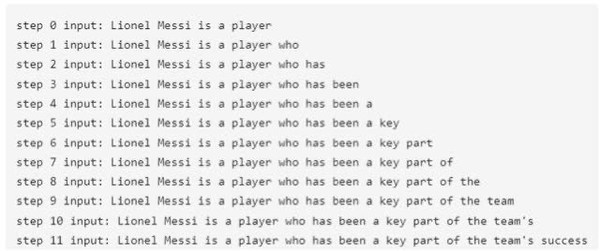
GPT推理token生成机制中的kvcache详解 Post Views: 991 一句话介绍 kvcache是一种以空间换时间的策略,能够加快语言模型的生成速度。 要明白kvcache,需要弄明清楚两个细节——GPT 的生成机制以及注意力掩码 (attention mask)。 GPT的生成机制 在介绍 kvcache之前,我们需要先了解生成式预训练模型(GPT)的生成机制。GPT 是泛指所有生成式语言模型,而非特指 OpenAI 的 GPT 产 AIGC admin 2024-10-30 968 热度 0评论
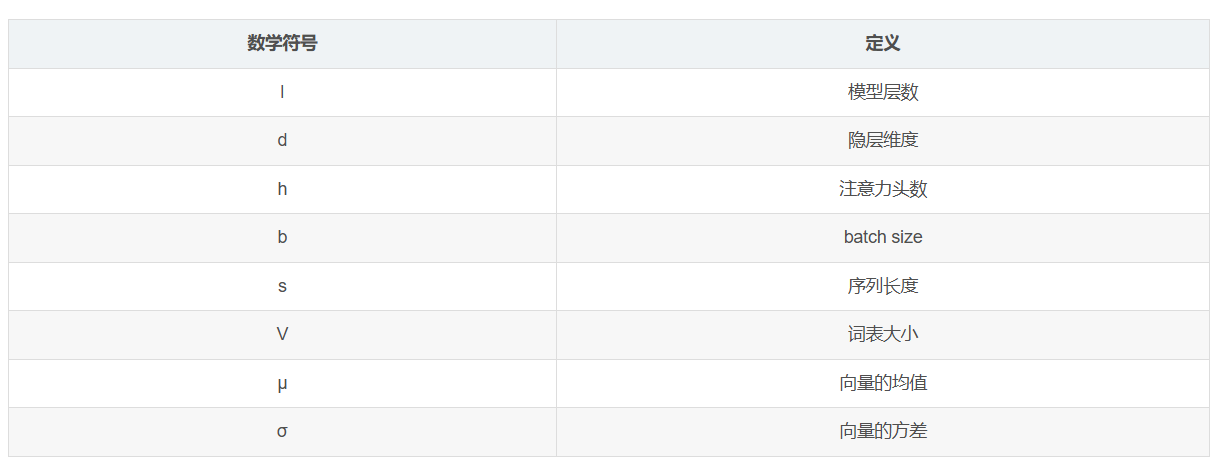
大模型训练显存分析 Post Views: 563 数据类型 float32(FP32):32 位浮点数,也称为单精度。 float16(FP16):16 位浮点数,表示范围较小,也被称为半精度。 bfloat16(BF16):扩大了指数位数,缩小了小数位数,因此表示的范围更大,精度更弱。 一般采用 16 位的表示,那么一个参数占用 2byte,即 2B。 FP16 的精度高,但是表示范围小,容易上溢; BF16 的 AIGC admin 2024-10-30 560 热度 0评论
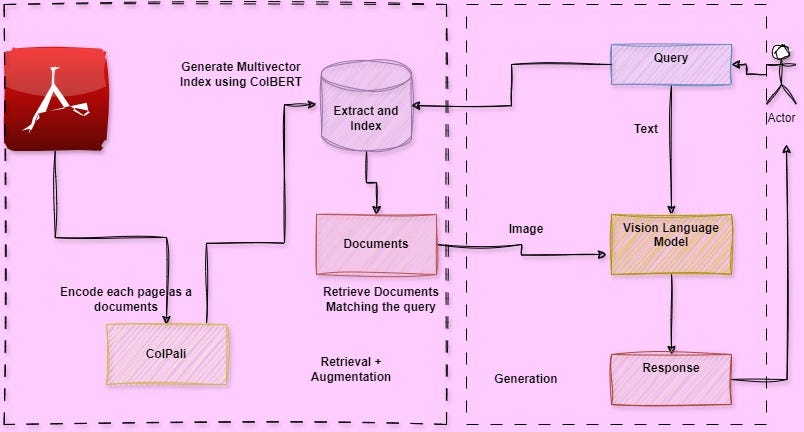
使用 ColPali 和视觉语言模型 Groq(Llava) 和 Qwen2-VL 实现多模态 RAG Post Views: 1,148 多模态 RAG 管道 介绍 在标准 RAG 中,输入文档由文本数据组成。LLM 利用上下文学习,通过检索与所提查询上下文相匹配的文本文档块来提供更相关、更准确的答案。 但是如果文档除了文本数据之外还包含图像、表格、图表等怎么办? 不同的文档格式 PDF(便携式文档格式):通常用于跨平台共享保留其格式的文档,但由于其布局非结构化,因此很难从中提取数据。 Micro AIGC admin 2024-10-24 1164 热度 0评论
基于多向量检索器的多模态RAG 实现 Post Views: 544 长话短说 下面三个 LangChain 示例代码,展示了如何使用 LangChain 多向量检索器(Multi-Vector Retriever)对多内容类型的文档实现更好的 RAG 效果。后面两个示例还涵盖了一些配合多模态 LLM 的多矢量检索器用法,以实现针对图像的 RAG。 半结构化数据 (tables + text) RAG 多模态 (text + tabl AIGC admin 2024-10-24 574 热度 0评论
DB-GPT应用部署测试 Post Views: 566 环境要求 启动模式 CPU * MEM GPU 备注 代理模型 4C*8G 代理模型不依赖GPU 本地模型 8C*32G 24G 本地启动最好有24G以上GPU conda环境安装 默认数据库使用SQLite,因此默认启动模式下,无需安装数据库。 如果需要使用其他数据库,可以看后面的高级教程。 我们推荐通过conda的虚拟环境来进行Python虚拟环境的安装。关于M AIGC admin 2024-10-24 602 热度 0评论
