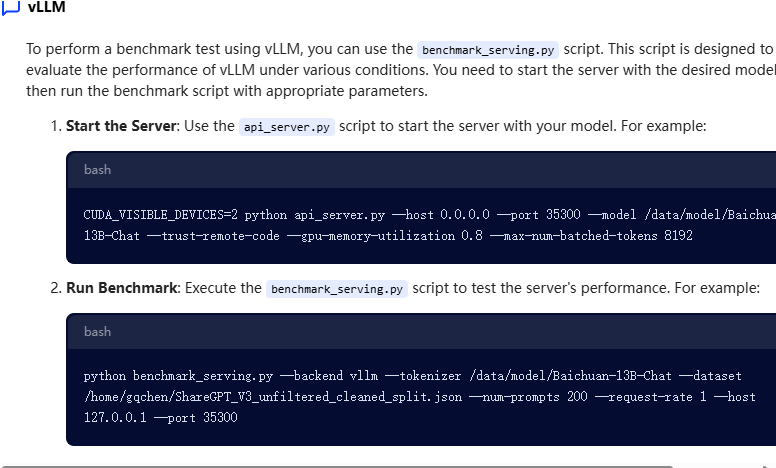
vLLM部署大模型的基准测试 Post Views: 712 官方文档:Benchmark Suites — vLLM github官网项目:https://github.com/vllm-project/vllm 硬件状况:4张4090的24G的卡 咨询vllm官网的AI 问:如何完成基准测试 答:如下图所示 下载测试数据集 下载python测试脚本 如下是脚本的部分内容,全部代码过长无法粘贴(后面我选择了拉取整个vllm项 AIGC admin 2025-02-27 760 热度 0评论
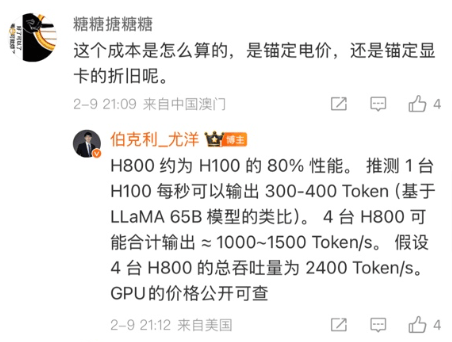
DeepSeek-R1满血版推理部署和优化 Post Views: 794 前情回顾 比较现实的是两个极端, 一方面是各种平台的测评, 例如公众号“ CLUE中文语言理解测评基准”的 另一方面是尤洋老师在微博的一个评论MaaS的商业模式和平台推理亏损, 这里提到了4台H800的总吞吐量 另一方面是各种私有化部署的需求, 例如小红书上最近经常刷到 还有章明星老师的KTransformer可以在单卡的4090 24GB上配合Intel CPU的 大模型 admin 2025-02-27 811 热度 0评论
vLLM 0.6.0推理框架性能优化 Post Views: 498 简介 在此前的大模型技术实践中,我们介绍了加速并行框架Accelerate、DeepSpeed及Megatron-LM。得益于这些框架的助力,大模型的分布式训练得以化繁为简。 然而,企业又该如何将训练完成的模型实际应用部署,持续优化服务吞吐性能?我们不仅要考量模型底层的推理效率,还需从请求处理的调度策略上着手,确保每一环节都能发挥出最佳效能。 本期内容,优刻得将为大 大模型 admin 2025-02-27 498 热度 0评论
vLLM推理框架本地benchmark测试 Post Views: 705 vllm环境搭建:略 本地硬件环境:RTX4090 24G显存 CUDA12.4 多卡 测试命令单卡张量并行: (vllm_python_source) zxj@zxj:~/zxj/vllm/benchmarks$ python benchmark_throughput.py --backend vllm --input-len 128 --output-len 5 大模型 admin 2025-02-27 757 热度 0评论
大模型之推理 – 容量估算 Post Views: 634 LLM之推理成本高主要原因在于: •模型自身复杂性:模型参数规模大,对计算和内存的需求增加 •自回归解码:逐token进行,速度太慢 推理加速一般可以从两个层面体现:延迟与吞吐量 •延迟 (Latency) :主要从用户的视角来看,从提交一个prompt,至返回response的响应时间,衡量指标为生成单个token的速度,如16 ms/token;若batch_s AIGC admin 2025-02-27 682 热度 0评论