output_parser = CustomOutputParser()初始化Agent
如果你使用ChatGPT的话,这里需要配置ChatGPT的api-key,同时需要科学上网。也可以配置一些本地的开源大模型,比如ChatGLM2-6B、Baichuan-13B等,但是效果确实要比ChatGPT差很多。
from langchain.memory import ConversationBufferMemory
from langchain.agents.conversational_chat.base import ConversationalChatAgent
from langchain.agents import AgentExecutor, AgentOutputParser
SYSTEM_MESSAGE_PREFIX = """尽可能用中文回答以下问题。您可以使用以下工具"""
# 初始化大模型实例,可以是本地部署的,也可是是ChatGPT
# llm = ChatGLM(endpoint_url="http://你本地的实例地址")
llm = ChatOpenAI(openai_api_key="sk-xxx", model_name='gpt-3.5-turbo', request_timeout=60)
# 初始化工具
tools = [CalculatorTool(), SearchTool()]
# 初始化对话存储,保存上下文
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
# 配置agent
chat_agent = ConversationalChatAgent.from_llm_and_tools(
system_message=SYSTEM_MESSAGE_PREFIX, # 指定提示词前缀
llm=llm, tools=tools, memory=memory,
verbose=True, # 是否打印调试日志,方便查看每个环节执行情况
output_parser=output_parser #
)
agent = AgentExecutor.from_agent_and_tools(
agent=chat_agent, tools=tools, memory=memory, verbose=True,
max_iterations=3 # 设置大模型循环最大次数,防止无限循环
)
调用Agent
调用就很简单了,执行agent.run(prompt)即可,下面是一个详细的调用日志输出:
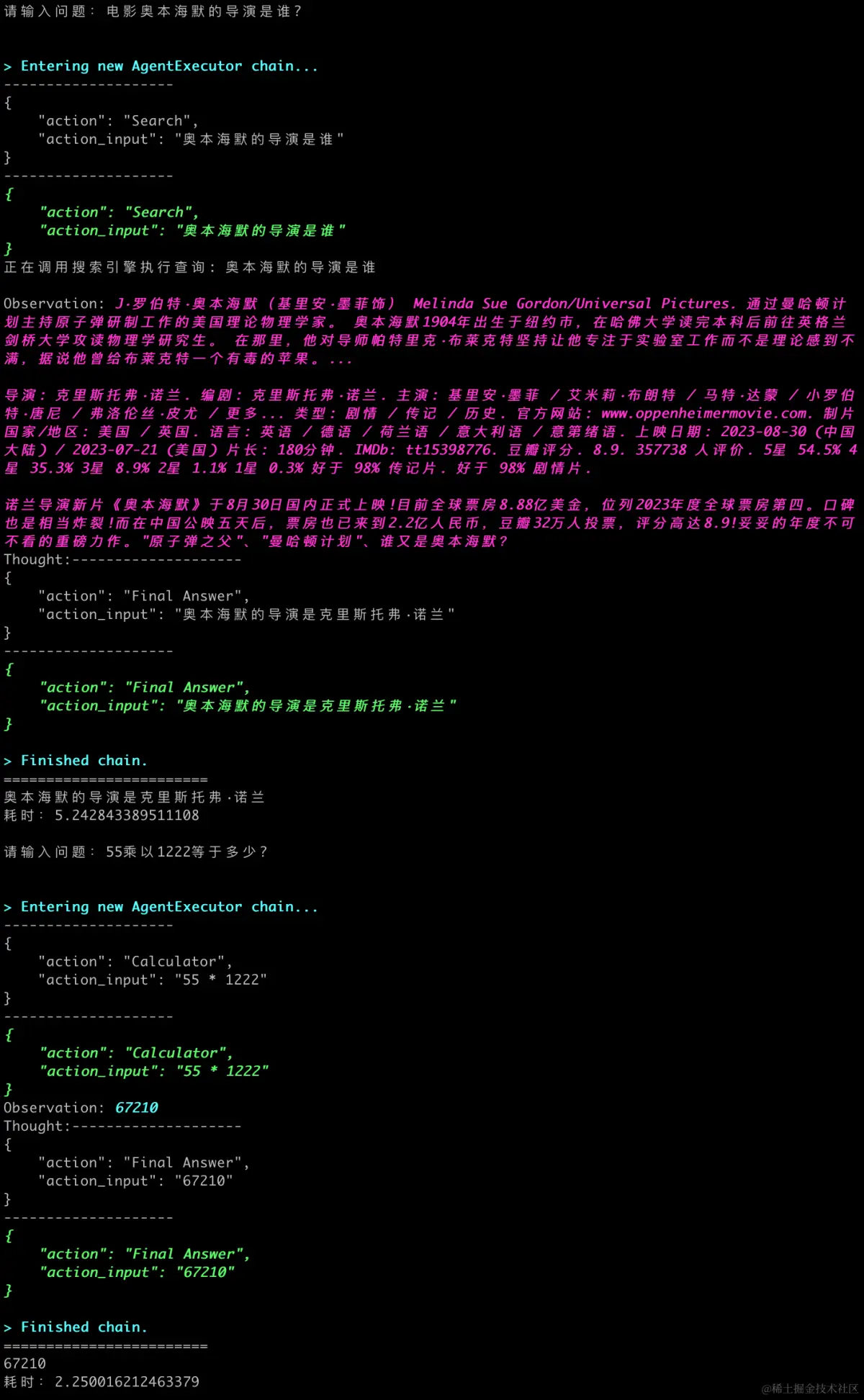
执行结果
日志已经完整的体现出了整个流程,大模型的确每次都匹配到了正确的tool。如果还觉得日志不详细,可以设置langchain.debug = True,这样会打印更详细日志。
总结
可以这么理解Agent,它让大模型变成了一个决策者。用户的问题首先由它去理解和拆分,它来从工具列表中找到觉得合适的工具,然后将用户的提问信息转化成结构化的数据,当成参数传递给工具函数。工具函数返回结果又交还给了大模型去观察分析,如果它觉得不是正确答案,那么继续这个循环直到得出它认为的正确答案。
它就像是一个优秀的项目经理,分解用户的问题,可能他不擅长完成某一项任务,但是他能找到合适专业的外部的人去完成子任务,最后他再汇总任务结果交付给用户。
优点
- 框架层上来说,对大模型的有更系统化的干预机制,方便集成。
- 拓展了大模型更多的能力,而且是不需要经过复杂且昂贵的训练过程。
- 不用再去写那些匹配场景的规则了,大模型已经帮你做了,前提是这个模型参数要够大,能理解用户的意思。
- 整个流程都有详细的记录日志,方便调试。
不足
- 大模型会被多次调用,响应用户的时间可能会比较久,因此相应产品也就会限制在一些特定领域。
- 虽然不用写工具匹配规则,但是这也让这一块逻辑变成一个黑盒了,很难去精准的匹配或者调试。
- 对大模型本身能力要求很高,如果使用低参数大模型,很有可能无法识别问题并正确的分发给对应工具。
当然还是有优化的方向的:比如可以考虑去使用语料专门往解析action方面训练,让模型能更好的解析出action。
引用链接:
作者:雨田君的记事本
链接:https://www.jianshu.com/p/f58ddfb88f95
来源:简书