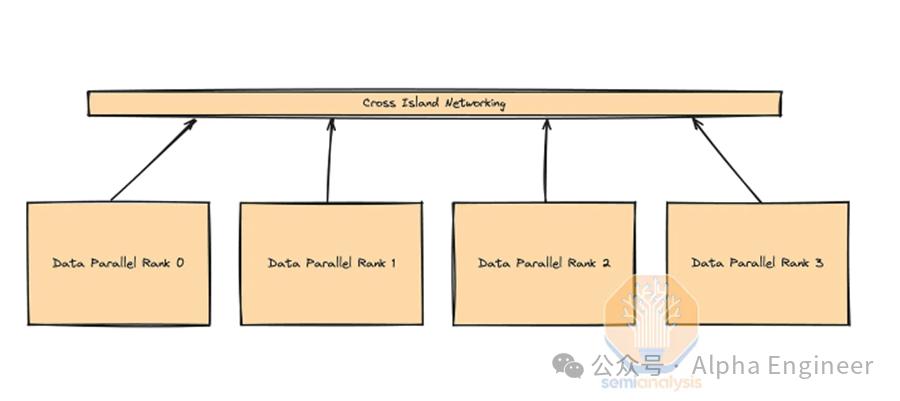
10万卡GPU集群背后的硬核技术详解 Post Views: 508 在当今人工智能和机器学习领域,大规模的计算能力是推动创新和突破的关键。而搭建一个拥有10万个H100 GPU的集群,极具挑战性。 这种规模集群能支持前所未有的模型训练和数据处理任务,对人工智能研究具有重要意义。 然而,搭建这样的集群并非易事,它涉及到电力供应、网络拓扑结构、并行化挑战、可靠性与恢复以及成本优化等。 NVIDIA H100 参数 • 内存:高达80GB AIGC admin 2024-10-18 532 热度 0评论
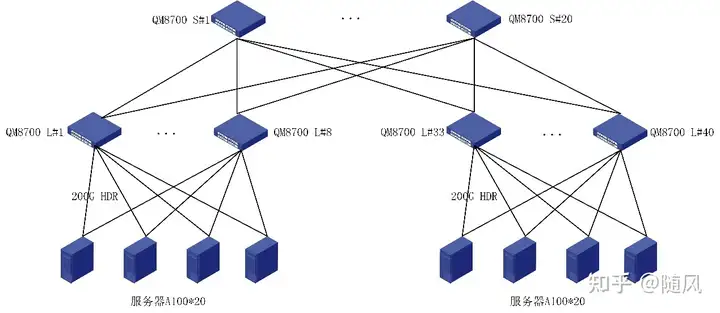
如何计算GPU集群中最大服务器数量 Post Views: 591 实践中最常用的GPU集群网络拓扑是胖树(Fat-Tree)无阻塞网络架构(无收敛设计),这是因为Fat-Tree架构易于拓展、路由简单、方便管理和运维,且成本相对较低。实践中,一般规模较小的GPU集群计算网络采用二层架构(Leaf-Spine),而规模较大的GPU集群计算网络采用三层架构(Leaf-Spine-Core)。这里 Leaf对应接入层(Access),S AIGC admin 2024-10-18 620 热度 0评论
数据中心网络架构演进 — CLOS 网络模型介绍 Post Views: 754 CLOS Networking 自从 1876 年电话被发明之后,电话交换网络历经了人工交换机、步进制交换机、纵横制交换机等多个阶段。20 世纪 50 年代,纵横制交换机处于鼎盛时期,纵横交换机的核心,是纵横连接器。 纵横制接线器 纵横连接器交叉点示意图 因为开关矩阵很像一块布的纤维,所以交换机的内部架构被称为 Switch Fabric(纤维),这是 Fabric AIGC admin 2024-10-16 756 热度 0评论
通向AGI的钥匙:100,000H100非常AI算率集群 Post Views: 578 自GPT-4发布以来,全球AI能力发展势头有所放缓。 但是这并不意味着Scaling Law失败,并非因为训练数据不足,而是因为它遇到了一个结实的算率瓶颈。 具体来说,GPT-练习算率约为2e25。 FLOP,最近发布的GoogleGeminini等几个大型模型 Ultra、Nvidia Nemotron 340B、还有Meta Llama3 在405B背后使用的练 AIGC admin 2024-10-16 596 热度 0评论
100B参数开源大模型 BLOOM实现技术分析 Post Views: 548 假设你现在有了数据,也搞到了预算,一切就绪,准备开始训练一个大模型,一显身手了,“一朝看尽长安花”似乎近在眼前 …… 且慢!训练可不仅仅像这两个字的发音那么简单,看看 BLOOM 的训练或许对你有帮助。 近年来,语言模型越训越大已成为常态。大家通常会诟病这些大模型本身的信息未被公开以供研究,但很少关注大模型训练技术这种背后的知识。本文旨在以 1760 亿参数的语言模 AIGC admin 2024-10-16 561 热度 0评论